本篇内容介绍了“怎么优化模糊匹配Like %xxx%”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!索引条件
本篇内容介绍了“怎么优化模糊匹配Like %xxx%”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
索引条件下推ICP
ICP介绍
Mysql 5.6开始支持ICP(Index Condition Pushdown),不支持ICP之前,当进行索引查询时,首先根据索引来查找数据,然后再根据where条件来过滤,扫描了大量不必要的数据,增加了数据库IO操作。
在支持ICP后,mysql在取出索引数据的同时,判断是否可以进行where条件过滤,将where的部分过滤操作放在存储引擎层提前过滤掉不必要的数据,减少了不必要数据被扫描带来的IO开销。
在某些查询下,可以减少Server层对存储引擎层数据的读取,从而提供数据库的整体性能。
ICP具有以下特点
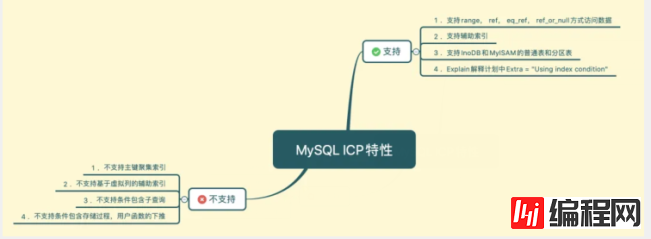
ICP相关控制参数
index_condition_pushdown:索引条件下推默认开启,设置为off关闭ICP特性。
mysql>show variables like 'optimizer_switch'; | optimizer_switch | index_condition_pushdown=on # 开启或者关闭ICP特性 mysql>set optimizer_switch = 'index_condition_pushdown=on | off';ICP处理过程
假设有用户表users01(id, name, nickname, phone, create_time),表中数据有11W。由于ICP只能用于二级索引,故在name,nickname列上创建复合索引idx_name_nickname(name,nickname),分析SQL语句select * from users01 where name = 'Lyn' and nickname like '%SK%'在ICP关闭和开启下的执行情况。
关闭ICP特性的SQL性能分析
开启profiling进行跟踪SQL执行期间每个阶段的资源使用情况。
mysql>set profiling = 1;关闭ICP特性分析SQL执行情况
mysql>set optimizer_switch = 'index_condition_pushdown=off';
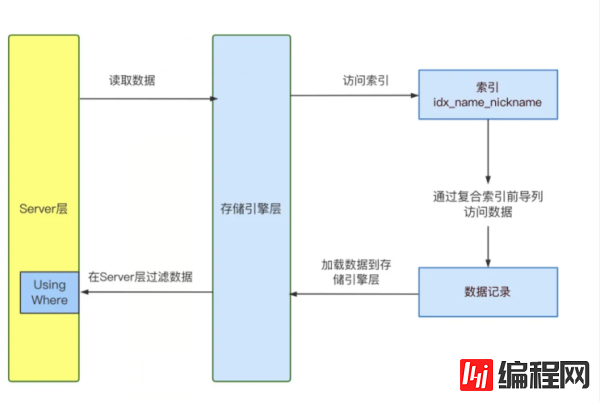
mysql>explain select * from users01 where name = 'Lyn' and nickname like '%SK%'; | 1 | SIMPLE | users01 | NULL | ref | idx_name_nickname | idx_name_nickname | 82 | const | 29016 | 100.00 | Using where | #查看SQL执行期间各阶段的资源使用 mysql>show profile cpu,block io for query 2; | Status | Duration | CPU_user | CPU_system | Block_ops_in | Block_ops_out | +--------------------------------+----------+----------+------------+--------------+---------------+ | starting | 0.000065 | 0.000057 | 0.000009 | 0 | 0 | .................. | executing | 0.035773 | 0.034644 | 0.000942 | 0 | 0 |#执行阶段耗时0.035773秒。 | end | 0.000015 | 0.000006 | 0.000009 | 0 | 0 | #status状态变量分析 | Handler_read_next | 16384 | ##请求读的行数 | Innodb_data_reads | 2989 | #数据物理读的总数 | Innodb_pages_read | 2836 | #逻辑读的总数 | Last_query_cost | 8580.324460 | #SQL语句的成本COST,主要包括IO_COST和CPU_COST。通过explain分析执行计划,SQL语句在关闭CP特性的情况下,走的是复合索引idx_name_nickname,Extra=Using Where,首先通过复合索引 idx_name_nickname 前缀从存储引擎中读出 name = 'Lyn' 的所有记录,然后在Server端用where 过滤 nickname like '%SK%' 情况。
Handler_read_next=16384说明扫描了16384行的数据,SQL实际返回只有12行数,耗时50ms。对于这种扫描大量数据行,只返回少量数据的SQL,可以从两个方面去分析。
1.索引选择率低:对于符合索引(name,nickname),name作为前导列出现 where 条件,CBO都会选择走索引,因为扫描索引比全表扫描的COST要小,但由于 name 列的基数不高,导致扫描了索引中大量的数据,导致SQL性能也不太高。
Column_name: name Cardinality: 6 可以看到users01表中name的不同的值只有6个,选择率6/114688很低。
2.数据分布不均匀:对于where name = ?来说,name数据分布不均匀时,SQL第一次传入的值返回结果集很小,CBO就会选择走索引,同时将SQL的执行计划缓存起来,以后不管name传入任何值都会走索引扫描,这其实是不对的,如果传入name的值是Fly100返回表中80%的数据,这是走全表扫描更快。
| name | count(*) | +---------------+----------+ | Grubby | 12 | | Lyn | 1000 | | Fly100 | 98100 |在MySQL 8.0推出了列的直方图统计信息特性,主要针对索引列数据分布不均匀的情况进行优化。
开启ICP特性的性能分析
开启ICP特性分析SQL执行情况
mysql>set optimizer_switch = 'index_condition_pushdown=on';
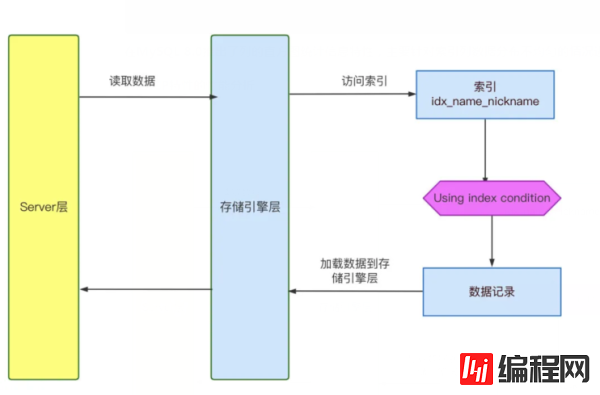
#执行计划 | 1 | SIMPLE | users01 | NULL | ref | idx_name_nickname | idx_name_nickname | 82 | const | 29016 | 11.11 | Using index condition | #status状态变量分析 | Handler_read_next | 12 | | Innodb_data_reads | 2989 | | Innodb_pages_read | 2836 | | Last_query_cost | 8580.324460 |从执行计划可以看出,走了复合索引 idx_name_nickname,Extra=Using index condition,且只扫描了12行数据,说明使用了索引条件下推ICP特性,SQL总共耗时10ms,跟关闭ICP特性下相比,SQL性能提升了5倍。

开启ICP特性后,由于 nickname 的 like 条件可以通过索引筛选,存储引擎层通过索引与 where 条件的比较来去除不符合条件的记录,这个过程不需要读取记录,同时只返回给Server层筛选后的记录,减少不必要的IO开销。
Extra显示的索引扫描方式
using where:查询使用索引的情况下,需要回表去查询所需的数据。
using index condition:查询使用了索引,但是需要回表查询数据。
using index:查询使用覆盖索引的时候会出现。
using index & using where:查询使用了索引,但是需要的数据都在索引列中能找到,不需要回表查询数据。
模糊匹配改写优化
在开启ICP特性后,对于条件where name = 'Lyn' and nickname like '%SK%' 可以利用复合索引 (name,nickname) 减少不必要的数据扫描,提升SQL性能。但对于 where nickname like '%SK%'完全模糊匹配查询能否利用ICP特性提升性能?首先创建nickname上单列索引 idx_nickname。
mysql>alter table users01 add index idx_nickname(nickname); #SQL执行计划 | 1 | SIMPLE | users01 | NULL | ALL | NULL | NULL | NULL | NULL | 114543 | 11.11 | Using where |从执行计划看到 type=ALL,Extra=Using where 走的是全部扫描,没有利用到ICP特性。
辅助索引idx_nickname(nickname)内部是包含主键id的,等价于(id,nickname)的复合索引,尝试利用覆盖索引特性将SQL改写为 select Id from users01 where nickname like '%SK%' 。
| 1 | SIMPLE | users01 | NULL | index | NULL | idx_nickname | 83 | NULL | 114543 | 11.11 | Using where; Using index |从执行计划看到,type=index,Extra=Using where; Using index,索引全扫描,但是需要的数据都在索引列中能找到,不需要回表。利用这个特点,将原始的SQL语句先获取主键id,然后通过id跟原表进行关联,分析其执行计划。
select * from users01 a , (select id from users01 where nickname like '%SK%') b where a.id = b.id;
| 1 | SIMPLE | users01 | NULL | index | PRIMARY | idx_nickname | 83 | NULL | 114543 | 11.11 | Using where; Using index | | 1 | SIMPLE | a | NULL | eq_ref | PRIMARY | PRIMARY | 4 | test.users01.id | 1 | 100.00 | NULL |从执行计划看,走了索引idx_nickname,不需要回表访问数据,执行时间从60ms降低为40ms,type = index 说明没有用到ICP特性,但是可以利用 Using where; Using index 这种索引扫描不回表的方式减少资源开销来提升性能。
全文索引
MySQL 5.6开始支持全文索引,可以在变长的字符串类型上创建全文索引,来加速模糊匹配业务场景的DML操作。它是一个inverted index(反向索引),创建 fulltext index 时会自动创建6个 auxiliary index tables(辅助索引表),同时支持索引并行创建,并行度可以通过参数 innodb_ft_sort_pll_degree 设置,对于大表可以适当增加该参数值。
删除全文索引的表的数据时,会导致辅助索引表大量delete操作,InnoDB内部采用标记删除,将已删除的DOC_ID都记录特殊的FTS_*_DELETED表中,但索引的大小不会减少,需要通过设置参数innodb_optimize_fulltext_only=ON 后,然后运行OPTIMIZE TABLE来重建全文索引。
全文索引特征
两种检索模式
IN NATURAL LANGUAGE MODE:默认模式,以自然语言的方式搜索,AGAINST('看风' IN NATURAL LANGUAGE MODE ) 等价于AGAINST('看风')。
IN BOOLEAN MODE:布尔模式,表是字符串前后的字符有特殊含义,如查找包含SK,但不包含Lyn的记录,可以用+,-符号。
AGAINST('+SK -Lyn' in BOOLEAN MODE);
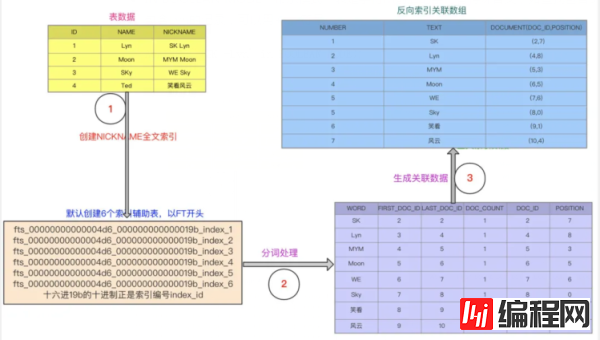
这时查找 nickname like '%Lyn%' ,通过反向索引关联数组可以知道,单词Lyn存储于文档4中,然后定位到具体的辅助索引表中。
全文索引分析
对表users01的nickname添加支持中文分词的全文索引
mysql>alter table users01 add fulltext index idx_full_nickname(nickname) with parser ngram;查看数据分布
#设置当前的全文索引表 mysql>set global innodb_ft_aux_table = 'test/users01'; #查看数据文件 mysql>select * from infORMation_schema.innodb_ft_index_cache; +--------+--------------+-------------+-----------+--------+----------+ | Word | FIRST_DOC_ID | LAST_DOC_ID | DOC_COUNT | DOC_ID | POSITION | +--------+--------------+-------------+-----------+--------+----------+ ............. | 看风 | 7 | 7 | 1 | 7 | 3 | | 笑看 | 7 | 7 | 1 | 7 | 0 |全文索引相关对象分析
#全文索引对象分析 mysql>SELECT table_id, name, space from INFORMATION_SCHEMA.INNODB_TABLES where name like 'test/%'; | 1198 | test/users01 | 139 | #存储被标记删除同时从索引中清理的文档ID,其中_being_deleted_cache是_being_deleted表的内存版本。 | 1199 | test/fts_00000000000004ae_being_deleted | 140 | | 1200 | test/fts_00000000000004ae_being_deleted_cache | 141 | #存储索引内部状态信息及FTS_SYNCED_DOC_ID | 1201 | test/fts_00000000000004ae_config | 142 | #存储被标记删除但没有从索引中清理的文档ID,其中_deleted_cache是_deleted表的内存版本。 | 1202 | test/fts_00000000000004ae_deleted | 143 | | 1203 | test/fts_00000000000004ae_deleted_cache | 144 |模糊匹配优化
对于SQL语句后面的条件 nickname like '%看风%' 默认情况下,CBO是不会选择走nickname索引的,该写SQL为全文索引匹配的方式:match(nickname) against('看风')。
mysql>explain select * from users01 where match(nickname) against('看风'); | 1 | SIMPLE | users01 | NULL | fulltext | idx_full_nickname | idx_full_nickname | 0 | const | 1 | 100.00 | Using where; Ft_hints: sorted |使用了全文索引的方式查询,type=fulltext,同时命中全文索引 idx_full_nickname,从上面的分析可知,在MySQL中,对于完全模糊匹配%%查询的SQL可以通过全文索引提高效率。
生成列
MySQL 5.7开始支持生成列,生成列是由表达式的值计算而来,有两种模式:VIRTUAL和STORED,如果不指定默认是VIRTUAL,创建语法如下:
col_name data_type [GENERATED ALWAYS] AS (expr) [**VIRTUAL** | **STORED**] [NOT NULL | NULL] 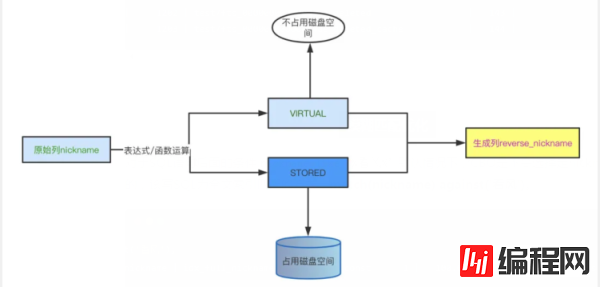
生成列特征
VIRTUAL生成列用于复杂的条件定义,能够简化和统一查询,不占用空间,访问列是会做计算。
STORED生成列用作物化缓存,对于复杂的条件,可以降低计算成本,占用磁盘空间。
支持辅助索引的创建,分区以及生成列可以模拟函数索引。
不支持存储过程,用户自定义函数的表达式,NONDETERMINISTIC的内置函数,如NOW(), RAND()以及不支持子查询
生成列使用
#添加基于函数reverse的生成列reverse_nickname mysql>alter table users01 add reverse_nickname varchar(200) generated always as (reverse(nickname)); #查看生成列信息 mysql>show columns from users01; | reverse_nickname | varchar(200) | YES | | NULL | VIRTUAL GENERATED | #虚拟生成列模糊匹配优化
对于where条件后的 like '%xxx' 是无法利用索引扫描,可以利用MySQL 5.7的生成列模拟函数索引的方式解决,具体步骤如下:
利用内置reverse函数将like '%风云'反转为like '云风%',基于此函数添加虚拟生成列。
在虚拟生成列上创建索引。
将SQL改写成通过生成列like reverse('%风云')去过滤,走生成列上的索引。
添加虚拟生成列并创建索引。
mysql>alter table users01 add reverse_nickname varchar(200) generated always as (reverse(nickname)); mysql>alter table users01 add index idx_reverse_nickname(reverse_nickname); #SQL执行计划 | 1 | SIMPLE | users01 | NULL | range | idx_reverse_nickname | idx_reverse_nickname | 803 | NULL | 1 | 100.00 | Using where |可以看到对于 like '%xxx' 无法使用索引的场景,可以通过基于生成列的索引方式解决。
“怎么优化模糊匹配Like %xxx%”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注编程网网站,小编将为大家输出更多高质量的实用文章!
--结束END--
本文标题: 怎么优化模糊匹配Like %xxx%
本文链接: https://lsjlt.com/news/61965.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0