第一个就是使用优化查询的方法。这个在前期的内容中有具体说明,这里不再做说明。 第二、这里简要说明一个以下几个方法: 主从复制、读写分离、负载均衡 目前,大部分的主流关系型数据库都提供了主从复制的功能,通过配置两台(或多台)
第一个就是使用优化查询的方法。这个在前期的内容中有具体说明,这里不再做说明。
第二、这里简要说明一个以下几个方法:
主从复制、读写分离、负载均衡
目前,大部分的主流关系型数据库都提供了主从复制的功能,通过配置两台(或多台)数据库的主从关系,可以将一台数据库服务器的数据更新同步到另一台服务器上。网站可以利用数据库的这一功能,实现数据库的读写分离,从而改善数据库的负载压力。一个系统的读操作远远多于其写操作,因此写操作发向master,读操作发向slaves进行操作(简单的轮循算法来决定使用哪个slave)。
利用数据库的读写分离,WEB服务器在写数据的时候,访问著数据库(Master),主数据库通过主从复制机制将数据更新同步到从数据库(Slave),这样web服务器读数据的时候,就可以通过从数据库获得数据。这一方案使得在大量读操作的web应用可以轻松地读取数据,而主数据库也只会承受少量的写入操作,还可以实现数据热备份,可谓是一举两得的方案。
1.复制的基本原则
MySQL复制是异步的且串行化的;
每个Slave只有一个Master;
每个Slave只有一个唯一的服务器ID;
每个Master可以有多个Slave;
2.一主一从常见配置:
Mysql版本一致且后台以服务运行;
主从都配置在[mysqld]结点下,都是小写,主机修改my.ini配置文件,从机修改my.cnf配置文件,因修改过配置文件,请主机+从机都重启后台Mysql服务;
主机从机都关闭防火墙;
在windows主机上建立账户并授权slave;
在linux从机上配置需要复制的主机;
主机新建库,新建表,insert记录,从机复制;
通过stop slave 停止从机复制;
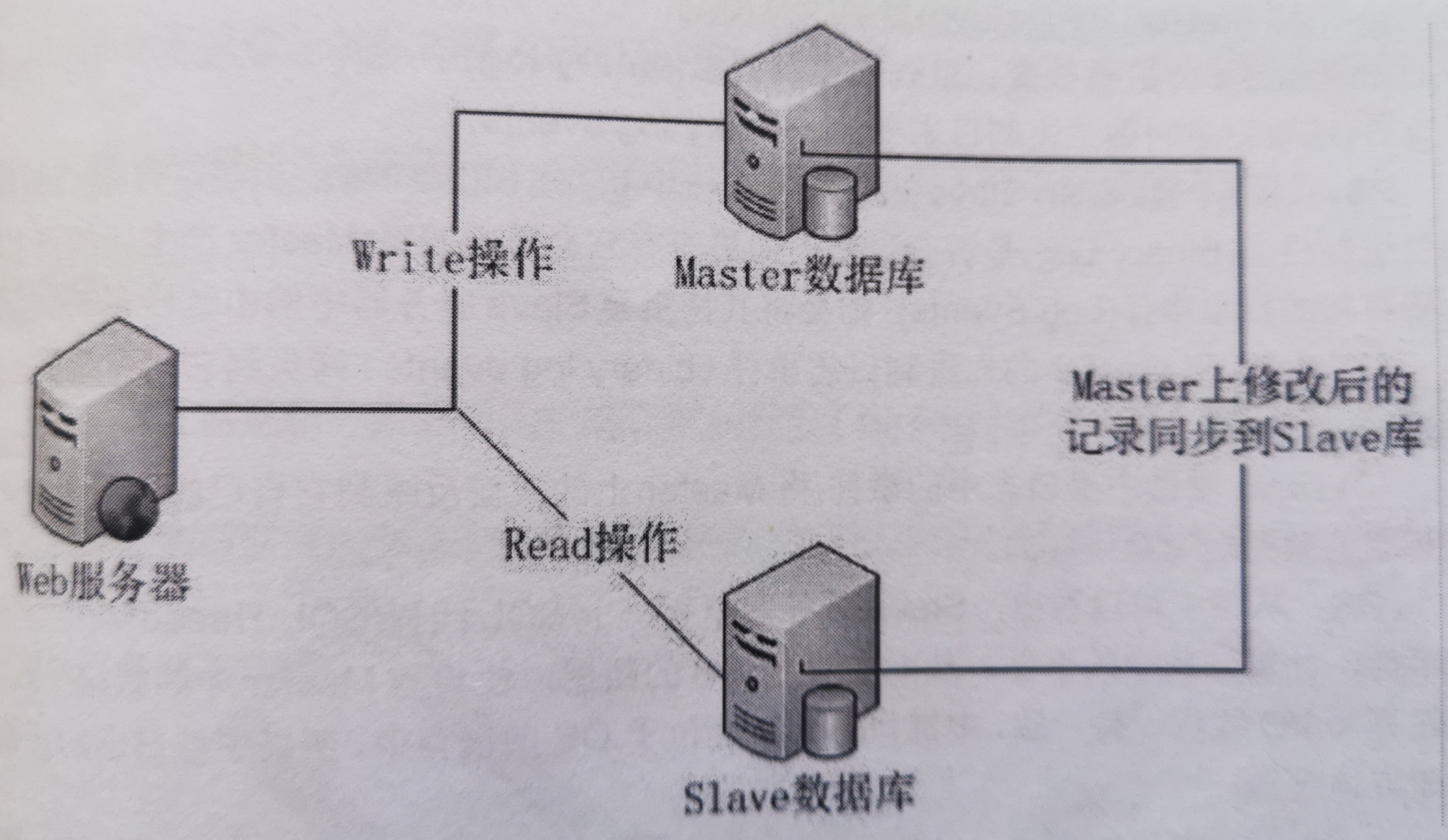
主从复制的原理:
影响MySQL-A数据库的操作,在数据库执行后,都会写入本地的日志系统A中。假设,实时的将变化了的日志系统中的数据库事件操作,通过网络发给MySQL-B。MySQL-B收到后,写入本地日志系统B,然后一条条地将数据库事件在数据库中完成。那么MySQL-A的变化,MySQL-B也会变化,这样就是所谓的MySQL的复制。
在上面的模型中,MySQL-A就是主服务器,即master,MySQL-B就是从服务器,即slave。
日志系统A,其实它是MySQL的日志类型的二进制日志,也就是专门用来保存修改数据库的所有动作,即bin log。【注意MySQL会在执行语句之后,释放锁之前,写入二进制日志,确保事务安全。】
日志系统B,并不是二进制日志,由于它是从MySQL-A的二进制日志复制过来的,并不是自己的数据库变化产生的,有点接力的感觉,称为中继日志,即relay log。
可以发现,通过上面的机制,可以保证MySQL-A和MySQL-B的数据库数据一致,但是时间上肯定有延迟,即MySQL-B的数据是滞后的。
简化版:
MySQL主(称master)从(称slave)复制的原理:
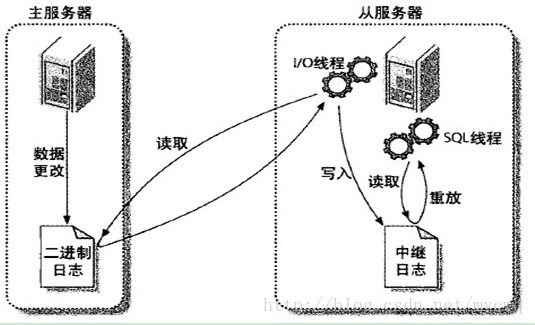
1.master将数据改变记录到二进制日志(binary log)中,也即是配置文件log-bin指定的文件(这些记录叫做二进制日志事件,binary log events)
PS:从图中可以看出,Slave服务器中有一个I/O线程(I/O Thread)在不停地监听Master的二进制日志(binary log)是否有更新:如果没有,它会睡眠等待Master产生新的日志事件;如果有新的日志事件(log events),则会将其拷贝至Slave服务器中的中继日志(relay log)。
2.slave将master的二进制日志事件(binary log events)拷贝到它的中继日志(relay log)。
3.slave重做中继日志中的事件,将Master上的改变反映到它自己的数据库中。所以两端的数据是完全一样的。
PS:从图中可以看出,Slave服务器有一个SQL线程(SQL Thread)从中继日志读取事件,并重做其中的事件,从而更新Slave的数据,使其与Master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。
主从复制的几种方式:
1.同步复制
主服务器在将更新的数据写入它的二进制日志(binlog)文件中后,必须等待验证所有的从服务器的更新数据是否已经复制到其中,之后才可以自由处理其他进入的事务处理请求。
2.异步复制
主服务器在将更新的数据写入它的二进制日志(binlog)文件中后,无需等待验证更新数据是否复制到从服务器中,就可以自由处理其他进入的事务处理请求。
3.半异步复制
主服务器在将更新的数据写入它的二进制日志(binlog)文件中后,只需等待验证其中一台从服务器的更新数据是否已经复制到其中,就可以自由处理其他进入的事务处理请求,其他的从服务器不用管。
数据库分表、分区、分库
分表见上期描述。
分区就是把一张表的数据分成多个区块,这些区块可以在一个磁盘上,也可以在不同的磁盘上,分区后,表面上还是一张表,但数据散列在多个位置,这样一来,多块硬盘同时处理不同请求,从而提高磁盘io读写性能,实现比较简单。包括水平分区和垂直分区。
分库是根据业务不同把相关的表且分到不同的数据库中,比如web、bbs、blog等库。
--结束END--
本文标题: 如果有一个特别大的访问量到数据库上,怎么做优化?主从复制、读写分离
本文链接: https://lsjlt.com/news/5102.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0