本文讨论一下join技术背后的机制。我们知道常用的表连接有如下几种笛卡尔连接内连接左外连接右外连接全连接这些sql的写法,想必大家都很清楚了,那么这些连接的数据访问是如何实现的呢?nested
本文讨论一下join技术背后的机制。我们知道常用的表连接有如下几种
笛卡尔连接
内连接
左外连接
右外连接
全连接
这些sql的写法,想必大家都很清楚了,那么这些连接的数据访问是如何实现的呢?
nested loop
我们看如下查询
SQL> alter session set optimizer_mode=rule;
Session altered.
SQL> select ename,dname from emp,dept where emp.deptno=dept.deptno;
14 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 3625962092
------------------------------------------------
| Id | Operation | Name |
------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | NESTED LOOPS | |
| 2 | NESTED LOOPS | |
| 3 | TABLE ACCESS FULL | EMP |
|* 4 | INDEX UNIQUE SCAN | PK_DEPT |
| 5 | TABLE ACCESS BY INDEX ROWID| DEPT |
------------------------------------------------
Predicate InfORMation (identified by operation id):
---------------------------------------------------
4 - access("EMP"."DEPTNO"="DEPT"."DEPTNO")根据我们之前讲的执行计划解读,本查询是这样实现的:
全表扫描emp表(非阻塞扫描,并不是将数据全部取出,才执行下一步)。
将emp中的数据逐条取出,通过索引PK_DEPT查询出索引中的rowid,结果集变成(ename,rowid)
将2生成的结果集逐条取出,通过rowid去访问dept表,结果集变成(ename,dname)
将结果集返回。
这种以循环的方式取出数据的join实现方式就叫嵌套循环。
此计划可以用如下逻辑伪代码实现
for y in (for x in (select * from emp)loop
index lookup the rowid for x.deptno
output joined record(ename,dept.rowid)
end loop)loop
select * from dept where rowid=y.rowid
output joined record(ename,dname)
end loop我们把emp表称之为驱动表(注驱动表与from子句的表顺序无关,主要看执行计划)。
此种连接方式,适用于驱动表返回数据比较少,并且被驱动表dept上deptno列有索引。如果查询返回n行,那么dept表将被扫描n次。此连接擅长于从结果集中迅速取出第一行。
Hash Join
Hash Join适合处理大型结果集,优化器选择两个表或者源数据中比较小的,使用join key在内存中建立一个hash table。然后扫描大表,并探查hash表,去发现匹配的记录。
小表称为驱动表,大表称为探查表
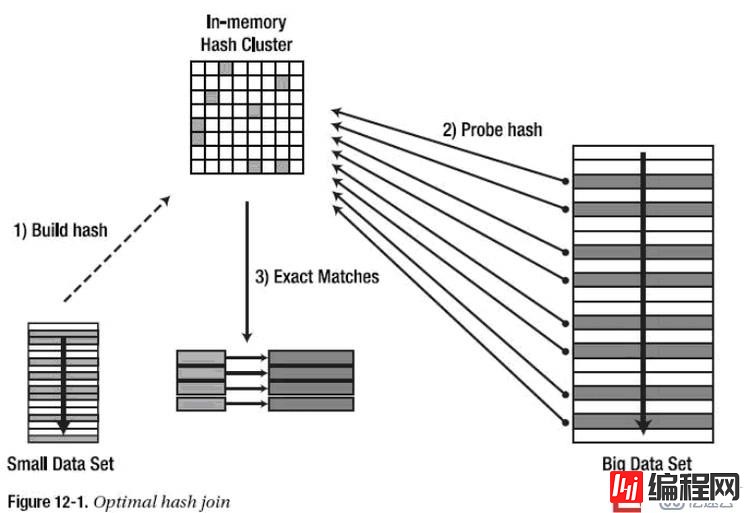
当hash table能全部放到内存中,此种情况最好。如果内存中放不下hash table,优化器将hash table分区,超出内存范围的分区将被写到临时表空间中。
我们分两种情况讨论hash join的实现
hash table 全部在内存里
hash table是oracle根据join key利用一个hash函数将小表分割成多个bucket。hash table建立完成后,Oracle去扫描大表,并且采用相同的hash算法,将读入的数据也分割成多个bucket。bucket与bucket之间进行join运算,返回结果。直到大表读完为止。
2. hash table 不能全部放到内存中
这种情况有点麻烦,当Oracle发现内存无法完全存放小表,Oracle在构造hash table时,将小表进行分区,每个分区中再构造bucket 。当内存写满时,Oracle将内存中最大的分区写到tempfile中。用这个方法,直到小表hash table构造完成。此时,hashtable一部分数据在内存,一部分数据在tempfile。
当Oracle去扫描大表时,如果扫描的行通过hash在内存中能找到结果,就匹配成功。如果不能命中,则采用与hash table相同的分区方式,先将数据写入tempfile中。当大表全部扫描完毕,hash table内存中的部分已全部匹配完。此时依次将tempfile中的分区加载到内存中。重新扫描大表临时存在tempfile中的相应分区加以匹配。直到数据全部处理完。
SQL> insert into big_emp select * from big_emp;
SQL> insert into big_emp select * from big_emp;#重复执行多次
SQL> /
458752 rows created.
SQL> create table dept_new as select * from dept;
Table created.
SQL> set autot traceonly
SQL> select * from big_emp a,dept_new b where a.deptno=b.deptno;
917504 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 1925493178
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 917K| 54M| 1490 (2)| 00:00:18 |
|* 1 | HASH JOIN | | 917K| 54M| 1490 (2)| 00:00:18 |
| 2 | TABLE ACCESS FULL| DEPT_NEW | 4 | 120 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| BIG_EMP | 917K| 28M| 1482 (1)| 00:00:18 |
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("A"."DEPTNO"="B"."DEPTNO")
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
4 recursive calls
1 db block gets
66338 consistent gets
0 physical reads
0 redo size
62512398 bytes sent via SQL*Net to client
673349 bytes received via SQL*Net from client
61168 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
917504 rows processedSort Merge Joins
排序合并连接与嵌套循环和散列连接都不同,排序合并连接没有驱动表的概念。简言之,排序合并将依次处理排序第一个输入集,排序第二个输入集,然后合并结果。排序合并通常不如散列高效,因为两个结果集都需要排序,而散列连接在数据输出前,只需处理一个结果集。排序合并通常在非等值连接中有效。即连接条件不是一个等式而是范围比较(<或者>=). 或者是两个表的数据已经排好序啦。
我们看如下例子
SQL> set linesize 200 pagesize 200
SQL> set autot traceonly
SQL> select a.ename,b.ename,a.hiredate,b.hiredate
2 from emp a,emp b
3 where a.empno<>b.empno and a.hiredate<b.hiredate;
90 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 3733349388
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 84 | 3024 | 8 (25)| 00:00:01 |
| 1 | MERGE JOIN | | 84 | 3024 | 8 (25)| 00:00:01 |
| 2 | SORT JOIN | | 14 | 252 | 4 (25)| 00:00:01 |
| 3 | TABLE ACCESS FULL | EMP | 14 | 252 | 3 (0)| 00:00:01 |
|* 4 | FILTER | | | | | |
|* 5 | SORT JOIN | | 14 | 252 | 4 (25)| 00:00:01 |
| 6 | TABLE ACCESS FULL| EMP | 14 | 252 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter("A"."EMPNO"<>"B"."EMPNO")
5 - access("A"."HIREDATE"<"B"."HIREDATE")
filter("A"."HIREDATE"<"B"."HIREDATE")
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
12 consistent gets
0 physical reads
0 redo size
3500 bytes sent via SQL*Net to client
578 bytes received via SQL*Net from client
7 SQL*Net roundtrips to/from client
2 sorts (memory)
0 sorts (disk)
90 rows processed再看一个等值连接的
SQL> select ename,dname from emp a,dept b where a.deptno=b.deptno;
14 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 844388907
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 308 | 6 (17)| 00:00:01 |
| 1 | MERGE JOIN | | 14 | 308 | 6 (17)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| DEPT | 4 | 52 | 2 (0)| 00:00:01 |
| 3 | INDEX FULL SCAN | PK_DEPT | 4 | | 1 (0)| 00:00:01 |
|* 4 | SORT JOIN | | 14 | 126 | 4 (25)| 00:00:01 |
| 5 | TABLE ACCESS FULL | EMP | 14 | 126 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("A"."DEPTNO"="B"."DEPTNO")
filter("A"."DEPTNO"="B"."DEPTNO")
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
10 consistent gets
0 physical reads
0 redo size
819 bytes sent via SQL*Net to client
523 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
14 rows processed
--结束END--
本文标题: Oracle 学习之性能优化(七)join的实现方式
本文链接: https://lsjlt.com/news/52677.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0