这篇文章主要为大家展示了“Mysql中索引、锁、事务知识点有哪些”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“mysql中索引、锁、事务知识点有哪些”这篇文章吧
这篇文章主要为大家展示了“Mysql中索引、锁、事务知识点有哪些”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“mysql中索引、锁、事务知识点有哪些”这篇文章吧。
具体如下:
索引,类似书籍的目录,可以根据目录的某个页码立即找到对应的记录。
索引的优点:
天生排序。
快速查找。
索引的缺点:
占用空间。
降低更新表的速度。
注意点:小表使用全表扫描更快,中大表才使用索引。超级大表索引基本无效。
索引从实现上说,分成 2 种:聚集索引和辅助索引(也叫二级索引或者非聚集索引)
从功能上说,分为 6 种:普通索引,唯一索引,主键索引,复合索引,外键索引,全文索引。
详细说说 6 种索引:
普通索引:最基本的索引,没有任何约束。
唯一索引:与普通索引类似,但具有唯一性约束。
主键索引:特殊的唯一索引,不允许有空值。
复合索引:将多个列组合在一起创建索引,可以覆盖多个列。
外键索引:只有InnoDB类型的表才可以使用外键索引,保证数据的一致性、完整性和实现级联操作。
全文索引:Mysql 自带的全文索引只能用于 InnoDB、MyISAM ,并且只能对英文进行全文检索,一般使用全文索引引擎(ES,Solr)。
注意:主键就是唯一索引,但是唯一索引不一定是主键,唯一索引可以为空,但是空值只能有一个,主键不能为空。
另外,InnoDB 通过主键聚簇数据,如果没有定义主键且没有定义聚集索引, MySql 会选择一个唯一的非空索引代替,如果没有这样的索引,会隐式定义个 6 字节的主键作为聚簇索引,用户不能查看或访问。
简单点说:
设置主键时,会自动生成一个唯一索引,如果之前没有聚集索引,那么主键就是聚集索引。
没有设置主键时,会选择一个不为空的唯一索引作为聚集索引,如果还没有,那就生成一个隐式的 6 字节的索引。
MySql 将数据按照页来存储,默认一页为 16kb,当你在查询时,不会只加载某一条数据,而是将这个数据所在的页都加载到 pageCache 中,这个其实和 OS 的就近访问原理类似。
MySql 的索引使用 B+ 树结构。在说 B+ 树之前,先说说 B 树,B 树是一个多路平衡查找树,相较于普通的二叉树,不会发生极度不平衡的状况,同时也是多路的。
B 树的特点是:他会将数据也保存在非页子节点。
看图可知:
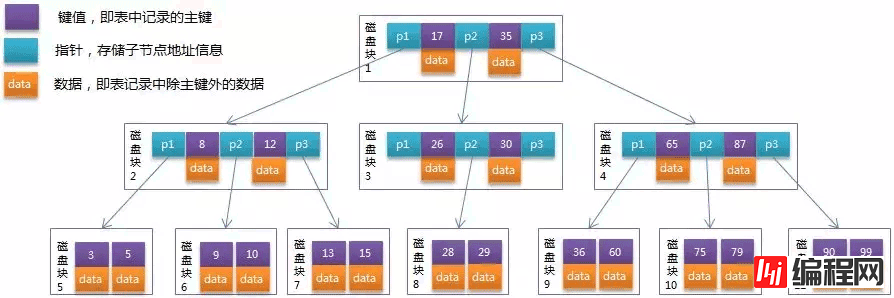
而这个特点会导致非页子节点不能存储大量的索引。
而 B+ Tree 就是针对这个对 B tree 做了优化。如下图所示:
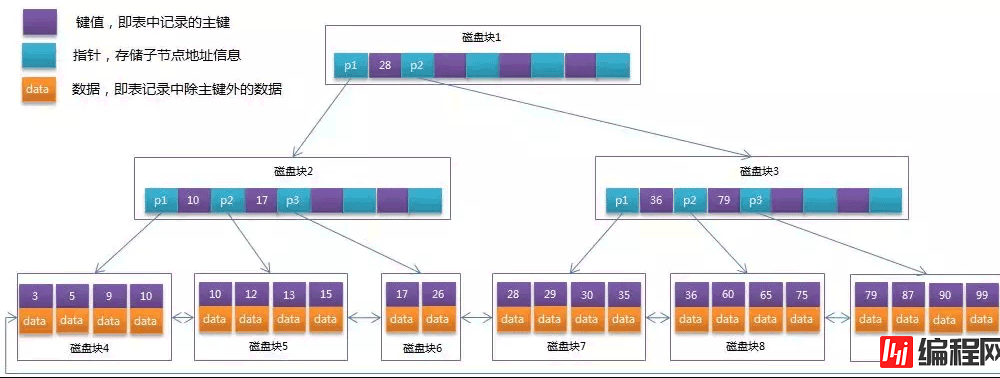
我们看到,B+ Tree 将所有的 data 数据都保存到了叶子节点中,非也子节点只保存索引和指针。
我们假设一个非页子节点是 16kb,每个索引,即主键是 bigint,即 8b,指针为 8b。那么每页能存储大约 1000 个索引(16kb/ 8b + 8b).
而一颗 3 层的 B+树能够存储多少索引呢?如下图:
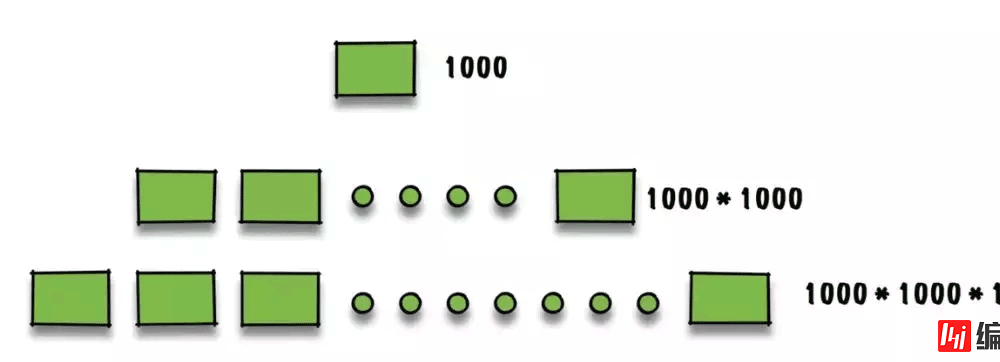
大约能够存储 10 亿个索引。通常 B+ 树的高度在 2-4 层,由于 MySql 在运行时,根节点是常驻内存的,因此每次查找只需要大约 2 -3 次 io。可以说,B+ 树的设计,就是根据机械磁盘的特性来进行设计的。
知道了索引的设计,我们能够知道另外一些信息:
MySql 的主键不能太大,如果使用 UUID 这种,将会浪费 B+ 树的非叶子节点。
MySql 的主键最好是自增的,如果使用 UUID 这种,每次插入都会调整 B+树,从而导致页分裂,严重影响性能。
那么,如果项目中使用了分库分表,我们通常都会需要一个主键进行 sharding,那怎么办呢?在实现上,我们可以保留自增主键,而逻辑主键用来作为唯一索引即可。
关于 Mysql 的锁,各种概念就会喷涌而出,事实上,锁有好几种维度,我们来解释一下。
1. 类型维度
共享锁(读锁 / S 锁)
排它锁(写锁 / X 锁)
类型细分:
意向共享锁
意向排他(互斥)锁
悲观锁(使用锁,即 for update)
乐观锁(使用版本号字段,类似 CAS 机制,即用户自己控制。缺点:并发很高的时候,多了很多无用的重试)
2. 锁的粒度(粒度维度)
表锁
页锁(Mysql BerkeleyDB 引擎)
行锁(InnoDB)
3. 锁的算法(算法维度)
Record Lock(单行记录)
Gap Lock(间隙锁,锁定一个范围,但不包含锁定记录)
Next-Key Lock(Record Lock + Gap Lock,锁定一个范围,并且锁定记录本身, MySql 防止幻读,就是使用此锁实现)
4. 默认的读操作,上锁吗?
默认是 mvcC 机制(“一致性非锁定读”)保证 RR 级别的隔离正确性,是不上锁的。
可以选择手动上锁:select xxxx for update (排他锁); select xxxx lock in share mode(共享锁),称之为“一致性锁定读”。
使用锁之后,就能在 RR 级别下,避免幻读。当然,默认的 MVCC 读,也能避免幻读。
既然 RR 能够防止幻读,那么,SERIALIZABLE 有啥用呢?
防止丢失更新。例如下图:
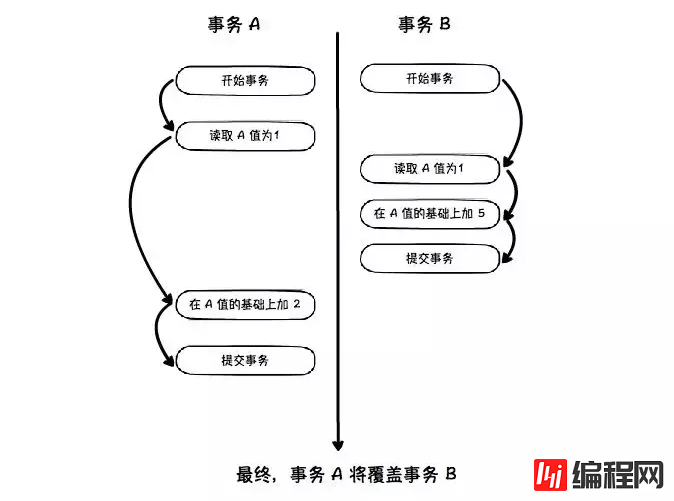
这个时候,我们必须使用 SERIALIZABLE 级别进行串行读取。
最后,行锁的实现原理就是锁住聚集索引,如果你查询的时候,没有正确地击中索引,MySql 优化器将会抛弃行锁,使用表锁。
事务是数据库永恒不变的话题, ACID:原子性,一致性,隔离性,持久性。
四个特性,最重要的就是一致性。而一致性由原子性,隔离性,持久性来保证。
原子性由 Undo log 保证。Undo Log 会保存每次变更之前的记录,从而在发生错误时进行回滚。
隔离性由 MVCC 和 Lock 保证。这个后面说。
持久性由 Redo Log 保证。每次真正修改数据之前,都会将记录写到 Redo Log 中,只有 Redo Log 写入成功,才会真正的写入到 B+ 树中,如果提交之前断电,就可以通过 Redo Log 恢复记录。
然后再说隔离性。
隔离级别:
未提交读(RU)
已提交读(RC)
可重复读(RR)
串行化(serializable)
每个级别都会解决不同的问题,通常是3 个问题:脏读,不可重复读,幻读。一张经典的图:
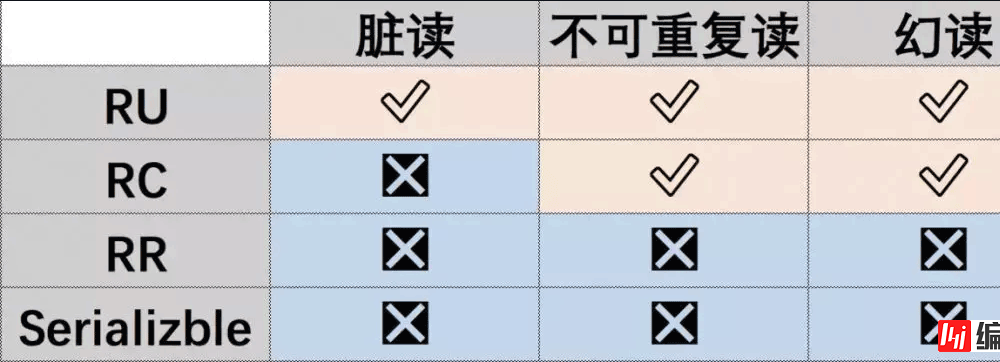
这里有个注意点,关于幻读,在数据库规范里,RR 级别会导致幻读,但是,由于 Mysql 的优化,MySql 的 RR 级别不会导致幻读:在使用默认的 select 时,MySql 使用 MVCC 机制保证不会幻读;你也可以使用锁,在使用锁时,例如 for update(X 锁),lock in share mode(S 锁),MySql 会使用 Next-Key Lock 来保证不会发生幻读。前者称为快照读,后者称为当前读。
原理剖析:
RU 发生脏读的原因:RU 原理是对每个更新语句的行记录进行加锁,而不是对整个事务进行加锁,所以会发生脏读。而 RC 和 RR 会对整个事务加锁。
RC 不能重复读的原因:RC 每次执行 SQL 语句都会生成一个新的 Read View,每次读到的都是不同的。而 RR 的事务从始至终都是使用同一个 Read View。
RR 不会发生幻读的原因: 上面说过了。
那 RR 和 Serializble 有什么区别呢?答:丢失更新。本文关于锁的部分已经提到。
MVCC 介绍:全称多版本并发控制。
innoDB 每个聚集索引都有 4 个隐藏字段,分别是主键(RowID),最近更改的事务 ID(MVCC 核心),Undo Log 的指针(隔离核心),索引删除标记(当删除时,不会立即删除,而是打标记,然后异步删除);
本质上,MVCC 就是用 Undo Log 链表实现。
MVCC 的实现方式:事务以排它锁的方式修改原始数据,把修改前的数据存放于 Undo Log,通过回滚指针与数据关联,如果修改成功,什么都不做,如果修改失败,则恢复 Undo Log 中的数据。
多说一句,通常我们认为 MVCC 是类似乐观锁的方式,即使用版本号,而实际上,innoDB 不是这么实现的。当然,这不影响我们使用 MySql。
以上是“MySql中索引、锁、事务知识点有哪些”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注编程网数据库频道!
--结束END--
本文标题: MySql中索引、锁、事务知识点有哪些
本文链接: https://lsjlt.com/news/57722.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0