链接: https://blog.csdn.net/qq_36662478/article/details/89111437 1 JPA中的主键生成策略 通过annotation(注解)来映射实体类和数据库表的对应关系,
链接: https://blog.csdn.net/qq_36662478/article/details/89111437
通过annotation(注解)来映射实体类和数据库表的对应关系,基于annotation的主键标识为@Id注解, 其生成规则由@GeneratedValue设定的.这里的@id和@GeneratedValue都是JPA的标准用法。
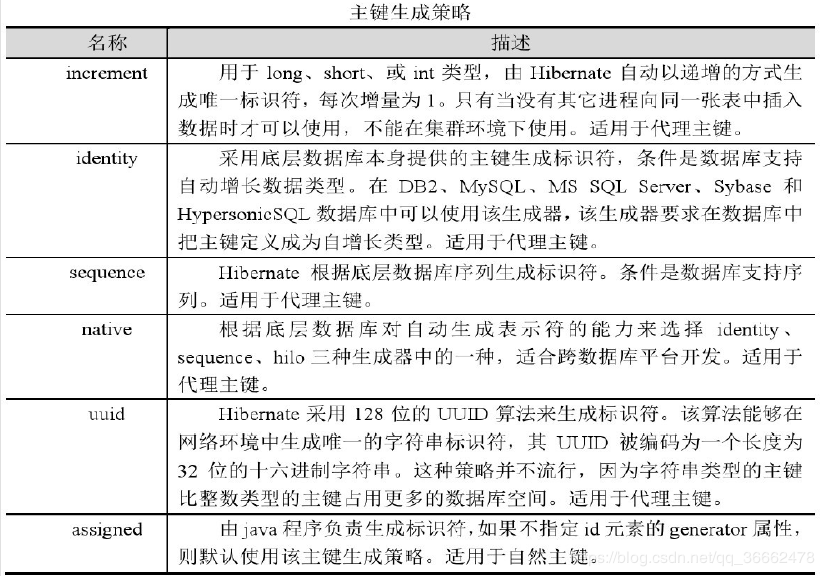
其中:JPA提供的四种标准用法为TABLE,SEQUENCE,IDENTITY,AUTOcolor{red}{TABLE,SEQUENCE,IDENTITY,AUTO}TABLE,SEQUENCE,IDENTITY,AUTO。由于我们使用的是hibernate实现,它也支持hibernate中定义的生成规则。
用法:
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long custId;
用法:
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE,generator="payablemoney_seq")
@SequenceGenerator(name="payablemoney_seq", sequenceName="seq_payment")
private Long custId;
//@SequenceGenerator源码中的定义
@Target({TYPE, METHOD, FIELD})
@Retention(RUNTIME)
public @interface SequenceGenerator {
//表示该表主键生成策略的名称,它被引用在@GeneratedValue中设置的“generator”值中
String name();
//属性表示生成策略用到的数据库序列名称。
String sequenceName() default "";
//表示主键初识值,默认为0
int initialValue() default 0;
//表示每次主键值增加的大小,例如设置1,则表示每次插入新记录后自动加1,默认为50
int allocationSize() default 50;
}
用法:
@Id
@GeneratedValue(strategy = GenerationType.TABLE, generator="payablemoney_gen")
@TableGenerator(name = "pk_gen", table="tb_generator", pkColumnName="gen_name", valueColumnName="gen_value", pkColumnValue="PAYABLEMOENY_PK", allocationSize=1 )
private Long custId;
//@TableGenerator的定义:
@Target({TYPE, METHOD, FIELD})
@Retention(RUNTIME)
public @interface TableGenerator {
//表示该表主键生成策略的名称,它被引用在@GeneratedValue中设置的“generator”值中
String name();
//表示表生成策略所持久化的表名,例如,这里表使用的是数据库中的“tb_generator”。
String table() default "";
//catalog和schema具体指定表所在的目录名或是数据库名
String catalog() default "";
String schema() default "";
//属性的值表示在持久化表中,该主键生成策略所对应键值的名称。例如在“tb_generator”中将“gen_name”作为主键的键值
String pkColumnName() default "";
//属性的值表示在持久化表中,该主键当前所生成的值,它的值将会随着每次创建累加。例如,在“tb_generator”中将“gen_value”作为主键的值
String valueColumnName() default "";
//属性的值表示在持久化表中,该生成策略所对应的主键。例如在“tb_generator”表中,将“gen_name”的值为“CUSTOMER_PK”。
String pkColumnValue() default "";
//表示主键初识值,默认为0。
int initialValue() default 0;
//表示每次主键值增加的大小,例如设置成1,则表示每次创建新记录后自动加1,默认为50。
int allocationSize() default 50;
UniqueConstraint[] uniqueConstraints() default {};
}
这里应用表tb_generator,定义为 :
CREATE TABLE tb_generator (
id NUMBER NOT NULL,
gen_name VARCHAR2(255) NOT NULL,
gen_value NUMBER NOT NULL,
PRIMARY KEY(id)
)
auto策略是JPA默认的策略,在hibernate的代码 GenerationType.AUTO 进行定义。使用 AUTO 策略就是将主键生成的策略交给持久化引擎 (persistence engine) 来决定,由它自己从 Table 策略,Sequence 策略和 Identity策略三种策略中选择最合适的。
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long custId;
在讲解Hibernate的主键生成策略之前,先来了解两个概念,即自然主键和代理主键,具体如下:
自然主键color{red}{自然主键}自然主键:
把具有业务含义的字段作为主键,称之为自然主键。例如在customer表中,如果把name字段作为主键,其前提条件必须是:每一个客户的姓名不允许为null,不允许客户重名,并且不允许修改客户姓名。尽管这也是可行的,但是不能满足不断变化的业务需求,一旦出现了允许客户重名的业务需求,就必须修改数据模型,重新定义表的主键,这给数据库的维护增加了难度。
代理主键color{red}{代理主键}代理主键:
把不具备业务含义的字段作为主键,称之为代理主键。该字段一般取名为“ID”,通常为整数类型,因为整数类型比字符串类型要节省更多的数据库空间。在上面例子中,显然更合理的方式是使用代理主键。
@Entity
@Table(name="cst_customer")
public class Customer implements Serializable {
@Id
@Column(name="cust_id")
//generator属性用于引用@GenericGenerator注解name属性的值
@GeneratedValue(generator="uuid")
//@GenericGenerator注解是hibernate提供的。
//strategy属性用于指定hibernate中提供的生成规则
//name属性用于给使用的生成规则起个名称,以供JPA引用
@GenericGenerator(name="uuid",strategy="uuid")
private String custId;
}
@Test
// 证明一级缓存的存在:
public void demo1(){
EntityManager em = JPAUtils.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
Customer customer1 = em.find(Customer.class, 1l);
// 马上发生一条sql查询1号客户.并将数据存入了一级缓存
System.out.println(customer1);
Customer customer2 = em.find(Customer.class, 1l);
// 没有发生SQL语句从一级缓存中获取数据.
System.out.println(customer2);
System.out.println(customer1 == customer2);
// true 一级缓存缓存的是对象的地址.
tx.commit();
em.close();
}
JPA 向一级缓存放入数据时,同时复制一份数据放入快照中,当使用commit()方法提交事务时,同时会清理一级缓存,这时会使用主键字段的值判断一级缓存中的对象和快照中的对象是否一致,如果两个对象中的属性发生变化,则执行update语句,将缓存的内容同步到数据库,并更新快照;如果一致,则不执行update语句。
快照的作用就是确保一级缓存中的数据和数据库中的数据一致。

程序代码:
@Test
public void test2(){
Customer c2 = null;
//内存中的一个对象
//1.获取对象
EntityManager em = JPAUtil.getEntityManager();
//2.开启事务
EntityTransaction tx = em.getTransaction();
tx.begin();
//3.执行查询:查询ID为5的客户对象
c2 = em.find(Customer.class, 5L);
System.out.println(c2);
//custName:Hibernate CRUD persist
//修改客户名称为:修正大厦
c2.setCustName("修正大厦");
System.out.println(c2);
//custName:修正大厦
//4.提交事务
tx.commit();
//5.关闭
em.close();
//当程序走到此处时,一级缓存就没了,但是并不影响我继续使用客户对象
System.out.println(c2);
//custName到底是什么
}
问题:
custName输出的到底是什么?
分析:
如果是Hibernate CRUD persist,则表示我们修改的代码没启任何作用,废代码一行。 如果输出是修正大厦,则表示我们程序内存的数据可能和数据库表中的不一致了,那就是脏数据。
思考:
有没有可能输出的是修正大厦,并且数据库的数据也变成了修正大厦呢? 如果真的发生了这种情况,是如何做到的呢?
答案:
JPA的快照机制(其实就是hibernate的快照机制)。

数据库中多表之间存在着三种关系,如图所示。
从图可以看出,系统设计的三种实体关系分别为:多对多、一对多和一对一关系color{red}{多对多、一对多和一对一关系}多对多、一对多和一对一关系。注意:一对多关系可以看为两种: 即一对多,多对一。所以说四种更精确。
明确:
我们今天只涉及实际开发中常用的关联关系,一对多和多对多。而一对一的情况,在实际开发中几乎不用。
在实际开发中,我们数据库的表难免会有相互的关联关系,在操作表的时候就有可能会涉及到多张表的操作。而在这种实现了ORM思想的框架中(如JPA),可以让我们通过操作实体类就实现对数据库表的操作。所以今天我们的学习重点是:掌握配置实体之间的关联关系。
第一步:首先确定两张表之间的关系。(如果关系确定错了,后面做的所有操作就都不可能正确。)
第二步:在数据库中实现两张表的关系
第三步:在实体类中描述出两个实体的关系
第四步:配置出实体类和数据库表的关系映射(重点)
我们采用的示例为客户和联系人。
客户:指的是一家公司,我们记为A。
联系人:指的是A公司中的员工。
在不考虑兼职的情况下,公司和员工的关系即为一对多。
在一对多关系中,我们习惯把一的一方称之为主表,把多的一方称之为从表。在数据库中建立一对多的关系,需要使用数据库的外键约束。
什么是外键?
指的是从表中有一列,取值参照主表的主键,这一列就是外键。
一对多数据库关系的建立,如下图所示:

CREATE TABLE cst_customer (
cust_id BIGINT (32) NOT NULL AUTO_INCREMENT COMMENT "客户编号(主键)",
cust_name VARCHAR (32) NOT NULL COMMENT "客户名称(公司名称)",
cust_source VARCHAR (32) DEFAULT NULL COMMENT "客户信息来源",
cust_industry VARCHAR (32) DEFAULT NULL COMMENT "客户所属行业",
cust_level VARCHAR (32) DEFAULT NULL COMMENT "客户级别",
cust_address VARCHAR (128) DEFAULT NULL COMMENT "客户联系地址",
cust_phone VARCHAR (64) DEFAULT NULL COMMENT "客户联系电话",
PRIMARY KEY (`cust_id`)
) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
CREATE TABLE `cst_linkman` (
`lkm_id` BIGINT (32) NOT NULL AUTO_INCREMENT,
`lkm_name` VARCHAR (32) DEFAULT NULL,
`lkm_gender` VARCHAR (32) DEFAULT NULL,
`lkm_phone` VARCHAR (32) DEFAULT NULL,
`lkm_mobile` VARCHAR (32) DEFAULT NULL,
`lkm_email` VARCHAR (32) DEFAULT NULL,
`lkm_position` VARCHAR (32) DEFAULT NULL,
`lkm_memo` VARCHAR (32) DEFAULT NULL,
`lkm_cust_id` BIGINT (32) DEFAULT NULL,
PRIMARY KEY (`lkm_id`),
FOREIGN KEY (`lkm_cust_id`) REFERENCES cst_customer(`cust_id`) ON DELETE SET NULL
) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
在实体类中,由于客户是少的一方,它应该包含多个联系人,所以实体类要体现出客户中有多个联系人的信息,代码如下:
@Entity//表示当前类是一个实体类
@Table(name="cst_customer")//建立当前实体类和表之间的对应关系
public class Customer implements Serializable {
@Id//表明当前私有属性是主键
@GeneratedValue(strategy=GenerationType.IDENTITY)//指定主键的生成策略
@Column(name="cust_id")//指定和数据库表中的cust_id列对应
private Long custId;
@Column(name="cust_name")//指定和数据库表中的cust_name列对应
private String custName;
@Column(name="cust_source")//指定和数据库表中的cust_source列对应
private String custSource;
@Column(name="cust_industry")//指定和数据库表中的cust_industry列对应
private String custIndustry;
@Column(name="cust_level")//指定和数据库表中的cust_level列对应
private String custLevel;
@Column(name="cust_address")//指定和数据库表中的cust_address列对应
private String custAddress;
@Column(name="cust_phone")//指定和数据库表中的cust_phone列对应
private String custPhone; //配置客户和联系人的一对多关系
@OneToMany(targetEntity=LinkMan.class)
@JoinColumn(name="lkm_cust_id",referencedColumnName="cust_id")
private Set<LinkMan> linkmans = new HashSet<LinkMan>(0);
public Long getCustId() { return custId; }
public void setCustId(Long custId) { this.custId = custId; }
public String getCustName() { return custName; }
public void setCustName(String custName) { this.custName = custName; }
public String getCustSource() { return custSource; }
public void setCustSource(String custSource) { this.custSource = custSource; }
public String getCustIndustry() { return custIndustry; }
public void setCustIndustry(String custIndustry) { this.custIndustry = custIndustry; }
public String getCustLevel() { return custLevel; }
public void setCustLevel(String custLevel) { this.custLevel = custLevel; }
public String getCustAddress() { return custAddress; }
public void setCustAddress(String custAddress) { this.custAddress = custAddress; }
public String getCustPhone() { return custPhone; }
public void setCustPhone(String custPhone) { this.custPhone = custPhone; }
public Set<LinkMan> getLinkmans() { return linkmans;}
public void setLinkmans(Set<LinkMan> linkmans) { this.linkmans = linkmans; }
@Override
public String toString() {
return "Customer [custId=" + custId + ", custName=" + custName + ", custSource=" + custSource + ", custIndustry=" + custIndustry + ", custLevel=" + custLevel + ", custAddress=" + custAddress + ", custPhone=" + custPhone + "]";
}
}
由于联系人是多的一方,在实体类中要体现出,每个联系人只能对应一个客户,代码如下:
@Entity
@Table(name="cst_linkman")
public class LinkMan implements Serializable {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
@Column(name="lkm_id")
private Long lkmId;
@Column(name="lkm_name")
private String lkmName;
@Column(name="lkm_gender")
private String lkmGender;
@Column(name="lkm_phone")
private String lkmPhone;
@Column(name="lkm_mobile")
private String lkmMobile;
@Column(name="lkm_email")
private String lkmEmail;
@Column(name="lkm_position")
private String lkmPosition;
@Column(name="lkm_memo")
private String lkmMemo;
//多对一关系映射:多个联系人对应客户
@ManyToOne(targetEntity=Customer.class)
@JoinColumn(name="lkm_cust_id",referencedColumnName="cust_id")
private Customer customer;
//用它的主键,对应联系人表中的外键
public Long getLkmId() { return lkmId; }
public void setLkmId(Long lkmId) { this.lkmId = lkmId; }
public String getLkmName() { return lkmName; }
public void setLkmName(String lkmName) { this.lkmName = lkmName; }
public String getLkmGender() { return lkmGender; }
public void setLkmGender(String lkmGender) { this.lkmGender = lkmGender; }
public String getLkmPhone() { return lkmPhone; }
public void setLkmPhone(String lkmPhone) { this.lkmPhone = lkmPhone; }
public String getLkmMobile() { return lkmMobile; }
public void setLkmMobile(String lkmMobile) { this.lkmMobile = lkmMobile; }
public String getLkmEmail() { return lkmEmail; }
public void setLkmEmail(String lkmEmail) { this.lkmEmail = lkmEmail; }
public String getLkmPosition() { return lkmPosition; }
public void setLkmPosition(String lkmPosition) { this.lkmPosition = lkmPosition; }
public String getLkmMemo() { return lkmMemo;}
public void setLkmMemo(String lkmMemo) { this.lkmMemo = lkmMemo; }
public Customer getCustomer() { return customer; }
public void setCustomer(Customer customer) { this.customer = customer; }
@Override
public String toString() {
return "LinkMan [lkmId=" + lkmId + ", lkmName=" + lkmName + ", lkmGender=" + lkmGender + ", lkmPhone=" + lkmPhone + ", lkmMobile=" + lkmMobile + ", lkmEmail=" + lkmEmail + ", lkmPosition=" + lkmPosition + ", lkmMemo=" + lkmMemo + "]";
}
}
作用:
建立一对多的关系映射
属性:
targetEntityClass:指定多的多方的类的字节码
mappedBy:指定从表实体类中引用主表对象的名称。
cascade:指定要使用的级联操作
fetch:指定是否采用延迟加载
orphanRemoval:是否使用孤儿删除
作用:
建立多对一的关系
属性:
targetEntityClass:指定一的一方实体类字节码
cascade:指定要使用的级联操作
fetch:指定是否采用延迟加载
optional:关联是否可选。如果设置为false,则必须始终存在非空关系。
作用:
用于定义主键字段和外键字段的对应关系。
属性:
name:指定外键字段的名称
referencedColumnName:指定引用主表的主键字段名称
unique:是否唯一。默认值不唯一
nullable:是否允许为空。默认值允许。
insertable:是否允许插入。默认值允许。
updatable:是否允许更新。默认值允许。
columnDefinition:列的定义信息。
@Test
public void test1(){
//创建客户和联系人对象
Customer c = new Customer();
//瞬时态
c.setCustName("TBD云集中心");
c.setCustLevel("VIP客户");
c.setCustSource("网络");
c.setCustIndustry("商业办公");
c.setCustAddress("昌平区北七家镇");
c.setCustPhone("010-84389340");
LinkMan l = new LinkMan();//瞬时态
l.setLkmName("TBD联系人");
l.setLkmGender("male");
l.setLkmMobile("13811111111");
l.setLkmPhone("010-34785348");
l.setLkmEmail("98354834@qq.com");
l.setLkmPosition("老师");
l.setLkmMemo("还行吧");
//建立他们的双向一对多关联关系
l.setCustomer(c);
c.getLinkmans().add(l);
EntityManager em = JPAUtil.createEntityManager();
EntityTransaction tx = em.getTransaction();
em.begin();
//按照要求:先保存客户,再保存联系人(此时符合保存原则:先保存主表,再保存从表)
em.persist(c);
//如果在把客户对象转成持久态时,不考虑联系人的信息。就不会有联系人的快照产生
em.persist(l);
tx.commit();
//默认此时会执行快照机制,当发现一级缓存和快照不一致了,使用一级缓存更新数据库。
}
通过保存的案例,我们可以发现在设置了双向关系之后,会发送两条insert语句,一条多余的update语句
@Test
public void test3(){
EntityManager em = JPAUtil.createEntityManager();
EntityTransaction tx = em.getTransaction();
em.begin();
//查询id为1的客户
Customer c1 = em.find(Customer.class, 2L);
//删除id为1的客户
em.remove(c1);
tx.commit();
}
级联操作: 指操作一个对象同时操作它的关联对象
使用方法:只需要在操作主体的注解上配置cascade
@OneToMany(mappedBy="customer",cascade=CascadeType.ALL,targetEntity=LinkMan.class)
@JoinColumn(name="lkm_cust_id",referencedColumnName="cust_id")
private Set<LinkMan> linkmans = new HashSet<LinkMan>(0);
我们采用的示例为用户和角色。
用户:指的是咱们班的每一个同学。
角色:指的是咱们班同学的身份信息。
比如A同学,它是我的学生,其中有个身份就是学生,还是家里的孩子,那么他还有个身份是子女。
同时B同学,它也具有学生和子女的身份。
那么任何一个同学都可能具有多个身份。同时学生这个身份可以被多个同学所具有。
所以我们说,用户和角色之间的关系是多对多。
多对多的表关系建立靠的是中间表,其中用户表和中间表的关系是一对多,角色表和中间表的关系也是一对多,如下图所示:
一个用户可以具有多个角色,所以在用户实体类中应该包含多个角色的信息,代码如下:
@Entity
@Table(name="sys_user")
public class SysUser implements Serializable {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
@Column(name="user_id")
private Long userId;
@Column(name="user_code")
private String userCode;
@Column(name="user_name")
private String userName;
@Column(name="user_passWord")
private String userPassword;
@Column(name="user_state")
private String userState;
//多对多关系映射
@ManyToMany(mappedBy="users")
private Set<SysRole> roles = new HashSet<SysRole>(0);
public Long getUserId() { return userId; }
public void setUserId(Long userId) { this.userId = userId; }
public String getUserCode() { return userCode; }
public void setUserCode(String userCode) { this.userCode = userCode; }
public String getUserName() { return userName; }
public void setUserName(String userName) { this.userName = userName; }
public String getUserPassword() { return userPassword; }
public void setUserPassword(String userPassword) { this.userPassword = userPassword; }
public String getUserState() { return userState; }
public void setUserState(String userState) { this.userState = userState; }
public Set<SysRole> getRoles() { return roles; }
public void setRoles(Set<SysRole> roles) { this.roles = roles; }
@Override
public String toString() {
return "SysUser [userId=" + userId + ", userCode=" + userCode + ", userName=" + userName + ", userPassword=" + userPassword + ", userState=" + userState + "]";
}
}
一个角色可以赋予多个用户,所以在角色实体类中应该包含多个用户的信息,代码如下:
@Entity
@Table(name="sys_role")
public class SysRole implements Serializable {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
@Column(name="role_id")
private Long roleId;
@Column(name="role_name")
private String roleName;
@Column(name="role_memo")
private String roleMemo;
//多对多关系映射
@ManyToMany
@JoinTable(name="user_role_rel", //中间表的名称
//中间表user_role_rel字段关联sys_role表的主键字段role_id
joinColumns={@JoinColumn(name="role_id",referencedColumnName="role_id")},
//中间表user_role_rel的字段关联sys_user表的主键user_id
inverseJoinColumns={@JoinColumn(name="user_id",referencedColumnName="user_id")} )
private Set<SysUser> users = new HashSet<SysUser>(0);
public Long getRoleId() { return roleId; }
public void setRoleId(Long roleId) { this.roleId = roleId; }
public String getRoleName() { return roleName; }
public void setRoleName(String roleName) { this.roleName = roleName; }
public String getRoleMemo() { return roleMemo; }
public void setRoleMemo(String roleMemo) { this.roleMemo = roleMemo; }
public Set<SysUser> getUsers() { return users; }
public void setUsers(Set<SysUser> users) { this.users = users; }
@Override
public String toString() {
return "SysRole [roleId=" + roleId + ", roleName=" + roleName + ", roleMemo=" + roleMemo + "]";
}
}
作用:
用于映射多对多关系
属性:
cascade:配置级联操作。
fetch:配置是否采用延迟加载。
targetEntity:配置目标的实体类。映射多对多的时候不用写。
作用:
针对中间表的配置
属性:
name:配置中间表的名称
joinColumns:中间表的外键字段关联当前实体类所对应表的主键字段
inverseJoinColumn:中间表的外键字段关联对方表的主键字段
作用:
用于定义主键字段和外键字段的对应关系。
属性:
name:指定外键字段的名称
referencedColumnName:指定引用主表的主键字段名称
unique:是否唯一。默认值不唯一
nullable:是否允许为空。默认值允许。
insertable:是否允许插入。默认值允许。
updatable:是否允许更新。默认值允许。
columnDefinition:列的定义信息。
@Test
public void test1(){
//创建对象
SysUser u1 = new SysUser();
u1.setUserName("用户1");
SysUser u2 = new SysUser();
u2.setUserName("用户2");
SysRole r1 = new SysRole();
r1.setRoleName("角色1");
SysRole r2 = new SysRole();
r2.setRoleName("角色2");
SysRole r3 = new SysRole();
r3.setRoleName("角色3");
//建立关联关系
u1.getRoles().add(r1);
u1.getRoles().add(r2);
r1.getUsers().add(u1);
r2.getUsers().add(u1);
u2.getRoles().add(r2);
u2.getRoles().add(r3);
r2.getUsers().add(u2);
r3.getUsers().add(u2);
EntityManager em = JPAUtil.createEntityManager();
EntityTransaction tx = em.getTransaction();
em.begin();
em.persist(u1);
em.persist(u2);
em.persist(r1);
em.persist(r2);
em.persist(r3);
tx.commit();
}
@Test
public void test3(){
//获取JPA操作对照
EntityManager em = JPAUtil.getEntityManager();
//获取JPA事务对象
EntityTransaction tx= em.getTransaction();
//开启事务
tx.begin();
//查询id为1的客户
Customer c1 = em.find(Customer.class, 2L);
//删除id为1的客户
em.remove(c1);
tx.commit();
}
级联删除的配置:
@OneToMany(targetEntity=LinkMan.class ,cascade=CascadeType.ALL) //用CascadeType.REMOVE也可以
private Set<LinkMan> linkmans = new HashSet<LinkMan>(0);
对象图导航检索方式是根据已经加载的对象,导航到他的关联对象。它利用类与类之间的关系来检索对象。
例如:我们通过ID查询方式查出一个客户,可以调用Customer类中的getLinkMans()方法来获取该客户的所有联系人。
对象导航查询的使用要求是:两个对象之间必须存在关联关系。color{red}{对象导航查询的使用要求是:两个对象之间必须存在关联关系。}对象导航查询的使用要求是:两个对象之间必须存在关联关系。
查询一个客户,获取该客户下的所有联系人:
@Test
public void test1(){
//获取JPA操作对照
EntityManager em = JPAUtil.getEntityManager();
//获取JPA事务对象
EntityTransaction tx= em.getTransaction();
//开启事务
tx.begin();
Customer c = em.find(Customer.class, 1L);
Set<LinkMan> linkmans = c.getLinkmans();
//此处就是对象导航查询
for(Object o : linkmans){
System.out.println(o);
}
tx.commit();
}
查询一个联系人,获取该联系人的所有客户:
@Test
public void test3(){
//获取JPA操作对照
EntityManager em = JPAUtil.getEntityManager();
//获取JPA事务对象
EntityTransaction tx= em.getTransaction();
//开启事务
tx.begin();
LinkMan l = em.find(LinkMan.class, 1L);
System.out.println(l.getCustomer());
tx.commit();
}
问题1:我们查询客户时,要不要把联系人查询出来?
分析:
如果我们不查的话,在用的时候还要自己写代码,调用方法去查询。
如果我们查出来的,不使用时又会白白的浪费了服务器内存。
解决:
采用延迟加载的思想。通过配置的方式来设定当我们在需要使用时,发起真正的查询。
配置的方式:
@OneToMany(mappedBy="customer",fetch=FetchType.LAZY)
private Set<LinkMan> linkMans = new HashSet<>(0)
问题2:我们查询联系人时,要不要把客户查询出来?
分析:
如果我们不查的话,在用的时候还要自己写代码,调用方法去查询。
如果我们查出来的话,一个对象不会消耗太多的内存。而且多数情况下我们都是要使用的。
例如:查询联系人详情时,肯定会看看该联系人的所属客户。
解决:
采用立即加载的思想。通过配置的方式来设定,只要查询从表实体,就把主表实体对象同时查出来。
配置的方式:
@ManyToOne(targetEntity=Customer.class,fetch=FetchType.EAGER)
@JoinColumn(name="cst_lkm_id",referencedColumnName="cust_id")
private Customer customer;
顾名思义:即根据主键查询一个实体。在JPA中提供了两个方法。分别是:
find(Class entityClass,Object id);
getReference(Class entityClass,Object id);
他们的区别是:
查询的时机不一样:
find的方法是立即加载,只要一调用方法就马上发起查询。
getReference方法是延迟加载,只有真正用到数据时才发起查询。(按需加载)
返回的结果不一样:
find方法返回的是实体类对象。
getReference方法返回的是实体类的代理对象。
示例:
//查询一个
//立即加载
@Test
public void testFindOne() {
EntityManager em = JPAUtil.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
Customer c = em.find(Customer.class, 1);
System.out.println(c);
tx.commit();
em.close();
}
//查询一个
//懒加载(延迟加载)
@Test
public void testFindOne2() {
EntityManager em = JPAUtil.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
Customer c = em.getReference(Customer.class, 1);
System.out.println(c.toString());
tx.commit();
em.close();
}
此种方式是使用JPQL语句查询。全称是Java Persistence Query Language。JPQL语句是JPA中定义的一种查询语言。此种语言的用意是让开发者忽略数据库表和表中的字段,而关注实体类及实体类中的属性。更加契合操作实体类就相当于操作数据库表的ORM思想。但是又不完全脱离SQL语句,例如:
排序,仍然使用order关键字。
聚合函数:在JPQL中也可以是使用。
它的写法是:
把查询的表名换成实体类名称,把表中的字段名换成实体类的属性名称。
注意:
此处我们必须明确,实体类属性名称指的是get/set方法后面的部分,且首字母改小写。而非私有类成员变量。只不过我们的get/set方法都是通过工具生成的,所以可以直接写私有成员变量名称。
示例:
@Test
public void testFindAll() {
EntityManager em = JPAUtil.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
//JPQL的写法是把SQL语句中 列名换成属性名称,把表名换成实体类名称
//select * from cst_customer
Query query = em.createQuery("select c from Customer c ");
//写的是JPQL语句 java persistence query language
List<Customer> customers = query.getResultList();
for(Customer c : customers) {
System.out.println(c);
}
tx.commit();
em.close();
}
此种方式是使用原生SQL语句查询数据库。采用此种方式查询,我们可以在数据库可视化编译器中先把语句写好,然后粘到代码中。
注意:
一般采用ORM框架作为持久层解决方案时,很少使用原生SQL语句。(特定情况除外:例如统计分析的语句)
示例:
@Test
public void test3() {
EntityManager em = JPAUtil.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
// createNativeQuery方法中第一个参数就是SQL语句,第二个参数是要封装的实体类字节码
Query query = em.createNativeQuery("select * from cst_customer",Customer.class);
List list = query.getResultList();
System.out.println(list);
}
QBC全称是Query By Criteria。此种方式是一种更加面向对象的查询方式。并且可扩展条件查询api,通过它完全不需要考虑数据库底层如何实现,以及SQL语句如何编写。
细节:
JPQL能查的,QBC都能查,反之亦然。
示例:
@Test
public void test1() {
//1.获取JPA的操作数据库对象
EntityManager em = JPAUtil.createEntityManager();
//2.获取事务对象
EntityTransaction tx = em.getTransaction();
//3.开启事务
tx.begin();
//4.创建CriteriaBuilder对象,该对象中定义着查询条件涉及的方法
CriteriaBuilder cb = em.getCriteriaBuilder();
//5.获取QBC的查询的对象CriteriaQuery.
//它可以加一些SQL的子句例如:where group by order by having等等。
CriteriaQuery<Customer> cq = cb.createQuery(Customer.class);
//6.获取实体类对象的封装对象,有此对象之后,所有实体类都可以看成此类型
Root<Customer> root = cq.from(Customer.class);
//7.创建条件对象
Predicate p1 = cb.like(root.get("custName"), "%修%");
Predicate p2 = cb.equal(root.get("custLevel"), "22");
//8.给查询对象设置查询条件
cq.where(p1,p2);
//9.执行查询,获取结果
List list = em.createQuery(cq).getResultList();
System.out.println(list);
//10.释放
tx.commit();
em.close();
}
--结束END--
本文标题: (转载)SpringData JPA (二) 进阶 - JPA一对多、多对多
本文链接: https://lsjlt.com/news/5967.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0