这篇文章主要讲解了“Mysql 8.0.23新特性有哪些”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“mysql 8.0.23新特性有哪些”吧!在Mysql
这篇文章主要讲解了“Mysql 8.0.23新特性有哪些”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“mysql 8.0.23新特性有哪些”吧!
在Mysql 8.0.23之前,表中所有的列都是可见的(如果您有权限的话)。现在可以指定一个不可见的列,它将对查询隐藏。如果显式引用,它可以被查到。
让我们看看它是怎样的:
create table table1 ( id int auto_increment primary key, name varchar(20), age int invisible);在表结构中我们在Extra列可以看到INVISIBLE 关键字:
desc table1; +-------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+----------------+ | id | int | NO | PRI | NULL | auto_increment | | name | varchar(20) | YES | | NULL | | | age | int | YES | | NULL | INVISIBLE | +-------+-------------+------+-----+---------+----------------+查看show create table语句,注意到有一个不同,当我创建表时,我希望看到INVISIBLE 关键字,但事实并非如此:
show create table table1\\G ************************* 1. row ************************* Table: table1 Create Table: CREATE TABLE `table1` ( id int NOT NULL AUTO_INCREMENT, name varchar(20) DEFAULT NULL, age int DEFAULT NULL , PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci但是我确认这个语句在创建表时会将age 列设置为不可见。所以我们有2个不同的语法来创建不可见列。
INFORMATioN_SCHEMA 中也可以看到相关信息:
SELECT TABLE_NAME, COLUMN_NAME, EXTRA FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_SCHEMA = 'test' AND TABLE_NAME = 'table1'; +------------+-------------+----------------+ | TABLE_NAME | COLUMN_NAME | EXTRA | +------------+-------------+----------------+ | table1 | id | auto_increment | | table1 | name | | | table1 | age | INVISIBLE | +------------+-------------+----------------+插入一些数据,继续观察:
insert into table1 values (0,'mysql', 25), (0,'kenny', 35), (0, 'lefred','44'); ERROR: 1136: Column count doesn't match value count at row 1如预期,插入语句中如果我们不引用它,会报错。引用这些列:
insert into table1 (id, name, age) values (0,'mysql', 25), (0,'kenny', 35), (0, 'lefred','44'); Query OK, 3 rows affected (0.1573 sec查询表中数据:
select * from table1; +----+--------+ | id | name | +----+--------+ | 1 | mysql | | 2 | kenny | | 3 | lefred | +----+--------+再一次,如预期,我们看到不可见列没有显示。
如果我们指定它:
select name, age from table1; +--------+-----+ | name | age | +--------+-----+ | mysql | 25 | | kenny | 35 | | lefred | 44 | +--------+-----+当然我们可以将列从可见转为不可见或者将不可见转为可见:
alter table table1 modify name varchar(20) invisible, modify age integer visible; Query OK, 0 rows affected (0.1934 sec) select * from table1; +----+-----+ | id | age | +----+-----+ | 1 | 25 | | 2 | 35 | | 3 | 44 | +----+-----+我对这个新功能感到非常高兴,在下一篇文章中我们将会看到为什么这对InnoDB来说是一个重要的功能。
本文是与MySQL不可见列相关的系列文章的第二部分。
这篇文章介绍了为什么不可见列对InnoDB存储引擎很重要。
首先,让我简单解释一下InnoDB是如何处理主键的,以及为什么一个好的主键很重要。最后,为什么主键也很重要。
InnoDB如何存储数据?
InnoDB在表空间存储数据。这些记录存储并用聚簇索引排序(主键):它们被称为索引组织表。
所有的二级索引也将主键作为索引中的最右边的列(即使没有公开)。这意味着当使用二级索引检索一条记录时,将使用两个索引:二级索引指向用于最终检索该记录的主键。
主键会影响随机I/O和顺序I/O之间的比率以及二级索引的大小。
随机主键还是顺序主键?
如上所述,数据存储在聚簇索引中的表空间中。这意味着如果您不使用顺序索引,当执行插入时,InnoDB不得不重平衡表空间的所有页。
如果我们用InnoDB Ruby来说明这个过程,下面的图片显示了当使用随机字符串作为主键插入记录时表空间是如何更新的:
每次有一个插入,几乎所有的页都会被触及。
当使用自增整型作为主键时,同样的插入:
自增主键的情况下,只有第一个页和最后一个页才会被触及。
让我们用一个高层次的例子来解释这一点:
假设一个InnoDB页可以存储4条记录(免责声明:这只是一个虚构的例子),我们使用随机主键插入了一些记录:
插入新记录,主键为AA!
修改所有页以"重新平衡"聚簇索引,在连续主键的情况下,只有最后一个页面会被修改。想象一下成千上万的插入发生时所要做的额外工作。
这意味着选择好的主键是重要的。需要注意两点:
主键必须连续。
主键必须短。
UUID怎么样?
我通常建议使用自增整型(或bigint)作为主键,但是不要忘记监控它们!
但我也明白越来越多的开发人员喜欢使用uuid。
如果您打算使用UUID,您应该阅读MySQL8.0中UUID的支持,这篇文章推荐您用binary(16) 存储UUID。
如:
CREATE TABLE t (id binary(16) PRIMARY KEY); INSERT INTO t VALUES(UUID_TO_BIN(UUID()));然而,我并不完全同意这个观点,为什么?
因为使用uuid_to_bin() 可能会改变MySQL的UUID实现的顺序行为(有关更多信息,请参阅额外部分)。
但是如果您需要UUID,你需要在大索引上花费一定代价,索引不要浪费存储和内存在不需要的二级索引上:
select * from sys.schema_unused_indexes where object_schema not in ('performance_schema', 'mysql');没有任何主键?
对InnoDB表来说,当没有定义主键,会使用第一个唯一非空列。如果没有可用的列,InnoDB会创建一个隐藏主键(6位)。
这类主键的问题在于您无法控制它,更糟糕的是,这个值对所有没有主键的表是全局的,如果您同时对这些表执行多次写操作,可能会产生争用问题(dict_sys->mutex)。
不可见列的用处
有了新的不可见列,如果应用不允许添加新列,我们现在就可以向没有主键的表添加合适的主键。
首先先找到这些表:
SELECT tables.table_schema , tables.table_name , tables.engine FROM information_schema.tables LEFT JOIN ( SELECT table_schema , table_name FROM information_schema.statistics GROUP BY table_schema, table_name, index_name HAVING SUM( case when non_unique = 0 and nullable != 'YES' then 1 else 0 end ) = count(*) ) puks ON tables.table_schema = puks.table_schema AND tables.table_name = puks.table_name WHERE puks.table_name IS null AND tables.table_type = 'BASE TABLE' AND Engine="InnoDB"; +--------------+--------------+--------+ | TABLE_SCHEMA | TABLE_NAME | ENGINE | +--------------+--------------+--------+ | test | table2 | InnoDB | +--------------+--------------+--------+您也可以使用MySQL shell中的校验插件:https://GitHub.com/lefred/mysqlshell-plugins/wiki/check#getinnodbtableswithnopk
让我们查看表定义:
show create table table2\\G *************** 1. row *************** Table: table2 Create Table: CREATE TABLE table2 ( name varchar(20) DEFAULT NULL, age int DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci其中的数据:
select * from table2; +--------+-----+ | name | age | +--------+-----+ | mysql | 25 | | kenny | 35 | | lefred | 44 | +--------+-----+现在添加指定不可见主键:
alter table table2 add column id int unsigned auto_increment primary key invisible first;插入一条新记录:
insert into table2 (name, age) values ('PHP', 25); select * from table2; +--------+-----+ | name | age | +--------+-----+ | mysql | 25 | | kenny | 35 | | lefred | 44 | | php | 25 | +--------+-----+如果我们想要查看主键:
select id, table2.* from table2; +----+--------+-----+ | id | name | age | +----+--------+-----+ | 1 | mysql | 25 | | 2 | kenny | 35 | | 3 | lefred | 44 | | 4 | PHP | 25 | +----+--------+-----+总结
现在您知道InnoDB中为什么主键很重要,为什么一个好的主键更重要。
从MySQL8.0.23开始,您可以用不可见列解决没有主键的表。
额外
仅为娱乐,并说明我对使用UUID_TO_BIN(UUID()) 作为主键的看法,让我们重新使用UUID作为不可见列重复这个例子。
alter table table2 add column id binary(16) invisible first; alter table table2 modify column id binary(16) default (UUID_TO_BIN(UUID())) invisible; update table2 set id=uuid_to_bin(uuid()); alter table table2 add primary key(id);到目前还没什么特别的,只是创建不可见主键需要一些技巧。
查询:
select * from table2; +--------+-----+ | name | age | +--------+-----+ | mysql | 25 | | kenny | 35 | | lefred | 44 | +--------+-----+现在,我们再向这个表插入一条新数据:
insert into table2 (name, age) values ('PHP', 25); select * from table2; +--------+-----+ | name | age | +--------+-----+ | PHP | 25 | | mysql | 25 | | kenny | 35 | | lefred | 44 | +--------+-----+Mmmm...为什么PHP现在是第一行?
因为uuid() 并不连续...
select bin_to_uuid(id), table2.* from table2; +--------------------------------------+--------+-----+ | bin_to_uuid(id) | name | age | +--------------------------------------+--------+-----+ | 05aedcbd-5b36-11eb-94c0-c8e0eb374015 | PHP | 25 | | af2002e8-5b35-11eb-94c0-c8e0eb374015 | mysql | 25 | | af20117a-5b35-11eb-94c0-c8e0eb374015 | kenny | 35 | | af201296-5b35-11eb-94c0-c8e0eb374015 | lefred | 44 | +--------------------------------------+--------+-----+我们还有别的选择吗?
是的,如果我们参考官档,我们可以使用uuid_to_bin() 函数。
alter table table2 add column id binary(16) invisible first; alter table table2 modify column id binary(16) default (UUID_TO_BIN(UUID(),1)) invisible; update table2 set id=uuid_to_bin(uuid(),1);现在我们每次插入一条新记录,插入如期望一样是顺序的:
select bin_to_uuid(id,1), table2.* from table2; +--------------------------------------+--------+-----+ | bin_to_uuid(id,1) | name | age | +--------------------------------------+--------+-----+ | 5b3711eb-023c-e634-94c0-c8e0eb374015 | mysql | 25 | | 5b3711eb-0439-e634-94c0-c8e0eb374015 | kenny | 35 | | 5b3711eb-0471-e634-94c0-c8e0eb374015 | lefred | 44 | | f9f075f4-5b37-11eb-94c0-c8e0eb374015 | PHP | 25 | | 60ccffda-5b38-11eb-94c0-c8e0eb374015 | PHP8 | 1 | | 9385cc6a-5b38-11eb-94c0-c8e0eb374015 | python | 20 | +--------------------------------------+--------+-----+我们之前看了从MySQL8.0.23后,新的不可见列的功能。如果主键没有定义,我们如何使用它为InnoDB表添加主键。
如之前所述,好的主键对InnoDB很重要(存储,IOPS,二级索引,内存等)但是MySQL中主键还有一个重要的作用:复制!
异步复制
当使用"传统复制"时,如果您修改了一行记录(更新和删除),那么要在副本上修改的记录将使用索引来标识,当然如果有主键的话,还会使用主键。InnoDB自动生成的隐藏全局6字节主键永远不会被使用,因为它是全局的,所以不能保证源和副本之间是相同的。你根本不应该考虑它。
如果算法不能找到合适的索引,或者只能找到一个非唯一索引或者包含null值,则需要使用哈希表来识别表记录。该算法创建一个哈希表,其中包含更新或者删除操作的记录,并用键作为该行之前完整的映像。然后,该算法遍历目标表中的所有记录,如果找到了所选索引,则使用该索引,否则执行全表扫描(参见官档)。
因此,如果应用程序不支持使用额外的键作为主键,则使用隐藏列作为主键是加快复制的一个方法。
mysql> create table t1 (name varchar(20), age int); mysql> insert into t1 values ('mysql',25),('kenny', 35),('lefred', 44);现在添加一个自增列作为主键:
mysql> alter table t1 add id int auto_increment primary key first;然后按照应用程序中指定的INSERT语句添加一条记录:
mysql > insert into t1 values ('Python',20); ERROR: 1136: Column count doesn't match value count at row 1最好的方法是修改应用的INSERT 语句,但是可能吗?
多少应用程序仍然是使用SELECT * ,并且引用列时如col[2]?
如果是这样,您有两种方法:
分析所有的查询,使用重写查询插件
使用不可见列
在这种情况下,选择是容易的(至少对像我这样的懒人说)。
mysql > alter table t1 modify id int auto_increment invisible; mysql > insert into t1 values ('python',20); Query OK, 1 row affected (0.0887 sec)很简单,不是吗?
组复制
MySQL InnoDB Cluster使用另一种复制:Group Replication。
使用组复制的要求之一是要有一个主键(这就是为什么可以使用sql_require_primary_key)。
我们使用上例中重构表,不加主键,检查该实例能否作为InnoDB Cluster:
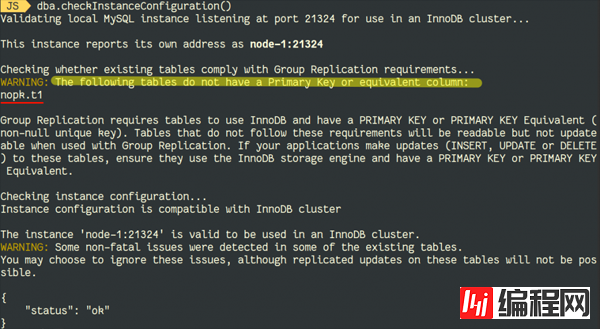
Https://lefred.be/wp-content/uploads/2021/01/Selection_9991017-1024x561.png
提示很清楚,该表上的修改不会复制到其他节点。
添加不可见主键,重新检查:

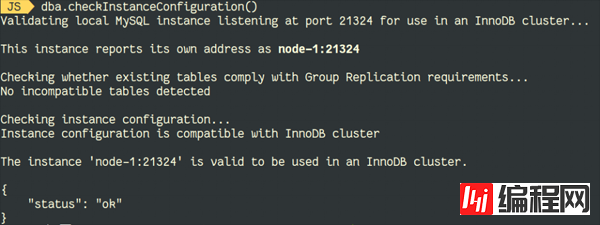
这意味着,如果应用程序使用的表没有主键,不允许迁移到MySQL InnoDB Cluster等高可用架构中,现在多亏了不可见列,这可以做到了。
感谢各位的阅读,以上就是“MySQL 8.0.23新特性有哪些”的内容了,经过本文的学习后,相信大家对MySQL 8.0.23新特性有哪些这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是编程网,小编将为大家推送更多相关知识点的文章,欢迎关注!
--结束END--
本文标题: MySQL 8.0.23新特性有哪些
本文链接: https://lsjlt.com/news/61872.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0