而对HBase的学习,也离不开索引结构的学习,它使用了一种LSM树((Log-Structured Merge-Tree))的索引结构。 下面,我们就结合HBase的实现,来深入了解HBase的核心数据结构与算法,包括索引结构LSM树,内

而对HBase的学习,也离不开索引结构的学习,它使用了一种LSM树((Log-Structured Merge-Tree))的索引结构。
下面,我们就结合HBase的实现,来深入了解HBase的核心数据结构与算法,包括索引结构LSM树,内存数据结构跳表、文件多路归并、读优化的布隆过滤器等。
LSM树和B+树、哈希索引一样,是一种索引结构,那它们有什么区别呢?
LSM树的索引一般由两部分组成。
一部分在内存中,将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘(由此提升了写性能),HBase采用跳跃表来维护了一个有序的KeyValue集合。
另一部分在磁盘中,磁盘部分一般由多个内部KeyValue有序的文件组成。
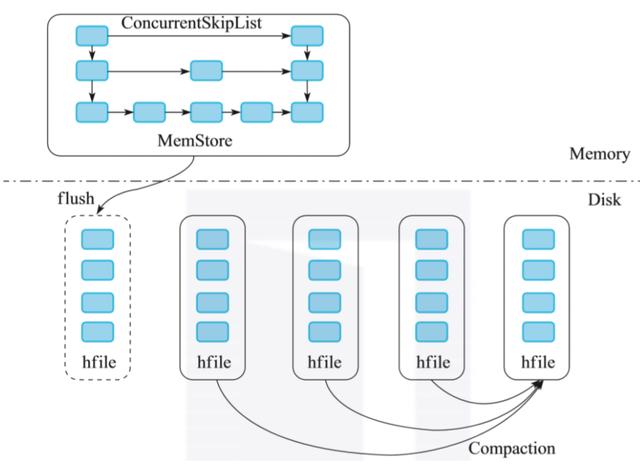
HBase中对LSM树的实现,是在内存中用一个ConcurrentSkipListMap保存数据。数据写入时,直接写入MemStore中。随着不断写入,一旦内存占用超过一定的阈值时,就把内存部分的数据导出,形成一个有序的数据文件,存储在磁盘上。
我们仔细看下内存中的实现,采用了跳跃表(SkipList)的数据结构。
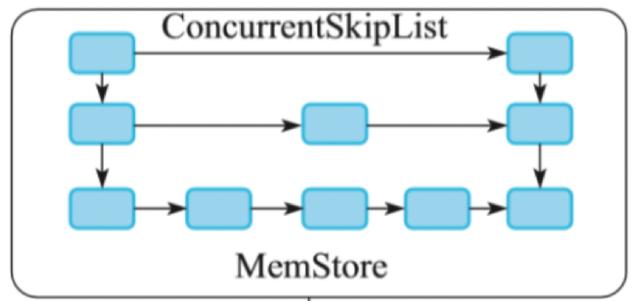
跳跃表是一种能高效实现插入、删除、查找的内存数据结构,这些操作的期望复杂度都是O(logN)。
跳跃表的优势在于
因此,我们可以看到,诸如Redis、LevelDB、HBase等KV数据库,都把跳跃表作为一种维护有序数据集合的核心数据结构。
跳跃表可以看作是一种特殊的有序链表。
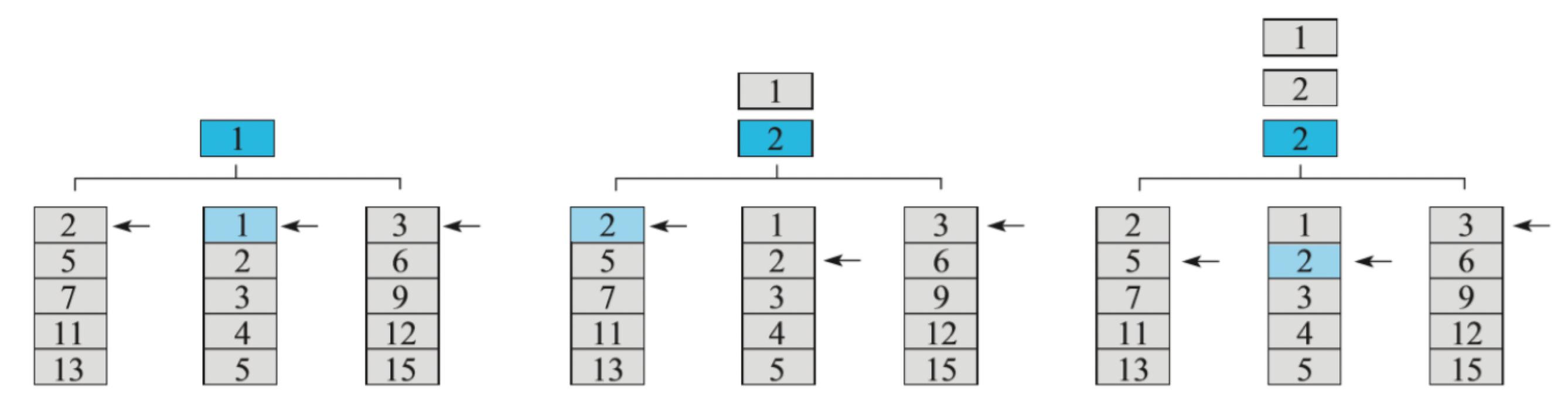
在跳跃表中查找一个指定元素的流程比较简单。如上图所示,以左上角元素作为起点:
跳跃表的构建稍微复杂一点。
首先,需要按照上述查找流程找到待插入元素的前驱和后继;然后,按照如下随机算法生成一个高度值:
// p是一个(0,1)之间的常数,一般取p=1/4或者1/2
public void randomHeight(doubule p) {
int height = 0;
while(random.newtDouble < p) {
height++;
}
return height + 1;
}最后,将待插入节点按照randomHeight生成一个垂直节点的位置(这个节点的层数位置正好等于高度值),之后插入到跳跃表的多条链表中去。假设height=randomHeight(p),这里需要分两种情况讨论:
随着写入的增加,内存数据会不断地刷新到磁盘上。最终磁盘上的数据文件会越来越多。如果用户有读取请求,则需要将大量的磁盘文件进行多路归并,之后才能读取到所需的数据。
这里可以回顾一下多路归并的算法思路。
假设现在有K个文件,其中第i个文件内部存储有Ni个正整数(这些整数在文件内按照从小到大的顺序存储),如何将K个有序文件合并成一个大的有序文件?
这里,就可以使用多路归并算法进行实现。对每个文件设计一个指针,取出K个指针中数值最小的一个,然后把最小的那个指针后移,接着继续找K个指针中数值最小的一个,继续后移指针……直到N个文件全部读完为止。
具体实现上,可以用一个最小堆来维护K个指针,每次从堆中取最小值,开销为logK,最多从堆中取sum(Ni)次元素。
从上面可以看到,LSM树的索引实际上是将写入操作全部转化为了磁盘的顺序写入,提高了写入性能。但是,这种设计是以牺牲一定的读操作性能为代价的,因为读取的时候,需要归并多个文件来获取满足条件的KV,非常消耗磁盘io。所以,我们知道HBase会通过compaction来合并小文件,降低文件个数,来提高读取效率。
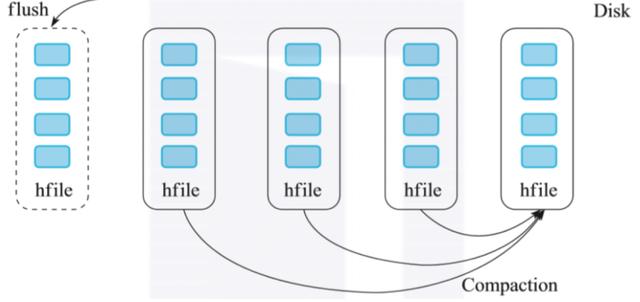
除了使用compaction归并小文件外,HBase还利用布隆过滤器来提高读取性能。
要了解布隆过滤器,我们先来看一个小问题。
如何高效判断元素w是否存在于集合A之中?
首先想到的答案是HashMap吧,把集合A中的元素一个个放到HashMap中的key,然后可以在 O(1) 的时间复杂度内返回结果,效率很高。
这样确实可以解决小数据量场景下元素存在性判定,但如果A中元素数量巨大,甚至数据量远远超过机器内存空间,该如何解决问题呢?
实现一个基于磁盘和内存的哈希索引当然可以解决这个问题。而另一种低成本的方式就是借助布隆过滤器(Bloom Filter)来实现。布隆过滤器是一个 bit 向量或者说 bit 数组,数组由一个长度为N的0、1组成。
如何构建一个布隆过滤器呢?
首先,我们需要将数组array每个元素初始设为0。
然后对集合A中的每个元素w,做K次哈希,第i次哈希值对N取模得到一个index(i),即index(i)=HASH_i(w) % N,将array数组中的array[index(i)]置为1。最终array变成一个某些元素为1的01数组。
下面举个例子,集合A = {x, y, z},N = 18,K = 3。
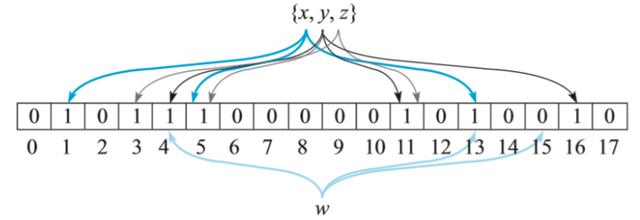
初始化array = [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]。
最终得到的布隆过滤器串为:[0,1,0,1,1,1,0,0,0,0,0,1,0,1,0,0,1,0]。
此时,对于任意其他元素w,K次哈希值分别为:
HASH_0(w)%N = 4
HASH_1(w)%N = 13
HASH_2(w)%N = 17
可以发现,布隆过滤器串中的第17位为0,因此可以确认w肯定不在集合A中。因为若w在A中,则第17位必定为1。
如果有另外一个元素t,K次哈希值分别为:
HASH_0(t)%N = 5
HASH_1(t)%N = 11
HASH_2(t)%N = 13
我们发现布隆过滤器串中的第5、11、13位都为1,我们猜测这个元素t可能在集合A中,但是不能完全肯定。
因此,布隆过滤器串对任意给定元素w,给出的存在性结果为两种:
有论文经过证明,当N取K*size(A)/ln2时(其中size(A)表示集合A元素个数),能保证最低的误判率。
如果某个集合有20个元素,K取3时,则设计一个N = 3×20/ln2 = 87 长度的二进制串来保存布隆过滤器比较合适。
有了布隆过滤器这样一个存在性判断之后,我们回到最开始提到的案例。把集合A的元素按照顺序分成若干个块,每块不超过64KB,每块内的多个元素都算出一个布隆过滤器串,多个块的布隆过滤器组成索引数据。为了判断元素w是否存在于集合A中,先对w计算每一个块的布隆过滤器串的存在性结果,若结果为肯定不存在,则继续判断w是否可能存在于下一个数据块中。若结果为可能存在,则读取对应的数据块,判断w是否在数据块中,若存在则表示w存在于集合A中;若不存在则继续判断w是否在下一个数据块中。
正是由于布隆过滤器只需占用极小的空间,便可给出“可能存在”和“肯定不存在”的存在性判断,因此可以提前过滤掉很多不必要的数据块,从而节省了大量的磁盘IO。HBase的Get操作就是通过运用低成本高效率的布隆过滤器来过滤大量无效数据块的,从而节省大量磁盘IO。
参考文献:
《HBase原理与实践》
看到这里了,原创不易,点个关注、点个赞吧,你最好看了~
知识碎片重新梳理,构建Java知识图谱:https://GitHub.com/saigu/JavaKnowledgeGraph
--结束END--
本文标题: 「从零单排HBase 09」HBase的那些数据结构和算法
本文链接: https://lsjlt.com/news/5914.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0