InnoDB是在Mysql存储引擎中第一个完整支持ACID事务的引擎,该引擎之前由Innobase OY公司所开发,后来该公司被oracle收购。InnoDB是mysql数据库中使用最广泛的存储引擎,已被许
InnoDB是在Mysql存储引擎中第一个完整支持ACID事务的引擎,该引擎之前由Innobase OY公司所开发,后来该公司被oracle收购。InnoDB是mysql数据库中使用最广泛的存储引擎,已被许多大型公司所采用,如Google、Facebook、YouTube等,如果使用Mysql数据库服务,没有特殊的要求下,InnoDB是不二之选。
1.InnoDB体系架构
需要深入了解InnoDB先从了解InnoDB的体系架构开始,如下图所示:
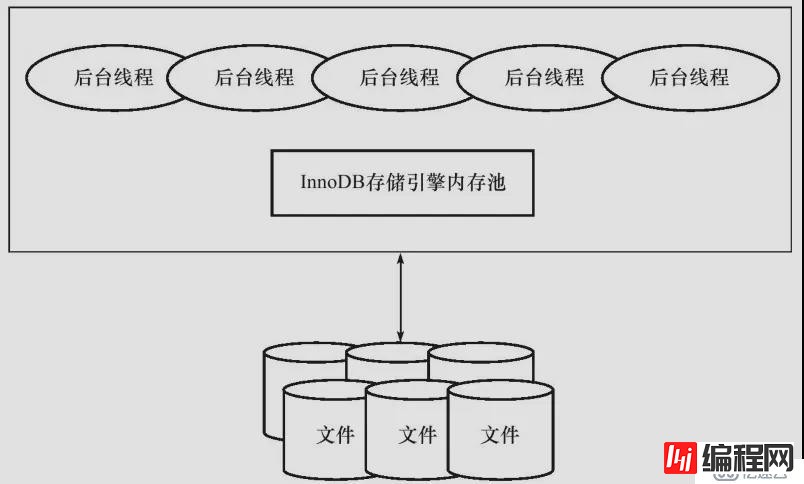
InnoDB存储引擎有多个内存块,可以认为这些内存块组成了一个大的内存池,负责以下几个工作:
维护所有进程/线程,需要访问的多个内部数据结构;
缓存磁盘上的数据,方便快速地读取,同时在对磁盘文件的数据修改之前在这里缓存;
重做日志(redo log)缓冲(简单来讲,redo log记录的是事务所对应的数据更新日志,用于降低每次数据变更都产生的磁盘IO,该日志由工作线程定时把数据的更新内容定时刷新到磁盘中去,当数据库奔溃时数据还没来得及刷新到磁盘,重新启动运行是则可以从redo log里面重新提取刷新到磁盘,具体有关redo log在后面相关章节会详细介绍)。
后台线程的主要作用是负责刷新内存池中的数据,保证缓冲池中的内存缓冲的是最近的数据,此外除将已修改的数据文件刷新到磁盘中,同时保证在数据库发生异常的情况下InnoDB能恢复到正常运行状态。
2.后台线程
master thread
master thread是一个非常核心的后台线程,主要负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,包括脏页面的刷新、合并插入缓冲、undo页的回收等。
io thread
在InnoDB引擎中大量使用了Aio(Async IO)来处理写IO请求,这样可以极大提高数据库的性能。而io thread的主要工作就是负责这些IO请求的回调处理。可以使用命令show engine innodb status\G来观察io threa。

图片来自广东睿江云
从上图可以看到,有1个insert buffer线程;1个log线程;4个read线程;4个write线程。
purge thread
事务被提交后,其所使用的undo log(用于事务commit失败后回滚操作用)可能不在需要,因此需要purge线程来回收undo页。在InnoDB 1.1版本之前,purge thread在master thread中完成;而从InnoDB 1.1版本开始,purge操作独立到专门的线程执行,以减轻master thread压力,提升cpu使用率、提升引擎性能;从InnoDB 1.2版本开始,还支持多个purge thread以进一步加快undo页回收。
page cleaner thread
在InnoDB 1.2.x版本中引入,其作用是将之前版本中脏页面是刷新操作都放在独立的线程中完成,也是为了减轻master thread的压力,提升性能。
3.内存
缓冲池
InnoDB引擎的数据存储是基于磁盘的,把记录按照一定的格式记录在磁盘,但是由于CPU与磁盘的速度有较大的差别,因此引入了基于内存缓冲技术来提高数据库的性能。简单来讲,把要读取数据的磁盘内容先加载到内存缓冲区域,下次读取同样数据时先判断是否被缓冲区所缓存,如果缓存则从缓冲区读取内容;同样,当需要对数据进行修改时,不直接修改磁盘对应数据,而是先修改缓冲区域,然后通过一种叫checkpoint(具体后面会介绍)的机制把更新的数据刷新到磁盘。
因此对于InnoDB引擎来讲,缓冲池的设置变得尤其重要,可以通过innodb_buffer_pool_size参数进行设置。
虽然缓冲池是为了缓冲数据,但是缓冲池保存的数据类型不仅仅只有数据库的记录,有以下几种类型:索引页、数据页、undo页、插入缓冲(insert buffer)、自适应哈希索引、InnoDB存储的锁信息(lock info)、数据字典信息等。
从InnoDB 1.0.x版本开始,允许有多个缓冲池实例,每个页根据哈希值平均分配到不同缓冲池实例中,这样可以增加数据库的并发处理。具体多实例缓冲池本文不再详细展开描述,有兴趣者可以继续通过其它途径深入了解。
内存管理 LRU List、Free List、Flush List
通常来说,数据库中的内存缓冲区是通过LRU(Latest Recent Used,最近最少使用)算法来进行管理。即频繁使用的页在LRU列表的前端,而最少使用的页在LRU的尾端。当缓冲池不能存放新读取到的页时,将首先释放LRU列表尾端的页。
在InnoDB引擎中,缓冲池中页的大小默认是16KB,同样也是使用LRU算法来进行管理,稍有不同的是,引擎对传统的LRU算法进行了一些优化,当读取到新的页,但并不是直接插入到LRU列表的首部,而是插入到LRU列表的midpoint位置,这个位置可以通过参数innodb_old_blocks_pct控制,默认情况下这个数值是37,代表插入到LRU列表尾部的37%的位置。关于InnoDB下LRU的算法不在本文详细讲解,有兴趣的读者可以自行查阅相关资料。
介绍完LRU List,下面介绍Free List,Free列表保存的是空闲页,引擎需要从缓冲池中分页时,首先从Free列表中查找是否有空闲页,若有则把页从Free List获取然后删除放到LRU List中,同理当LRU List的页面需要淘汰时则重新加入到Free List。
在LRU列表中的页被修改后,程该页为脏页(dirty page),即缓冲池中的页和磁盘上的页数据产生了不一致,这时候数据库会通过checkpoint机制将脏页刷新回磁盘(关于checkpoint在下一节会介绍),而Flush List则是专门保存这些脏页的列表。
redo log重做日志
InnoDB存储引擎的内存区域除了缓冲池外,还有重做日志缓冲(redo log buffer)。InnoDB存储引擎首先将日志信息先放入到这个缓冲区,然后按一定的频率刷新到redo log文件中。在后面“文件”一章会详细描述各自文件及其作用,其中就包含了redo log,这里先不做过多的讲解。
额外的内存池
额外的内存池记录的是数据库内部需要用到的各种数据结构,比如记录缓冲池信息的、记录LRU、锁等,这块往往也会被忽略。
4.checkpoint
在前面的小结描述过,缓冲池设计的目的是为了协调CPU速度与磁盘速度的鸿沟,页的所有操作首先都是在缓冲池中完成的,如一条update、delete、insert语句改变了页中的记录,那么此时此页是脏的,数据库需要把页的数据更新到磁盘中。
如果每一次变化都立刻更新到磁盘,那么这个效率会非常大,也失去了缓冲池的意义,但是如果长时间不刷新又会导致数据库崩溃时刻无法及时把数据更新到磁盘而出现数据的不一致性。
为了避免这些问题,当前事务型的数据库普遍都采用了wirte ahead log的策略,即当事务提交的时候,先写redo log,再修改页,如果期间发生宕机了可以通过redo log进行数据恢复。
checkpoint技术就是用于记录redo log里面,那些log已经刷新到磁盘了,那些log还没刷新,在InnoDB引擎里面,其checkpoint标记是通过一个叫LSN(log sequence number)来标记,LSN是一个8字节的数字,LSN之前的log都是已经被刷新到磁盘了,之后都是未被刷新的,所以当数据库宕机恢复的时候,只需要把LSN之后的redo log进行刷新即可。
5.InnoDB关键特性
InnoDB存储引擎的关键特性包括:
插入缓冲(insert buffer)
两次写(double write)
自适应哈希索引(adaptive hash index)
异步io(async io)
刷新邻接页(flush neighbor page)
下面只选取其中一些比较好理解的特性来简单介绍,其他比较复杂的如插入缓冲、自适应哈希索引留待读者自行去做详细的研究。
两次写
顾名思义,就是写两次的意思,在InnoDB引擎中,有个叫共享表空间,这个空间可以存放一些共享的数据,比如索引等信息,当数据库需要把一个缓冲池的页刷新到磁盘时,先把页数据写入到共享表空间,然后再写入磁盘,当写入磁盘发现异常导致数据丢失了,这时候从共享表空间把数据恢复重新写入磁盘。
异步io
简单来讲,异步io就是把io操作变成异步的方式,比如需要对磁盘进行读写,则先发起一个io操作,等待磁盘读写完成后再通知上层进行处理,异步io还有一个好处是可以对一些io操作进行合并优化,比如可以对连续页的请求进行合并成一次请求等。
刷新邻接页
这个也是比较好理解的,就是当刷新一个脏页时,InnoDB存储引擎会检测该页所在的区的所有页,如果都是脏页,那么一起进行刷新,可以借助异步io进行多个写操作的合并,提升效率。
--结束END--
本文标题: InnoDB存储引擎
本文链接: https://lsjlt.com/news/51983.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0