1 需求背景 随着数据的大集中,银行纷纷建设了负责本行各个业务处理的生产数据中心,数据中心因其负责了全行的各个业务系统,所以其并发业务负荷能力和不间断运行是评价一个数据中心成熟与否的关键性指标。 近年来,随着网上银行、
1
需求背景
随着数据的大集中,银行纷纷建设了负责本行各个业务处理的生产数据中心,数据中心因其负责了全行的各个业务系统,所以其并发业务负荷能力和不间断运行是评价一个数据中心成熟与否的关键性指标。
近年来,随着网上银行、手机银行等各种互联网业务的迅猛发展,银行数据中心的业务压力成倍增加,用户对于业务访问质量的要求也越来越高,保障业务系统7*24小时连续运营并提升用户体验成为信息部门的首要职责。
为适应互联网业务的快速增长,保障银行各业务安全稳定的不间断运行,提高市场竞争力,同时符合监管机构的要求,同城双中心、两地三中心正在成为银行的共同选择。
2
发展趋势
多数据中心的建设需要投入大量资金,其项目周期往往很长,涉及的范围也比较大。从技术上来说,要实现真正的意义上的双活,就要求网络、应用、数据库都要双活。就现阶段来看,大多数客户的多数据中心的模型可以归纳为以下几种:
主备容灾正常情况下只有主数据中心投入运行,备数据中心处于待命状态。发生灾难时,灾备中心可以短时间内恢复对外数据访问,减轻灾难带来的损失。这种模式只能解决业务连续性的需求,单用户无法就近快速接入。灾备中心投资巨大且运维成本高昂,正常情况下灾备中心不对外提供数据服务,资源利用率偏低,造成巨大浪费。 互备方式客户根据业务分类或者针对不同的应用设置不同的数据访问策略,部分业务以数据中心A为主,数据中心B为热备,而部分业务则以数据中心B为主,数据中心A为热备,已达到近似双活的效果。
双活并行方式业务系统可以同时在数据中心A和数据中心B访问,无需特殊指定访问数据规则,可以实现数据访问的负载均衡,数据库故障自动切换,数据库发生故障时对业务实现“0”感知。
3
业务目标
同城双中心容灾的主要建设目标可以归纳为以下几点:
流量分发:同城双中心具备流量分发功能,当主中心流量太大、负载太高时,可以把流量分发到容灾中心、业务系统也可根据业务的特性动态的把数据请求分发到不同的中心。
故障切换:当同城双中心内的网络、硬件、系统出现问题时,运维人员可第一时间获悉故障情况,中心内的各个节点实现自动主备切换,保证业务系统访问的连续性,实现数据库系统的RPO=0,RTO=0。
环境一致性:同城双中心对应用来说应该是透明的,其对外服务时应提供统一接口,中心内部数据和服务能力需要完全一致,且随时处于可切换状态。
4
传统同城双中心容灾方案
传统的同城数据双中心容灾方案主要有下两种:
4.1 基于数据层
首先讲数据层(这里指传统的数据库)中的同城双中心,一种叫做 Active Standby方式,一种方式为两个都是Active方式,此外还有数据逻辑复制软件模式。
4.2 基于存储层存储层作为双中心系统基础架构平台,其双活技术在整个架构中也有广泛的应用,目前基于存储层的双中心方案有以下几种:
5
分布式同城双中心容灾方案
SequoiaDB分布式同城双中心容灾解决方案是指两个数据中心均处于运行状态、是真正的AA(Active Active)双活容灾解决方案。主中心和灾备中心可以同时承担生产业务,确保数据库系统发生设备故障、甚至单数据中心故障时,业务无感知、自动切换,实现RPO(Recovery Point Objective)=0,RTO(Recovery Time Objective)=0(RTO与应用系统及部署方式有关)。
5.1 逻辑架构
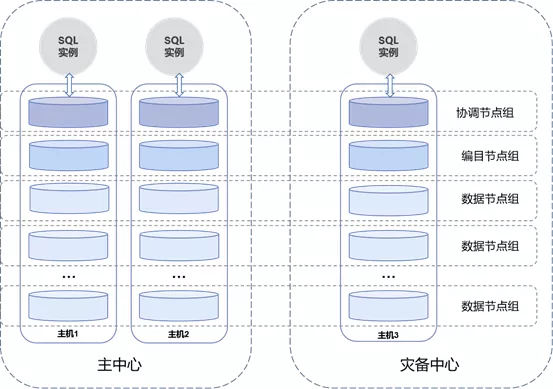
上图为SequoiaDB分布式同城双中心逻辑架构图。架构分为两层,上层SQL实例层,下层为数据存储层。SequoiaDB分布式数据库利用计算-存储层分离架构,将协议解析、计算等模块与底层存储解耦。存储层通过多副本技术将编目节点与数据节点所存放的数据以节点为单位进行复制、多维分区实现弹性扩张,计算层采用无状态设计,独立部署,通过动态增加数据库实例线性提升计算能力,有效应对瞬时爆发的高并发海量交易,分布式数据库平台上层SQL实例层同时完整兼容Mysql、PosgreSQL和sparkSQL针对应用提供较高兼容性。
5.2 部署方案

SequoiaDB分布式同城双中心部署方案如上图,采用“2+1”三副本架构,方案为三层:
第一层:负载均衡层,通过F5或Nginx实现负载均衡,对外业务访问提供统一数据入口。
第二层:计算层,这一层提供多活高可用SQL实例,所有实例同时对外提供统一的数据访问接口,实例之间是对等状态。SQL实例只是负责解析SQL、生成执行计划,自己不存储业务数据,这样可以实现水平动态的扩展SQL实例,提高SQL实例对外提供服务的能力。SQL实例层连接本机的协调节点,把解析后的SQL语句直接下发给节点。
第三层:SequoiaDB分布式存储引擎层,这一层是同城双中心容灾的核心层。采用三副本(“2+1”模式,主节点部署2个副本,灾备中心部署1个副本)部署方案。存储引擎层包括3类复制组,如下:1)协调节点组协调节点组内的节点都是主节点,协调节点之间没有主备模式,协调节点作为外部访问的接入与请求分发节点,协调节点将用户请求分发至相应的数据节点,最终合并数据节点的结果应答对外进行响应。协调节点组内的节点实现多活高可用。SequoiaDB分布式存储引擎可以部署多组协调节点组。2)编目节点组编目节点组内有多个编目节点,编目节点之间是以1主2备的方式,编目节点存储了系统的节点信息、用户信息、分区信息以及对象定义等元数据。编目节点组内的编目节点采用数据强一致同步,这样保证了元数据的一致性。3)数据节点组数据节点组内有多个数据节点,数据节点为用户数据的物理存储节点。组内的数据是以多副本方式存储。节点之间是以1主2备的方式,主节点可提供读写服务,备节点可提供读服务,数据节点之间可以实现数据的强一致或者最终一致性。用户可以按业务等级来设置数据节点之间的同步策略。
5.3 故障场景模拟
1)SQL实例层
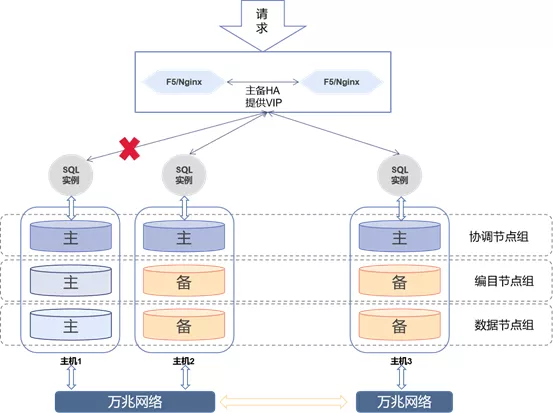
如上图,当主机1的SQL实例故障,负载均衡会自动把所有的请求分发到主机2和主机3的SQL实例。
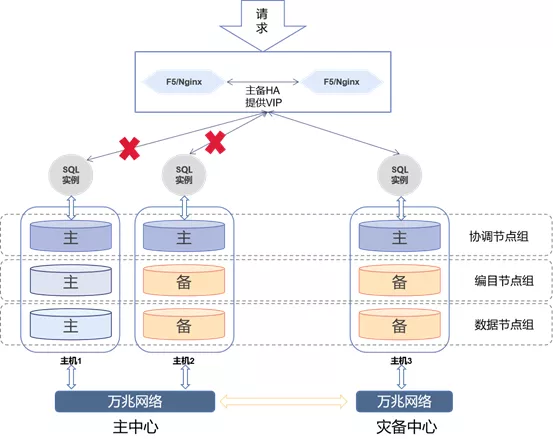
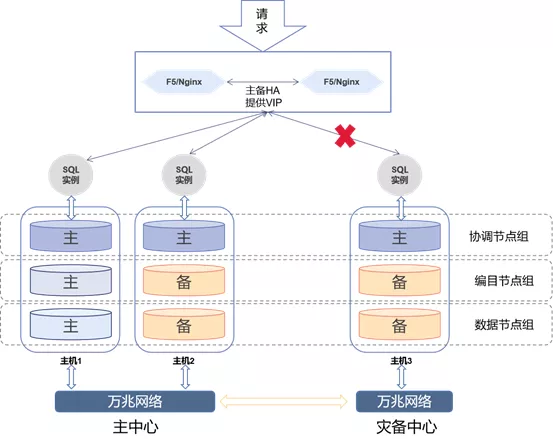
如上图,当灾备中心SQL实例故障,负载均衡会自动把所有的请求分发到主中心的SQL实例。
2)存储引擎层
协调节点组故障
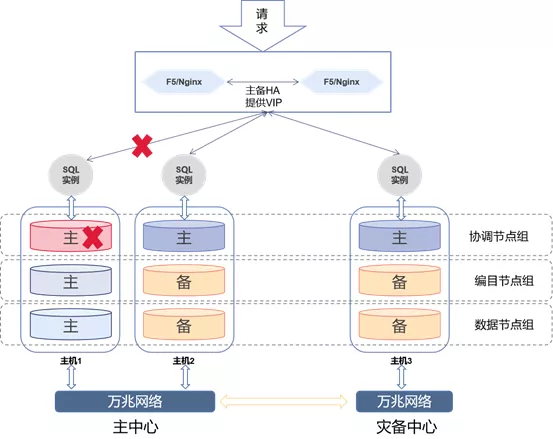
当主中心主机1的协调节点故障时,负载均衡会根据SQL实例返回的错误,自动把所有的请求发送到另外两个SQL实例。
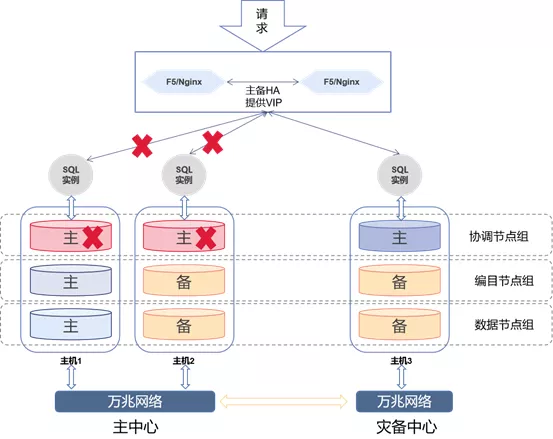
当主中心所有的协调节点故障时,负载均衡会根据SQL实例返回的错误,自动把所有的请求发送到灾备中心SQL实例。
编目节点组故障
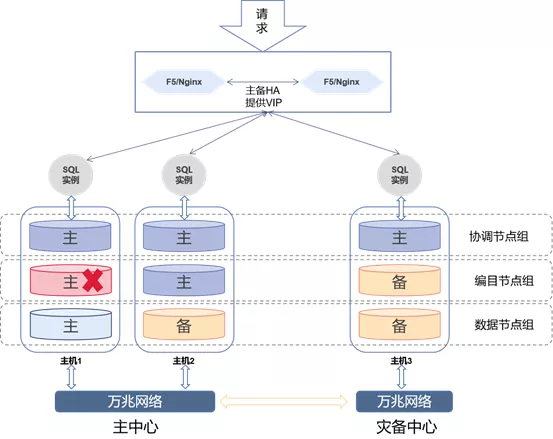

当主中心任意一个数据节点出现故障时,剩余两个数据节点会自动选主,新的主节点对外提供读写服务,备节点可提供读服务。
整个主中心故障

当主中心的所有节点都发生故障时,此时可把分布式存储集群分离为两个集群,把中心的两个节点踢出集群,此时的灾备中心接管所有的数据访问。
6
关键技术
6.1 分布式事务
SequoiaDB 巨杉数据库支持强一致分布式事务功能。利用二段提交机制,SequoiaDB 巨杉数据库在分布式存储引擎实现了对结构化与半结构化数据的强一致分布式事务功能,不论用户创建哪种数据库实例,其底层均可提供完整的分布式事务及锁能力。
6.2 故障切换
SequoiaDB 巨杉数据库提供多副本架构,复制组内的副本通过强一致或者最终一致性,使复制组内的副本的数据保持一致,当任意一个或者多个副本放生故障时,复制组内的节点可以自动主备切换,不会丢失数据,从而对应用来说可以实现“0”感知。复制组内的节点通过RAFT算法实现。
6.3 集群分离
SequoiaDB 巨杉数据多副本架构构成了一个分布式数据库集群,可以把故障的节点踢出整个集群,使剩下的节点单独组成一个集群对外提供服务。
6.4 数据一致性
SequoiaDB 巨杉数据库提供多副本架构,复制组内的副本通过日志方式进行副本间的数据同步,日志文件记录数据变化,即增删改造成的数据变化。每个数据节点分别记录本节点内的日志变化,在数据节点和编目节点中,任何数据增删改操作均会写入日志。SequoiaDB会首先将日志写入日志缓冲区,然后将其异步写入本地磁盘。
SequoiaDB中,对于复制组间的数据采用“强一致性”或“最终一致性”策略,用户可以根据业务需求设置数据一致性策略。默认情况下,复制组中的主节点在处理完一个写请求后会立即返回,即 W = 1。数据同步会在后台异步完成,并达到最终一致。此时外部的读请求获得的数据可能不是最新的。在对数据一致性要求不高的场景中,这种方式可以提供最优的写入性能。如果业务对数据一致性要求很高,可以设置W = “副本数”,这样复制组中的主节点在处理完一个写请求并且所有的备节点都处理成功了才会返回信息,达到复制组内数据一致性。在很多业务场景中,我们可以设置 W=(副本数/2)+1的值即可,这样保证了多数副本数据一致性,这样既提高了数据的安全性也不至于对性能造成太大影响。
--结束END--
本文标题: 巨杉Tech | SequoiaDB的同城双中心容灾实践
本文链接: https://lsjlt.com/news/5743.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0