这篇文章主要介绍“怎么诊断sql中library cache: mutex X等待”,在日常操作中,相信很多人在怎么诊断SQL中library cache: mutex X等待问题上存在疑惑,小编查阅了各式
这篇文章主要介绍“怎么诊断sql中library cache: mutex X等待”,在日常操作中,相信很多人在怎么诊断SQL中library cache: mutex X等待问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”怎么诊断SQL中library cache: mutex X等待”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
该机制是用于保护内存结构,在 library cache 中有许多内存结构需要 library cache: mutex X 的保护。
library cache 用来保存解析过的 cursor 相关的内存结构。
等待 library cache: mutex X 与之前版本的 latch:library cache 等待相同。library cache: mutex X 可以被很多因素引起,例如:(包括应用问题,执行计划不能共享导致的高版本的游标等),本质上都是某个进程持有 library cache: mutex X 太长时间,导致后续的进程必须等待该资源。如果在 library cache 的 latch 或者 mutex 上有等待,说明解析时有很大的压力,解析 SQL 的时间变长(由于 library cache 的 latch 或者 mutex 的等待)会使整个数据库的性能下降。
由于引起 library cache: mutex X 的原因多种多样,因此找到引起问题的根本原因很重要,才能使用正确的解决方案。
*大量的硬解析:过于频繁的硬解析,会导致该等待。
*高版本的游标:当发生 High version count 时,大量的子游标需要检索,从而会引起该等待。
*游标失效:游标失效是指,保存在 library cache 中的游标由于不可用,而从 library cache 中删除。游标失效是指某些改变导致内存中的游标不再有效。例如:游标相关对象的统计信息搜集;游标关联表,视图等对象的修改等。发生游标失效会导致接下来的进程需要重新载入该游标。当游标失效过多时,会导致 ‘library cache: mutex X’ 等待。
*游标重新载入:游标重新载入是指本来已经存在于 library cache 中,但是当再次查找时已经被移出 library cache(例如:由于内存压力),这时就需要重新解析并且载入该游标。游标重新载入操作不是一件好事,它表明您正在做一件本来不需要做的事情,如果您设置的 library cache 大小适当,是可以避免游标重新载入的。游标重新载入的时候是不可以被进程使用的,这种情况会导致 library cache: mutex X 等待。
*已知的 Bug。
library cache: mutex X – 用于保护 handle。
library cache: bucket mutex X – 用于保护 library cache 中的 hash buckets。
library cache: dependency mutex X – 用于保护依赖。
该等待的出现的趋势:
a. 确认该等待是否在每天的固定时刻产生?
b. 是否做了一些操作触发该等待?
生成问题发生时刻的 AWR 和 ADDM 报告,与基线或者正常时间段的 AWR 和 ADDM 报告比较,是否有负载,参数等的改变和不同。
有时使用systemstate dump 可以用来匹配已知的问题,例如:在 AWR 中没有发现明显的 SQL 时、通过 systemstate dump 捕获阻塞进程和被阻塞进程的信息,可帮助发现潜在的问题。
当systemstate dump 不适合收集时(因为它消耗资源较多)。这时定期执行如下 SQL,来确定哪些进程和 SQL 在等待 library cache: mutex X。
select s.sid, t.sql_text
from vvsql t
where s.event like ‘%mutex%’
and t.sql_id = s.sql_id
正常情况下,我们可以从 AWR 中看到 library cache: mutex X 是 TOP 事件: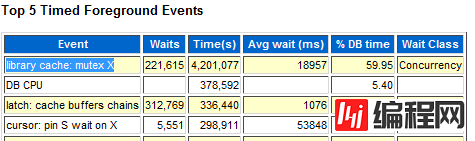
定位出硬解析和高版本的 SQL,点击“Main Report”下的“SQL Statistics”链接
定位解析比较高的 SQL: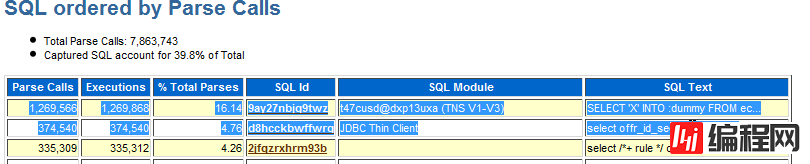
注意比较高的解析比例的 SQL,理想情况下解析和执行的比例应该很低,如果该比例很高说明应用中没有很好的使用游标,游标解析并且打开之后应该保持打开状态,与开发人员确认如何保持游标打开,避免下次执行该 SQL 时重复解析。
下一步检查 SQL 高版本: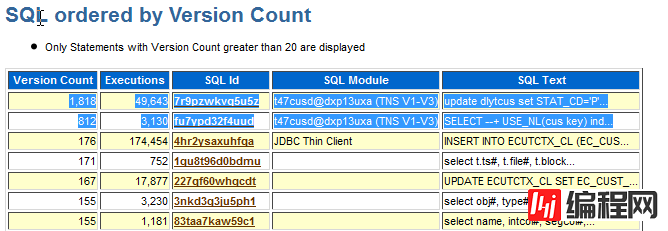
检查是否存在较高的硬解析,因为硬解析会引起 SQL AREA 的重新装载,通过 load profile 确定硬解析的数量。
2.对于 SQL AREA 的重新加载也要进行检查: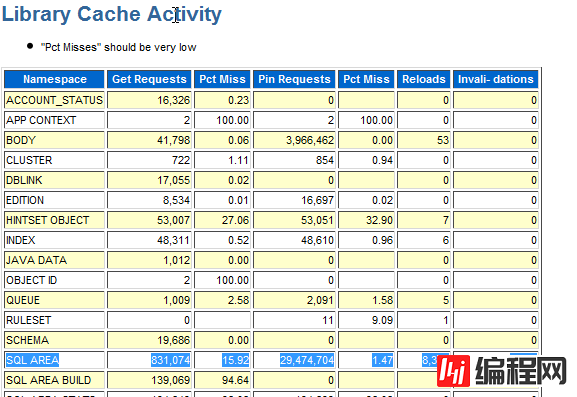
如果在 SQL AREA 上的重新加载次数很高,那么需要检查游标是否被有效共享(重新加载的次数是指被缓存在 shared pool 中,但是使用时已经不在 shared pool 中)。如果游标已经有效共享,那么需要确认 shared pool 和 sga_target 是否足够大,如果 shared pool 有压力而没有足够的空间,那么有些缓存的游标会被从 shared pool 中清除。如果游标共享不充分,shared pool 会被这些不能被重用的游标占满,从而把那些可以重用的游标挤出 shared pool,进而引起在这些 SQL 重新执行时需要重新加载。游标共享充分,但由于 shared pool 空间过小也会引起可重用的游标被清除从而引发硬解析。
在“Library Cache Activity”下检查 invalidations,如果 invalidations 过高,需要确认是否有大量的 DDL 操作,例如: truncate, drop, grants, dbms_stats 等
4.对于 11G,确认 cursor_sharing 不是 similar,因为该值已经不建议使用,并且会引起 mutex X 等待
到此,关于“怎么诊断SQL中library cache: mutex X等待”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注编程网网站,小编会继续努力为大家带来更多实用的文章!
--结束END--
本文标题: 怎么诊断SQL中library cache: mutex X等待
本文链接: https://lsjlt.com/news/62993.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0