作者 | 汤爱中,云和恩墨SQM开发者,oracle/Mysql/DB2的sql解析引擎、SQL审核与智能优化引擎的重要贡献者,产品广泛应用于金融、电信等行业客户中。摘要优化器是逻辑SQL到物理存储的解释器

作者 | 汤爱中,云和恩墨SQM开发者,oracle/Mysql/DB2的sql解析引擎、SQL审核与智能优化引擎的重要贡献者,产品广泛应用于金融、电信等行业客户中。
优化器是逻辑SQL到物理存储的解释器,是一个复杂而“愚蠢”的数学模型,它的入参通常是SQL、统计信息以及优化器参数等,而输出通常一个可执行的查询计划,因此优化器的优劣取决于数学模型的稳定性和健壮性,理解这个数学模型就能理解数据库的SQL处理流程。
01 优化器的执行流程
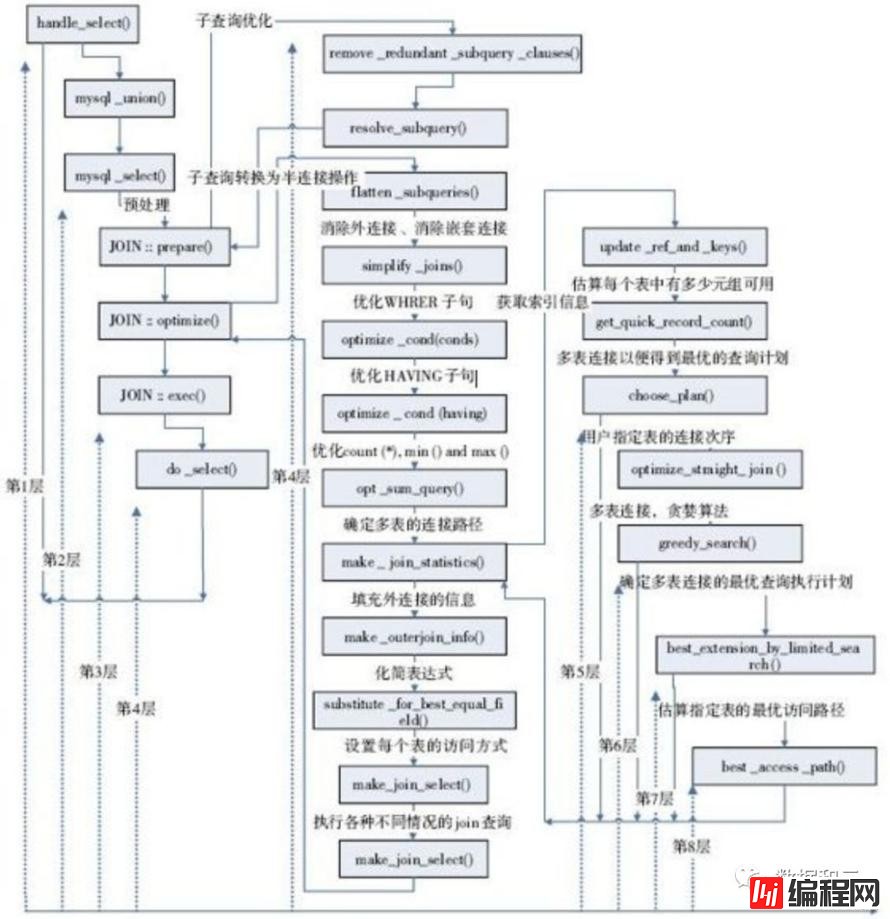
(注:此图出自李海翔)
上图展示了优化器的大致执行过程,可以简单描述为:
1 根据语法树及统计统计,构建初始表访问数组(init_plan_arrays)
2 根据表访问数组,计算每个表的最佳访问路径(find_best_ref),同时保存当前最优执行计划(COST最小)
3 如果找到更优的执行计划则更新最优执行计划,否则优化结束。
从上述流程可以看出,执行计划的生成是一个“动态规划/贪心算法”的过程,动态规划公式可以表示为:Min(Cost(Tn+1)) = Min(Cost(T1))+Min(Cost(T2))+...Min(Cost(Tn-1))+Min(Cost(Tn)),其中Cost(Tn)表示访问表T1 T2一直到Tn的代价。如果优化器没有任何先验知识,则需要进行 A(n,n) 次循环,是一个全排列过程,很显然优化器是有先验知识的,如表大小,外连接,子查询等都会使得表的访问是部分有序的,可以理解为一个“被裁减”的动态规划,动态规则的核心函数为:Join::Best_extention_limited_search,在源码中有如下代码结构:
bool Optimize_table_order::best_extension_by_limited_search( table_map remaining_tables, uint idx, uint current_search_depth) { for (JOIN_TAB **pos= join->best_ref + idx; *pos; pos++) { ...... best_access_path(s, remaining_tables, idx, false, idx ? (position-1)->prefix_rowcount : 1.0, position); ...... if (best_extension_by_limited_search(remaining_tables_after, idx + 1, current_search_depth - 1)) ...... backout_nj_state(remaining_tables, s); ...... } }以上代码是在一个for循环中递归搜索,这是一个典型的全排列的算法。
02优化器参数
mysql的优化器对于Oracle来说还显得比较幼稚。Oracle有着各种丰富的统计信息,比如系统统计信息,表统计信息,索引统计信息等,而MySQL则需要更多的常量,其中MySQL5.7提供了表mysql.server_cost和表mysql.engine_cost,可以供用户配置,使得用户能够调整优化器模型,下面就几个常见而又非常重要的参数进行介绍:
1 #define ROW_EVAluaTE_COST 0.2f
计算符合条件的行的代价,行数越多,代价越大
2 #define IO_BLOCK_READ_COST 1.0f
从磁盘读取一个Page的代价
3 #define MEMORY_BLOCK_READ_COST 1.0f
从内存读取一个Page的代价,对于Innodb来说,表示从一个Buffer Pool读取一个Page的代价,因此读取内存页和磁盘页的默认代价是一样的
4 #define COND_FILTER_EQUALITY 0.1f
等值过滤条件默认值为0.1,例如name = ‘lily’, 表大小为100,则返回10行数据
5 #define COND_FILTER_INEQUALITY 0.3333f
非等值过滤条件的默认值是0.3333,例如col1>col2
6 #define COND_FILTER_BETWEEN 0.1111f
Between过滤的默认值是0.1111f,例如:col1 between a and b
......
这样的常量很多,涉及到过滤条件、JOIN缓存、临时表等等各种代价,理解这些常量后,看到执行计划的Cost后,你会有种豁然开朗的感觉!
03 优化器选项
在MySQL中,执行select @@optimizer_trace, 得到如下参数:
index_merge=on,index_merge_uNIOn=off,index_merge_sort_union=off, index_merge_intersection=on, engine_condition_pushdown=on, index_condition_pushdown=on, mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,subquery_materialization_cost_based=on, use_index_extensions=on, condition_fanout_filter=on
04 Optimize Trace是如何生成的?
在流程图中的函数中,存在大量如下代码:
Opt_trace_object trace_ls(trace, "searching_loose_scan_index");
因此,在优化器运行过程中,优化器的执行路径也被保存在Opt_trace_object中,进而保存在infORMation_schema.optimizer_trace中,方便用户查询和跟踪。
05 优化器的典型使用场景
5.1 全表扫描
select * from sakila.actor;
表actor统计信息如下:
Db_name | Table_name | Last_update | n_rows | Cluster_index_size | Other_index |
sakila | actor | 2018-11-20 16:20:12 | 200 | 1 | 0 |
主键actor_id统计信息如下:
Index_name | Last_update | Stat_name | Stat_value | Sample_size | Stat_description |
PRIMARY | 2018-11-14 14:25:49 | n_diff_pfx01 | 200 | 1 | actor_id |
PRIMARY | 2018-11-14 14:25:49 | n_leaf_pages | 1 | NULL | Number of leaf pages in the index |
PRIMARY | 2018-11-14 14:25:49 | size | 1 | NULL | Number of pages in the index |
执行计划:
{ "query_block": { "select_id": 1, "cost_info": { "query_cost": "41.00" }, "table": { "table_name": "actor", "access_type": "ALL", "rows_examined_per_scan": 200, "rows_produced_per_join": 200, "filtered": "100.00", "cost_info": { "read_cost": "1.00", "eval_cost": "40.00", "prefix_cost": "41.00", "data_read_per_join": "56K" }, "used_columns": [ "actor_id", "first_name", "last_name", "last_update", "id" ] } } } IO_COST = CLUSTER_INDEX_SIZE * PAGE_READ_TIME = 1 * 1 =1; EVAL_COST = TABLE_ROWS*EVALUATE_COST = 200 * 0.2 =40; PREFIX_COST = IO_COST + EVAL_COST;注意以上过程忽略了内存页和磁盘页的访问代价差异。
5.2 表连接时使用全表扫描
SELECT * FROM sakila.actor a, sakila.film_actor b WHERE a.actor_id = b.actor_id
Db_name | Table_name | Last_update | n_rows | Cluster_index_size | Other_index_size |
Sakila | Film_actor | 2018-11-20 16:55:31 | 5462 | 12 | 5 |
表film_actor中索引(actor_id,film_id)统计信息如下:
Index_name | Last_update | Stat_name | Stat_value | Sample_size | Stat_description |
PRIMARY | 2018-11-14 14:25:49 | n_diff_pfx01 | 200 | 1 | actor_id |
PRIMARY | 2018-11-14 14:25:49 | n_diff_pfx02 | 5462 | 1 | actor_id,film_id |
PRIMARY | 2018-11-14 14:25:49 | n_leaf_pages | 11 | NULL | Number of leaf pages in the index |
PRIMARY | 2018-11-14 14:25:49 | size | 12 | NULL | Number of pages in the index |
{ "query_block": { "select_id": 1, "cost_info": { "query_cost": "1338.07" }, "nested_loop": [ { "table": { "table_name": "a", "access_type": "ALL", "possible_keys": [ "PRIMARY" ], "rows_examined_per_scan": 200, "rows_produced_per_join": 200, "filtered": "100.00", "cost_info": { "read_cost": "1.00", "eval_cost": "40.00", "prefix_cost": "41.00", "data_read_per_join": "54K" }, "used_columns": [ "actor_id", "first_name", "last_name", "last_update" ] } }, { "table": { "table_name": "b", "access_type": "ref", "possible_keys": [ "PRIMARY" ], "key": "PRIMARY", "used_key_parts": [ "actor_id" ], "key_length": "2", "ref": [ "sakila.a.actor_id" ], "rows_examined_per_scan": 27, "rows_produced_per_join": 5461, "filtered": "100.00", "cost_info": { "read_cost": "204.67", "eval_cost": "1092.40", "prefix_cost": "1338.07", "data_read_per_join": "85K" }, "used_columns": [ "actor_id", "film_id", "last_update" ] } } ] } }第一张表actor的全表扫代价为41,可以参考示例1。
第二个表就是NET LOOP 代价:
read_cost(204.67) =prefix_rowcount * (1 + keys_per_value/table_rows*cluster_index_size =
200 * (1+27/13863*12)*1
注意:27 相当于对于每个actor_id,film_actor的索引估计,对于每个actor_id,平均有27条记录=5462/200
Table_rows是如何计算的呢?
Film_actor表的实际记录数是5462,一共12个page,11个叶子页,总大小为11*16K(默认页大小)=180224Byte, 最小记录长度为26(通过计算字段长度可得),13863 = 180224/26*2, 2是安全因子,做最差的代价估计。
表连接返回行数=200*5462/200,因此行估算代价为5462*0.2=1902.4
5.3 IN查询
表film_actor中索引idx_id(film_id)统计信息如下:
Index_name | Last_update | Stat_name | Stat_value | Sample_size | Stat_description |
idx_id | 2018-11-14 14:25:49 | n_diff_pfx01 | 997 | 4 | actor_id |
idx_id | 2018-11-14 14:25:49 | n_diff_pfx02 | 5462 | 4 | film_id,actor_id |
idx_id | 2018-11-14 14:25:49 | n_leaf_pages | 4 | NULL | Number of leaf pages in the index |
idx_id | 2018-11-14 14:25:49 | size | 5 | NULL | Number of pages in the index |
EXPLAIN SELECT * FROM ACTOR WHERE actor_id IN (SELECT film_id FROM film_actor) { "query_block": { "select_id": 1, "cost_info": { "query_cost": "460.79" }, "nested_loop": [ { "table": { "table_name": "ACTOR", "access_type": "ALL", "possible_keys": [ "PRIMARY" ], "rows_examined_per_scan": 200, "rows_produced_per_join": 200, "filtered": "100.00", "cost_info": { "read_cost": "1.00", "eval_cost": "40.00", "prefix_cost": "41.00", "data_read_per_join": "56K" }, "used_columns": [ "actor_id", "first_name", "last_name", "last_update", "id" ] } }, { "table": { "table_name": "film_actor", "access_type": "ref", "possible_keys": [ "idx_id" ], "key": "idx_id", "used_key_parts": [ "film_id" ], "key_length": "2", "ref": [ "sakila.ACTOR.actor_id" ], "rows_examined_per_scan": 5, "rows_produced_per_join": 200, "filtered": "100.00", "using_index": true, "first_match": "ACTOR", "cost_info": { "read_cost": "200.66", "eval_cost": "40.00", "prefix_cost": "460.79", "data_read_per_join": "3K" }, "used_columns": [ "film_id" ], "attached_condition": "(`sakila`.`actor`.`actor_id` = `sakila`.`film_actor`.`film_id`)" } } ] } } id select_type table partitions type possible_keys key key_len ref rows filtered Extra ------ ----------- ---------- ---------- ------ ------------- ------ ------- --------------------- ------ -------- --------------------------------------------- 1 SIMPLE ACTOR (NULL) ALL PRIMARY (NULL) (NULL) (NULL) 200 100.00 (NULL) 1 SIMPLE film_actor (NULL) ref idx_id idx_id 2 sakila.ACTOR.actor_id 5 100.00 Using where; Using index; FirstMatch(ACTOR)
从执行计划中可以看出,MySQL采用FirstMatch方式。在MySQL中,半链接优化方式为:Materialization Strategy,LooseScan,FirstMatch,DuplicateWeedout,默认情况下四种优化方式都是存在的,选取方式基于最小COST。现在我们以FirstMatch为例,讲解优化器的执行流程。
SQL如下:
select * from Country where Country.code IN (select City.Country from City where City.Population > 1*1000*1000) and Country.continent='Europe'
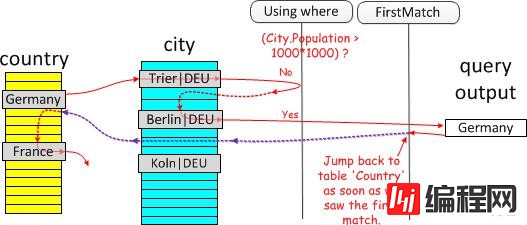
从上图可以看出,FirstMatch是通过判断记录是否已经在结果集中存在来减少查询和匹配流程。
表actor的访问代价可以参考示例1.
表film_actor表的访问代价200.66是如何计算的呢?
访问表film_actor中索引字段film_id,MySQL会走覆盖索引扫,即IDEX_ONLY_SCAN,一次索引访问的代价是如何计算的呢?
参考函数double handler::index_only_read_time(uint keynr, double records)
索引块大小为16K,并且MySQL假设块都是半满的,则一个块能够存放的索引记录数为:
16K/2/(索引长度+主键长度(注:二级索引存储的是主键的引用))=16K/2/(2+4)+1=1366,
其中主键为(actor_id,film_id),两个字段都是smallint,占用4个字节,而索引idx_id(film_id)是2个字节,因此每次访问索引的代价为:(5.47+1366-1)/1366 = 1.0032, 访问film_actor表一共需要200次,总访问代价为:200*1.0032=200.66
总代价460.79 = 表actor的访问代价+表film_actor访问代价+行估算代价=
41+200.66+200*1*5.47*1*02,其中两个1分别表示过滤因子,由于两个表均没有过滤条件因此过滤因子都是1。
--结束END--
本文标题: 深入解析:从源码窥探MySQL优化器
本文链接: https://lsjlt.com/news/49814.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0