前言 文章首发于微信公众号【码猿技术专栏】。 在实际的开发中一定会碰到根据某个字段进行排序后来显示结果的需求,但是你真的理解order by在 Mysql 底层是如何执行的吗? 假设你要查询城市是苏州的所有人名字,并且按照姓名进
order by在 Mysql 底层是如何执行的吗?苏州的所有人名字,并且按照姓名进行排序返回前 1000 个人的姓名、年龄,这条 sql 语句应该如何写?CREATE TABLE user (
id int(11) NOT NULL,
city varchar(16) NOT NULL,
name varchar(16) NOT NULL,
age int(11) NOT NULL,
PRIMARY KEY (id),
KEY city (city)
) ENGINE=InnoDB;select city,name,age from user where city="苏州" order by name limit 1000;city这个字段上添加了索引,当然城市的字段很小,不用考虑字符串的索引问题,之前有写过一篇关于如何给字符串的加索引的文章,有不了解朋友看一下这篇文章:Mysql 性能优化:如何给字符串加索引?Explain来分析一下的这条查询语句的执行情况,结果如下图: 
Extra这个字段中的Using filesort表示的就是需要排序,MySQL 会给每个线程分配一块内存用于排序,称为sort_buffer。city这棵索引树的结构,如下图: 
city="苏州"是从ID3到IDX这些记录。全字段排序,执行的流程图如下: 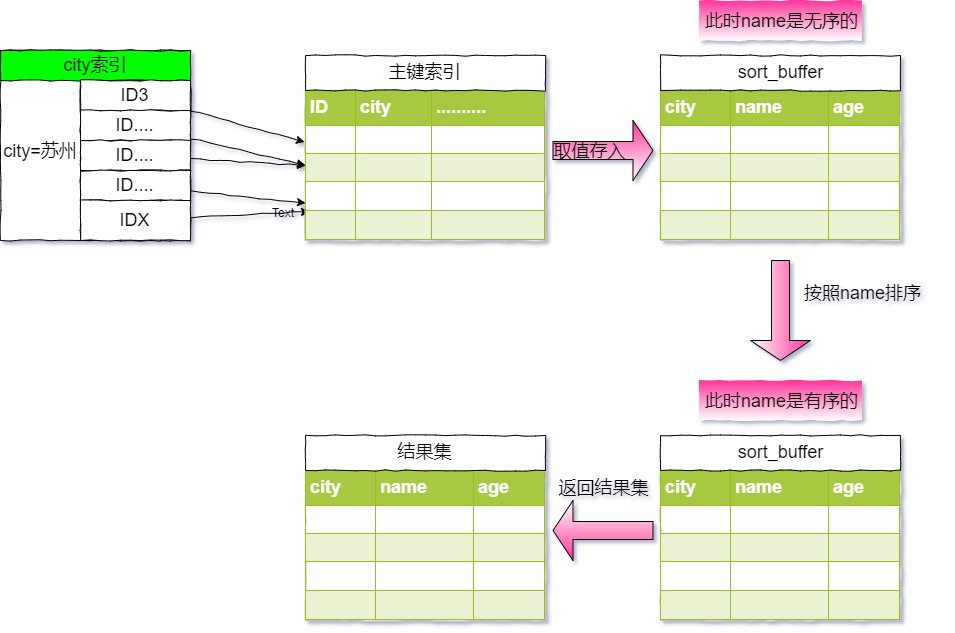
city="苏州"条件的主键id,也就是图中的ID3。主键id索引取出整行,取name、city、age三个字段的值,存入sort_buffer中。city取下一个记录的主键 id。IDX。sort_buffer中的数据按照字段name做快速排序。按name排序这个动作,可能在内存中完成,也可能需要使用外部排序,这取决于排序所需的内存和参数sort_buffer_size。sort_buffer_size:就是 MySQL 为排序开辟的内存(sort_buffer)的大小。如果要排序的数据量小于 sort_buffer_size,排序就在内存中完成。但如果排序数据量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。sort_buffer和临时文件中执行的。但这个算法有一个问题,就是如果查询要返回的字段很多的话,那么sort_buffer里面要放的字段数太多,这样内存里能够同时放下的行数很少,要分成很多个临时文件,排序的性能会很差。max_length_for_sort_data这个参数使其使用另外一种算法。max_length_for_sort_data,是 MySQL 中专门控制用于排序的行数据的长度的一个参数。它的意思是,如果单行的长度超过这个值,MySQL 就认为单行太大,要换一个算法。city、name、age 这三个字段的定义总长度是36,我把max_length_for_sort_data设置为 16,我们再来看看计算过程有什么改变。设置的 sql 语句如下:SET max_length_for_sort_data = 16;新的算法放入 sort_buffer 的字段,只有要排序的列(即 name 字段)和主键 id。
但这时,排序的结果就因为少了 city 和 age 字段的值,不能直接返回了,整个执行流程就变成如下所示的样子:
sort_buffer,确定放入两个字段,即name和id。city="苏州"条件的主键id,也就是图中的ID3。主键id索引取出整行,取 name、id 这两个字段,存入 sort_buffer 中。city取下一个记录的主键 id。IDX。sort_buffer中的数据按照字段name做快速排序。这个执行流程的示意图如下,我把它称为rowid排序。 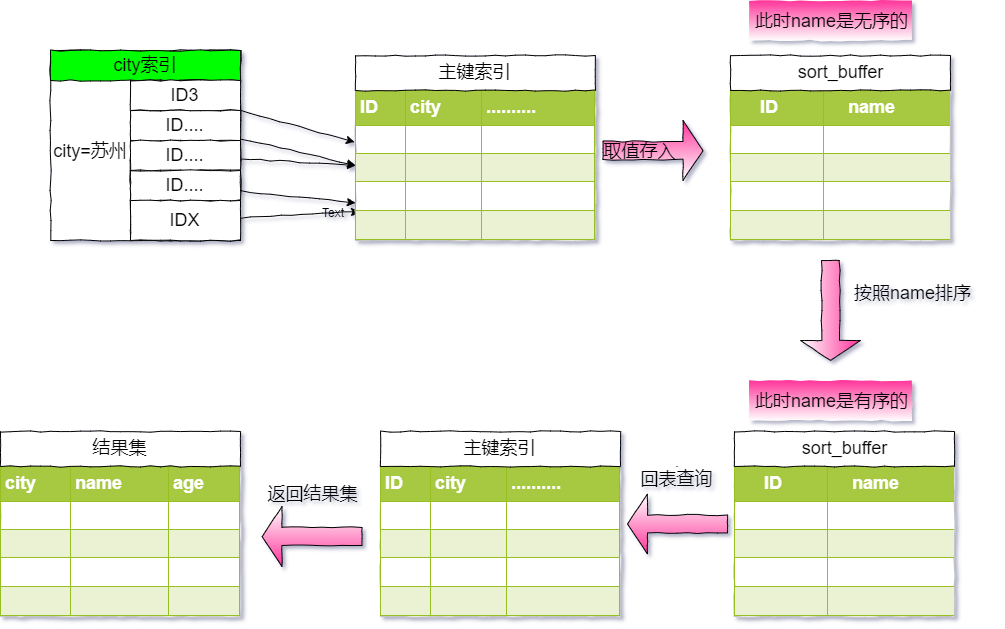
对比全字段排序,rowid排序多了一次回表查询,即是多了第7步的查询主键索引树。
order by语句,都需要排序操作的。从上面分析的执行过程,我们可以看到,MySQL 之所以需要生成临时表,并且在临时表上做排序操作,其原因是原来的数据都是无序的。city这个索引上取出来的行,天然就是按照 name 递增排序的话,是不是就可以不用再排序了呢?(city,name)联合索引,sql 语句如下:alter table user add index city_user(city, name);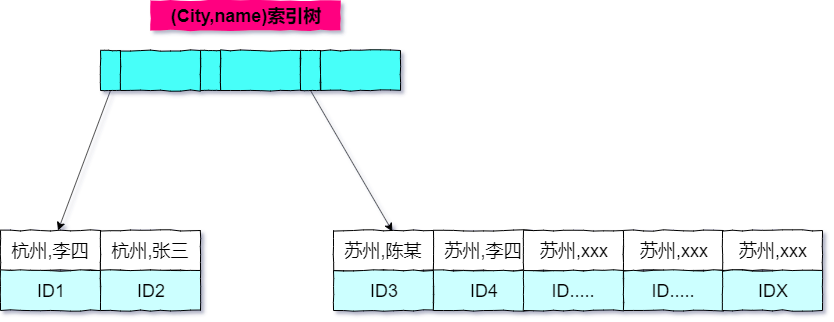
city="苏州"的记录,并且额外确保了,接下来按顺序取“下一条记录”的遍历过程中,只要 city 的值是杭州,name 的值就一定是有序的。

Extra字段中没有Using filesort了,也就是不需要排序了。而且由于(city,name)这个联合索引本身有序,所以这个查询也不用把 4000 行全都读一遍,只要找到满足条件的前 1000 条记录就可以退出了。也就是说,在我们这个例子里,只需要扫描 1000 次。
(city,name,age)联合索引,这样在执行上面的查询语句就能使用覆盖索引了,避免了回表查询了,sql 语句如下:alter table user add index city_user_age(city, name, age);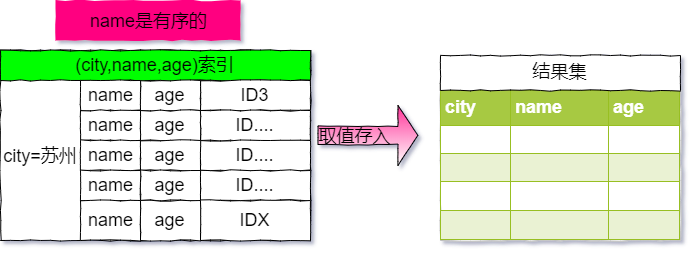
order by语句的几种算法流程。--结束END--
本文标题: 天天写order by,你知道Mysql底层执行原理吗?
本文链接: https://lsjlt.com/news/5508.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0