前言 为了避免单点故障,我们需要将数据复制多份部署在多台不同的服务器上,即使有一台服务器出现故障其他服务器依然可以继续提供服务 作用: 数据备份 扩展读性能(读写分离) 复制方式: 全量复制 部分复制 实现方式 1、一主二

为了避免单点故障,我们需要将数据复制多份部署在多台不同的服务器上,即使有一台服务器出现故障其他服务器依然可以继续提供服务
作用:
数据备份
扩展读性能(读写分离)
复制方式:
全量复制
部分复制
1、一主二扑 A(B、C) 一个Master两个Slave
2、薪火相传(去中心化) A-B-C,B既是主节点(C的主节点),又是从节点(A的从节点)
3、反客为主(主节点down掉后,手动操作升级从节点为主节点)
4、哨兵模式(后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库)

配置:
Master:6379端口
requirepass 123456
slave1: 6380端口
port 6380
slaveof 127.0.0.1 6379
masterauth 123456
Slave2: 6381端口
port 6381
slaveof 127.0.0.1 6379
masterauth 123456
启动
开启Master
Redis-server.exe redis.windows.conf
开启slave1
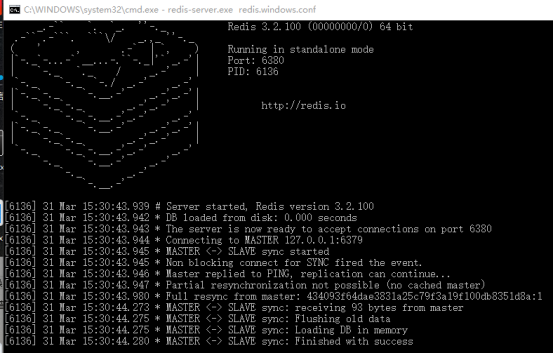
开启slave2

查看master

连接三个redis
向master写入数据

查看slave1

可能出现的问题
启动服务,127.0.0.1java.net.SocketTimeoutException:connect time out超时和ping不通端口
解决:关闭防火墙
哨兵模式的任务:
监控(Monitoring):Sentinel会不断地检查你的主服务器和从服务器是否允许正常。
提醒(Notification):当被监控的某个Redis服务器出现问题时,Sentinel可以通过api向管理员或者其他应用程序发送通知。
自动故障迁移(Automatic failover):
(1)当一个主服务器不能正常工作时,Sentinel会开始一次自动故障迁移操作,他会将失效主服务器的其中一个从服务器升级为新的主服务器,并让失效主服务器的其他从服务器改为复制新的主服务器;
(2)客户端试图连接失败的主服务器时,集群也会向客服端返回新主服务器的地址,是的集群可以使用新主服务器代替失效服务器
新建配置sentinel.conf
三个redis配置只有端口port不一样
#端口区别不同
#当前Sentinel服务运行的端口
port 26379
# 哨兵监听的主服务器 mymaster名称(可以自定义),1票
sentinel monitor mymaster 127.0.0.1 6379 1
sentinel auth-pass mymaster 123456
# 10s内mymaster无响应,则认为master宕机了
sentinel down-after-milliseconds mymaster 10000
#如果20秒后,mysater仍没启动过来,则启动failover
sentinel failover-timeout mymaster 20000
# 执行故障转移时, 最多有1个从服务器同时对新的主服务器进行同步,数字越小, 完成故障转移所需的时间就越长
sentinel parallel-syncs mymaster 1
bind 127.0.0.1
protected-mode yes
可能出现的问题
redis 主从切换失败

[12248] 31 Mar 17:09:26.726 # +try-failover master mymaster 127.0.0.1 6379
[12248] 31 Mar 17:09:26.728 # +vote-for-leader 2fe3a13e25190364c193e71b6d89257323D694ce 11
[12248] 31 Mar 17:09:26.728 # +elected-leader master mymaster 127.0.0.1 6379
[12248] 31 Mar 17:09:26.728 # +failover-state-select-slave master mymaster 127.0.0.1 6379
[12248] 31 Mar 17:09:26.803 # -failover-abort-no-Good-slave master mymaster 127.0.0.1 6379
[12248] 31 Mar 17:09:26.864 # Next failover delay: I will not start a failover before Tue Mar 31 17:10:17 2020
[12248] 31 Mar 17:10:17.170 # +new-epoch 12
[12248] 31 Mar 17:10:17.171 # +try-failover master mymaster 127.0.0.1 6379
[12248] 31 Mar 17:10:17.179 # +vote-for-leader 2fe3a13e25190364c193e71b6d89257323d694ce 12
[12248] 31 Mar 17:10:17.179 # +elected-leader master mymaster 127.0.0.1 6379
[12248] 31 Mar 17:10:17.181 # +failover-state-select-slave master mymaster 127.0.0.1 6379
[12248] 31 Mar 17:10:17.265 # -failover-abort-no-good-slave master mymaster 127.0.0.1 6379
[12248] 31 Mar 17:10:17.349 # Next failover delay: I will not start a failover before Tue Mar 31 17:11:07 2020
[12248] 31 Mar 17:11:07.279 # +new-epoch 13
[12248] 31 Mar 17:11:07.279 # +try-failover master mymaster 127.0.0.1 6379
[12248] 31 Mar 17:11:07.284 # +vote-for-leader 2fe3a13e25190364c193e71b6d89257323d694ce 13
[12248] 31 Mar 17:11:07.285 # +elected-leader master mymaster 127.0.0.1 6379
[12248] 31 Mar 17:11:07.288 # +failover-state-select-slave master mymaster 127.0.0.1 6379
[12248] 31 Mar 17:11:07.351 # -failover-abort-no-good-slave master mymaster 127.0.0.1 6379
[12248] 31 Mar 17:11:07.443 # Next failover delay: I will not start a failover before Tue Mar 31 17:11:57 2020
问题是:配置错误重新配置
分别启动三个哨兵
redis-server.exe sentinel.conf --sentinel
关闭mster

查看
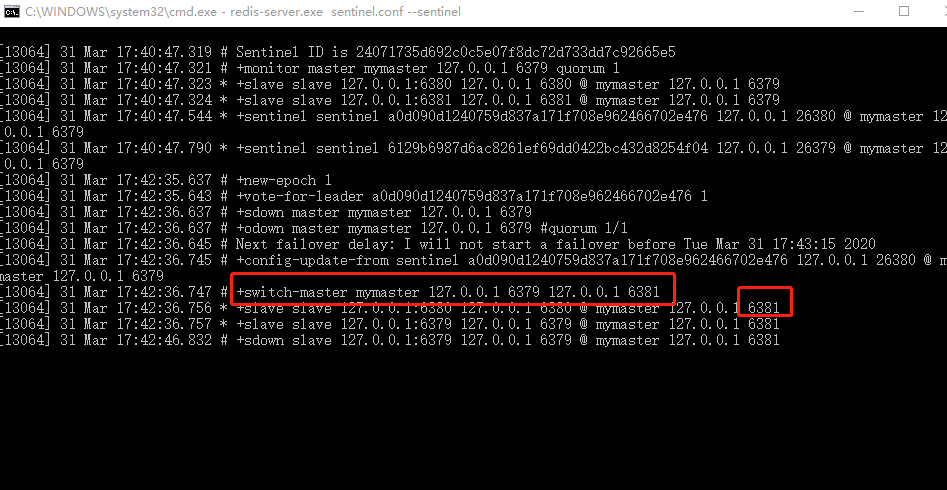
slave2(6381)升为master
重新开启之前的master(6379),这时候master还是之前的slave2(6381)
配置源码地址
读写分离
复制数据存在延迟(如果从节点发生阻塞)
从节点可能发生故障
主从配置不一致
例如maxmemory不一致,可能会造成丢失数据
规避全量复制
第一次全量复制不可避免,所以分片的maxmemory减小,同时选择在低峰(夜间)时,做全量复制。
复制积压缓冲区不足
增大复制缓冲区配置rel_backlog_size
例如如果网络中断的平均时间是60s,而主节点平均每秒产生的写命令(特定协议格式)所占的字节数为100KB,则复制积压缓冲区的平均需求为6MB,保险起见,可以设置为12MB,来保证绝大多数断线情况都可以使用部分复制。
复制风暴
master节点重启,master节点生成一份rdb文件,但是要给所有从节点发送rdb文件。对cpu,内存,带宽都造成很大的压力
参考:https://www.jianshu.com/p/4aa9591c3153
--结束END--
本文标题: redis笔记-
本文链接: https://lsjlt.com/news/5250.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0