腾讯云数据库国产数据库专题线上技术沙龙正在火热进行中,3月5日林晓斌(丁奇)的2020首场分享已经结束,没来得及参与的小伙伴不用担心,下面就给大家奉上直播视频全程回顾,流量伤不起的小伙伴们也可以看由腾讯云
腾讯云数据库国产数据库专题线上技术沙龙正在火热进行中,3月5日林晓斌(丁奇)的2020首场分享已经结束,没来得及参与的小伙伴不用担心,下面就给大家奉上直播视频全程回顾,流量伤不起的小伙伴们也可以看由腾讯云数据库整理好的文字稿,干货满满,保证让你有所收获。
关注“腾讯云数据库”公众号,回复“0305丁奇”,即可下载直播分享PPT。
点击查看完整直播回放
大家好!我是腾讯云数据库的林晓斌,在社区活动的时候网名叫丁奇,跟比较多的同学互相认识,今天跟大家就是找个机会聊一下数据库的基础,还有腾讯自研数据库的技术演进,我相信来听的同学应该都是对数据库都比较熟悉,前面的内容会比较快地过,主要还是讲我对数据库典型架构的一些理解,当然我知道Mysql的分享有很多,所以今天的大部分内容可能很多人都比较熟了,但是如果有一两个点,你觉得好像是个新东西,我觉得我们就成功了。
首先先说数据库的基本概念,实际上其实如果我们只是要一个数据库的话,数据库就是拿来存东西的,存跟取就是它的基本功能。

在这里可以举一个暴露年龄的例子——就是我21世纪初读大学的时候,给老师课程网站和外面公司做信息管理系统都用的是Access,那个时候就觉得只要我会建了索引数据库就都掌握了,数据库挺简单的。当然后面事实证明是我自己太简单了,后来工作有机会接触oracle和mysql这些工业数据库,才算是知道了什么是真正的数据库。
实际上我们说数据库发展到现在,一直会有这么几个挑战——可靠性、可用性、安全性、性能和成本等,因为今天时间的关系也很难全部讲,所以今天我们就讲一个点—— 性能。

那么性能的问题是怎么来的?
如果数据量很小,访问量也很小,其实一个Access就够了,甚至如果更小一点,搞不好一个excel就够了是吧?实际上真正给性能问题带来挑战的,主要是以下3个方面的原因:
1.大数据量。数据量特别大,存跟取影响了性能;
2.大并发。比如有很多个请求或者很多个客户端一起来访问;
3.读写模式。读写模式什么意思呢?虽然是同一份数据,但是我们在查询的时候,会有不同的查询需求,比如说以前论坛的帖子列表,如果你只是按顺序显示出来,那是比较简单的;如果你要在里面搜东西那会难一点;如果你还要做一些统计和做一些分析,那就更难了。不同的读模式,对数据库的查询压力是不同的。越复杂的,比如刚才说的搜索或者说分析等这样的操作本身对数据库的读的压力就跟普通的按行读取不一样,所以这些是我们真正需要去解决的数据库性能问题。
说到这里就需要谈到Mysql的基本架构,它在解决不同的读写模式上面刚好有优势。下面这个图大家应该比较熟悉了,这是MySQL的基本架构。MySQL是分成上下两层的,上面这个框我们叫做server层,就是服务器层,负责跟客户端做连接,做分析器、优化器、执行器,下面会分成多种类型的引擎,这是MySQL相比于其它的数据库特有的一个特性, 可以接不同的引擎,每一种引擎可以设定自己的读写存取模式和索引的构建方式,来应对不同的查询需求。
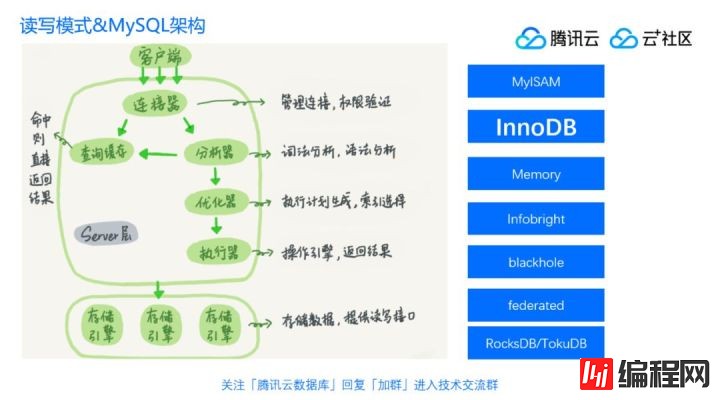
常见的MySQL引擎有很多,比如说MyISAM,就是MySQL原生的一个引擎,在MySQL5.5之前是默认的存储引擎,但是它的问题是不支持事务,也不支持crash-safe,就是主机断电的时候可能会丢数据,所以后面用得越来越少了。
Innodb现在是最主流的关系数据库引擎,它解决了什么问题呢?首先它能支持事务的ACID特性,也支持崩溃恢复,所以变成现在最主流的MySQL引擎了。
Memory引擎用得也挺多的,早期版本Innodb的性能还没那么好的时候,我们有时候会想用内存引擎来替代Innodb,这样的话可能会快一点。当然我们知道Memory引擎重启以后数据会丢失,但是有时候纯粹就把它拿来当缓存服务用,有些公司的dba会喜欢用Memory,实际上Innodb发展到现在,其实已经可以不需要Memory引擎了。数据量小的话,放在Innodb里面基本上都是可以全部缓存的。
那写的能力呢?如果说Innodb是磁盘型的,写的时候要落盘,其实性能一方面是现在的SSD硬盘普及也快了,另外一个很重要的原因是因为Memory不支持并发,你看上去单个线程的读写很快,但是如果你有两个线程一起要更新同一张表的时候,它就要排队,不像Innodb一样支持行锁。所以现在从总体看通用的使用场景的话,Memory其实是不如Innodb的,所以慢慢用的比较少,像腾讯云的CDB现在直接不建议也不允许用户创建内存引擎了。infobright可能也是老玩家才知道的,就是一个列存引擎,可以做OLAP业务的一个引擎。
blackhole是一个黑洞引擎,是什么意思呢?只有表结构,往里面写的数据都不存,直接就没了,也不会给你访问报错,只会告诉你执行成功,看上去像个黑洞,一会我们也会介绍一下这种引擎的使用场景。
federated是一个远程链接的引擎,你在这边建一个表,但实际上数据不是存在本地,可以让你定义数据源在哪里,然后到另外一个地方去取。
还有RocksDB和TokuDB引擎,是基于LSM或者fractal tree,不是基于B+tree的一个支持事务的引擎,这两个引擎比较明显的特点是压缩率比Innodb高,主要原因是压缩块比较大,我们知道Innodb里面16K一个块来压缩的,越大的单位数据压缩效果会越好,像TokuDB是4M一个块来压缩的,所以它的压缩比高,当然它带来问题就是读的时候CPU消耗多一点。
比较常见的是这些引擎,当然你可能还可以列出别的,但基本上社区用的比较多的是这一些。
那么MySQL有这种多引擎的架构,有什么好处?刚才我们说了,当一个业务既需要TP型的业务,但是又需要做列存和分析时,如果是换别的数据库,比如说postgresql或者Oracle,本身就很难同时兼容这两种能力。而MySQL可以不走引擎,我可以表A创建出一个Innodb表,表B创建一个infobright表,然后数据在里面做同步,以后我如果要做oltp的查询,就找Innodb表查,AP的查询就找infobright查,至少它的架构可以这么做。有的同学会觉得很奇葩,混合引擎这种是不是很少见?其实并不是,MySQL天然就这么干的,默认的存储引擎我们现在都用Innodb,实际上MySQL自己的系统库在5.6和5.7及以前的版本都是用的MyISAM,如user表,这个是存用户的表、还有存库名的表等,其实就是放在MyISAM里面,所以MySQL本身就在践行混合引擎,当然是需要特别谨慎的。
举个例子,比如跨引擎事务的一致性问题。我们知道Innodb是支持事务的,而MyISAM是不支持的,假设说现在有一个库,里面有两个表,T1是MyISAM表,T2是Innodb表,如果你分别使用是没有问题的,如果我们想要事务,begin启动一个事务,往T1表里面插入一行,再往T2表里插入一行,然后执行一个rollback,我们认为既然begin后面没有提交,然后最后执行的一个rollback,那就应该T1跟T2这两个插入都撤销,这就是事务的原子性,要么都成功,要么都失败。
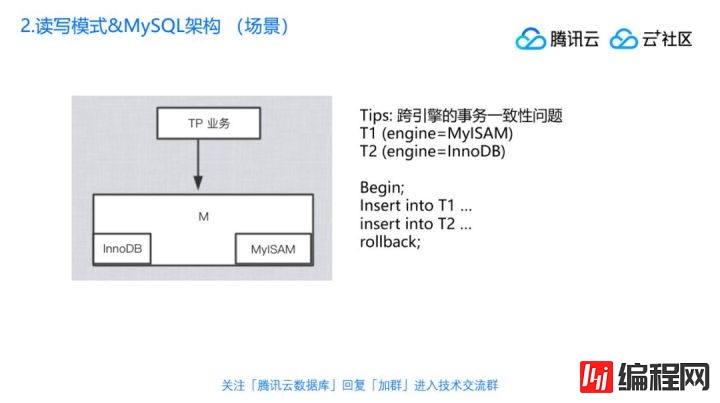
但是因为MyISAM不支持事务,也就是说insert into T1执行完以后,马上就持久化了,就写到数据里面去了,所以这一个序列执行完成以后,在数据库里就会看到T1里的那条数据还在,T2里面的这条又不在了,这个是违反了事务的原子性规则的,对,但不是引擎的问题,这是因为我们写法本身有问题。这样你也会更明确知道:原来事务的特性是实现在引擎里的,支持的引擎就支持,不支持的引擎它就只好忽略。我自己之前在应用的一些场景里面也用过,同一个数据库里面有不同引擎的表是OK的,但是当你要用到一些引擎的特性的时候,像事务,或者说savepoint、全文检索这种比较特殊的特性,或者全文检索的时候,就要去关注引擎到底支不支持,如果不支持那就不能做,不能混用。
这种场景大家可能会说好像用的不太多,我们再看下面这个图,把Innodb跟infobright放到一起,虽然MySQL天然就支持,但是它有个问题,感觉看上去不是很专业,还有比如说你在infobright上面跑AP的请求,虽然也可以,但是毕竟我们知道它们共用的server层是同一份,这样的话会不会导致它们互相争强CPU?其实是会的,那如果想要想剥离出来可以怎么做?那就是下面这个图。
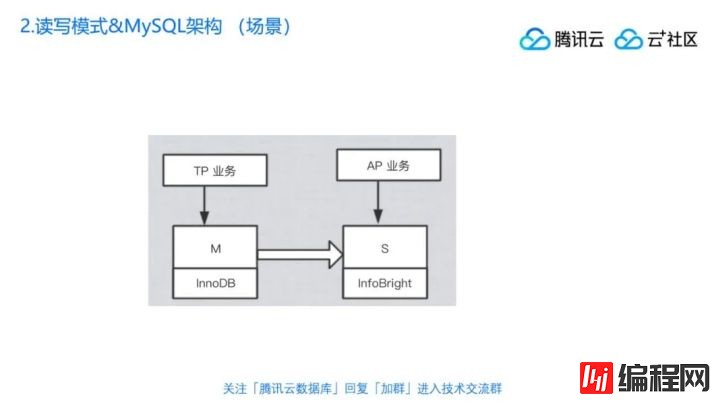
就是说你可以搭建两个不同的MySQL实例,然后主实例用Innodb引擎。slave实例用infobright引擎。因为MySQL的主从同步是可以支持跨索引跨引擎的,也就是说假设左边有一个表T1,它是Innodb表,而同步过来,slave上面的T1,手动把它改成infobright或者别的引擎的表,这样是可以同步的。也就是说往主库里面做增删改,都可以同步到从库的infobright相同的表名里面,之后你要做AP型的查询,就直接到从库这里面来查,它是列存的,这种OLAP的请求就足够快,这是其中的一种用法。
另外这种用法其实还是有比较多的引申版本,比如说中间这个通道,现在图里面看到我这样画,其实就是MySQL天然的主从同步机制,当然我们可以中间放一个数据传输组件DTS,然后从主库拉日志到从库去应用,这个是类似的,这是一种场景,这种场景下面解决的是什么问题?主库跟备库的数据是一样的,查询的逻辑不太一样,需要备库提供更强的不同于Innodb的能力,这个时候就可以换一个引擎来用,这种场景还是偶尔会见到。
还有另外一个场景,黑洞引擎有什么用?
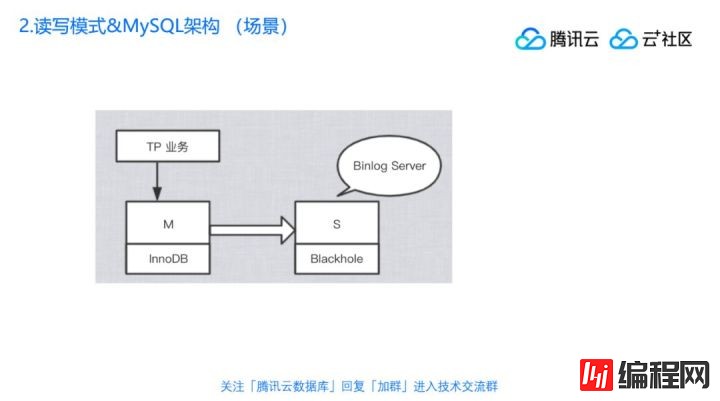
我们还是回到图的左边,左边是一样的,TP这个业务MySQL里面写,里面是Innodb表,然后传到从库去,从库把它改成blackhole引擎。我们刚才说到了blackhole引擎只有表结构,数据写进来以后数据就没了,那么你传过来干嘛呢?传过来存binlog。MySQL的机制是当左边写了数据跟日志以后,如果要同步给从库的话,它一定要把binlog传过来给从库,从库收到日志以后做什么事?做两件事,先把日志存在本地,再把本地的日志拿来应用,应用完以后,再从库里面生成出一份相同的日志。如果你把它改成blackhole引擎,那后面那一步就没有用了,拿到日志,后面的执行就是空执行, 表虽然没有,但是日志还在,那简单来说这个就可以用来存binlog,这样话要备份binlog就不需要到主库上面去拷了。去主库上面拷也不实时,通过这种方式就可以实时拿到binlog。当然现在这只是说MySQL天然支持这样的机制,实际上现在社区也有不少比较优秀软件本身也可以做相同的事情,可以模拟binlogserver的行为,找主库要binlog,要完以后也不应用,就存在本地,只是说如果我们要搭建一个简单的binlog server,就可以让从库用blackhole引擎,其实用的也还挺多的。
有的同学说这看上去有点傻,还不如用像社区的那些方案,实际上如果可以再往前扩展一下,还可以想到别的场景,比如说我们要做分布式的场景,一般要多个节点,因为要做选举对吧?比如说我们要做跨中心跨城市的高可用集群时候,集群节点可能很多,比如说在A城市有5个节点,B城市有4个节点,9个跑起来特别爽,是吧?挂了一个以后都可以选举选出来,它有个问题是什么?成本比较高,因为你每个地方都要放数据,这样的话有没有节约成本的方法?之前也有人践行过这样的方案,就是说这9个节点也不是真的要那么多数据,其中有一部分纯粹就只是想参与选举而已,甚至于你自己都不想被选成,只是参与投票而已,那就可以用blackhole引擎,它可以同步数据跟大家形成交互,然后参与投票,当然它要把自己标志成不能被选成主,这样虽然你有9个节点的成本,但实际上你真正需要的存储可能只有5个或者4个就可以了,其它的用binlog server来模拟,这个也是之前有践行过的架构。
反正在中国大批量使用MySQL到现在有十二三年了,中间各种各样的架构都出现过。再说到另外一个场景,误删了数据,然后这时候你要恢复,恢复有一种场景是这样的,假设这个库里面有业务数据表A,还有业务日志表B,一般来说日志表都比数据表比较大很多,因为中间记了各种流水,我想恢复出一个库,恢复数据是拿昨天的备份恢复的,然后拿到全量数据后应用binlog追到我要的时间点。而如果现在特别着急的想要,又刚好昨天业务压力大,所以日志表的更新量特别大,恢复出去全量备份以后,接下来你拿日志不停地应用,然后你会发现多时间都在等日志表的回复,因为日志表更新多。如果我现在很明确,先暂时不要日志表,先把这个数据表给恢复出来,有什么方法?当然方法有好多,我只是说如果用blackhole可以这么干,你就把日志表给它清空掉,或者说移走,然后创建一个同名的,引擎叫Blackhole的表,放在那边是一个空表。接下来它开始追日志,它的好处是现在日志表追的特别快,因为这个引擎的特性是什么?你写的时候它就一看我是blackhole引擎,命令过来,就直接跳过,这样应用就非常快,这样话你就可以快速达到恢复数据表的目的。所以支持引擎其实还是有点有趣的,虽然说它不是主流的应用,但在单机的MySQL里面支持这样的能力。
我们接着往下说MySQL的高可用架构,大家都知道怎么做高可用,一般是一主两备或者至少一主一备,然后往主库写,主库挂了就切到从库去。从左边切到右边就实现了一个HA,除非AB两个一起挂,运气不好,但是概率小很多。如果一台机器挂了是千分之一的概率,两个一起挂就是百万分之一的概率,这个已经很小了,所以一般是这么做的。然后A跟B之间比较主流的实现会设置成互为双组,这样话切换的时候快一点,你只要把客户当成左边切到右边就可以了,这是典型的MySQL的高可用架构,但这个不是我们今天描述的重点,只是说我们后面要讲的时候,每讲一个数据库节点的时候,它默认是带着主从。
我们还是回到性能这个问题,我们怎么解决读性能的问题?加机器!DBA的核心技能两点,第一个是重启,第二个是加机器。(笑)
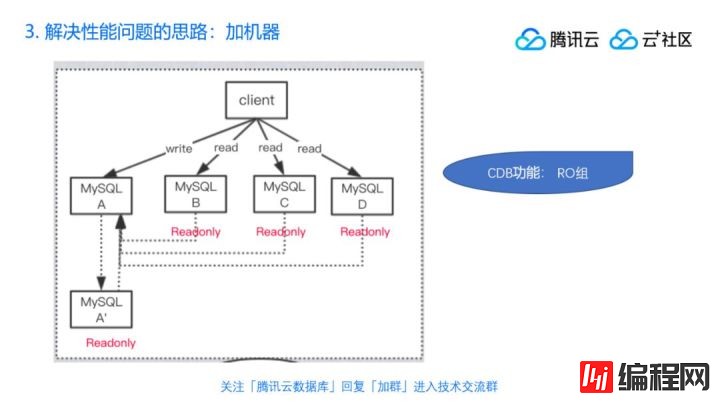
那么加机器加成什么样的?我们看到一主好多从,图中除了A跟A′是用来做主备做高可用的以外,像BCD本身没有业务直接给它们写数据,但是是从A这个节点里面把数据同步过来的,就是你写一份A它会同步给A′做高可用,同时同步给BCD,BCD拿到日志应用完以后,我们认为BCD的数据跟A是一样的,接下来客户端就可以来找BCD来读了。这样如果A撑不住读压力,可以把读请求分流分给BCD,这算是比较朴素的方案,在腾讯云MySQL里面有功能叫做RO组,比如说我现在有三个只读实例,三个只读节点,如果再创建一个,客户端得改配置。实际上一般云服务都会提供这种能力, 把这些只读实例设置成一个RO组,接着它们共享同一个访问方式,或者同一个域名,或同一个IP,接下来写只要写一个,读也只要读一个,RO组会帮你做查询的轮巡和流量的分担。
但有的同学说看着还是麻烦,写和读难道就不能也凑成同一个IP吗?这样我还得知道写是写哪个,读是读哪一组,读跟写毕竟两个IP,有没有偷懒加机器的方法或者说透明加机器的方法?有!就是下面可以加个proxy。
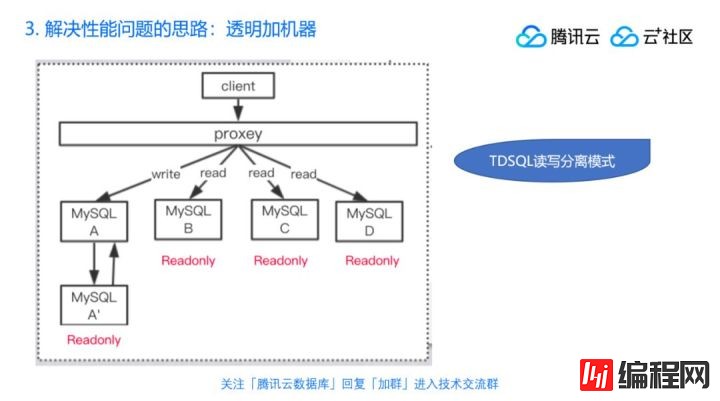
下面加一个中间层以后其实底层的架构是一样的,只是说往proxy里面访问的时候,proxy帮你做分流,如果是一个写操作发给主库,如果是读操作发给下面其他读节点,所以本质上是差不多的,好处就是你可以省得自己去管了,并且也不需要考虑扩容。
比如说腾讯的TDSQL就支持这个读写分离的模式,你要加节点的话,你也不用管了,就是下发一个加节点的需求,内部它自己帮你复制出一个E节点,然后把数据全量的恢复完以后追日志,然后再跟A建立主从关系等等,做完以后你就做了一个节点了,这种方式可以解决我们的读性能问题,那读性能解决了,写性能怎么办?我们看到刚才这两种模式,它们有个共同的特点——读是可以读好多个,能写只能写一个,如果写A撑不住了怎么办?分库分表。所以我们说 写性能就只能靠分布分表了,TDSQL也支持分库分表的模式,就是你写下来,然后做路由,当然这个路由要事先和数据库约定好分表的方式和分片的方式,比如说创建一个表,然后用户ID取模,这样的方式也是比较常见的分库分表的模式。
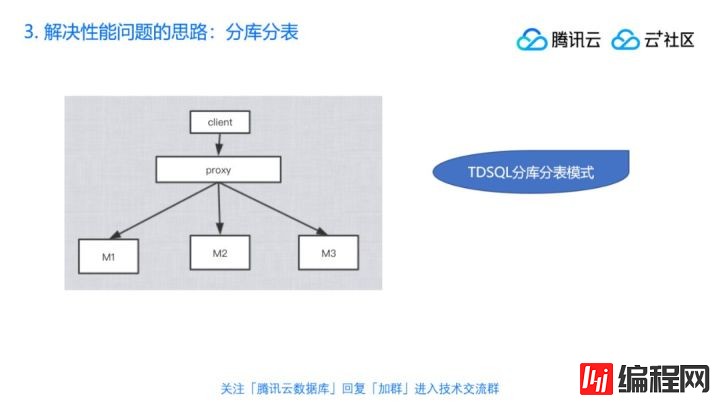
现在还有一些比如计算存储分离等模式,思路其实是差不多的,都是用来解决同一个问题,就是通过水平扩展节点的方式来分摊读压力或者写压力,然后提升我们整个系统的吞吐量。但是实际上MySQL也不是全能的,其实你想了各种方案,但是还是有支持不了的场景的。

举个例子,比如说OLAP就不支持,像刚我们说的infobright还可以,但实际上infobright现在用的也不是那么多,真的做OLAP实际上是有专门的系统来做的,一会儿我们可以举一个例子。
像图这种关系数据库,比如说MySQL,我们大家都知道是标准的二维表,要描述一个图只能用这种递归查询的方法,性能天然就有问题,你可以做,所有关系最后都表达一个二维表的关系,无非是这个关系处理比较蹩脚而已,速度会慢。
时序数据库,能不能用一个InnoDB表来存时序表?当然也可以,insert从一开始往后追加,然后查的时候也是,读的时候也是,从一开始往后删也是,看上去就是一个先进先出的队列,可以这么做,但是是浪费的,因为一个时序的场景只需要先进先出这个功能,所以InnoDB提供了那么多中间数据的读写能力,其实是一个浪费,而这种浪费体现在时序数据库应用场景上面来说,在最简单的场景里,就是性能不行。
还有一个是搜索,虽然大家也知道最早MyISAM的引擎还支持一些全文检索,后来Innodb为了替换掉MyISAM,官方也给Innodb加上了全文检索的能力,但是据我所知,也没有哪个公司真的要使用全文搜索能力的时候会大批量使用Innodb,而是会去搭建真正的像ES这样的全文检索引擎,图也是一样,OLAP有OLAP自己的系统,所以MySQL还是有它不适用的场景,核心的原因其实是数据结构,我之前在《MySQL实战45讲》里面跟大家有提到,当我们去 分析要选择哪一个数据库的时候,核心的点是要先考察数据结构,如果它是一个列存的需求,每次查询可能要查询一个一亿行,但是我就是要只查询于其中一列,这种场景特别多,MySQL能不能做?能做,但是MySQL是行存,每次你要取一个一亿行的第一列的时候,它就必须把那一行全部读进来,然后就浪费了很多io资源和不必要的CPU消耗。这个时候如果有一个专门做列存的,它有一个文件专门存了这一个表第一列的数据,读的时候就直接读出来,就减少了大量的IO消耗跟CPU消耗,这就是数据结构带来的优势。
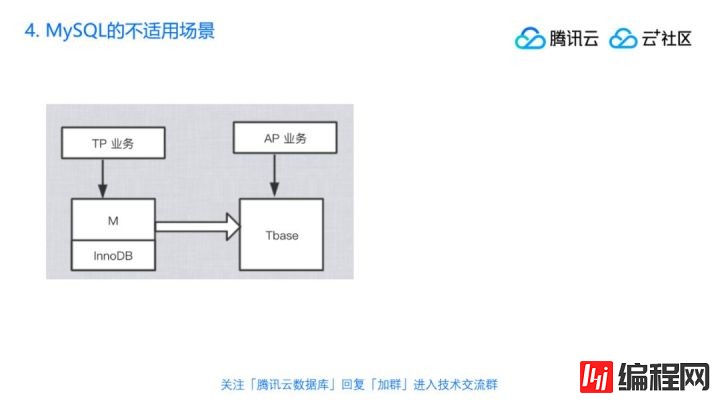
MySQL虽然也支持,也有说往MySQL里面加一些引擎来支持,但是如果我们主流用Innodb,它就不适合做这个事。还有比如说搜索也是,我明明要的是一个倒排表,可是你非得给我个关系数据库,所以它本质一样是一个数据结构的问题。我觉得这样才好,MySQL就要有这么多不适用的场景,不能有哪个数据库可以通吃所有的场景,那样才麻烦。我们举个例子,比如HTAP这种场景,刚才我们前面有个图说了,我用一个MySQL加了一个infobright也可以,但是不是最专业的,它毕竟还是一个单机版,其实现在比较主流的方式,把这里替换成一个专门做AP,在AP上面有很强能力的一个产品,这样它天然就可以支持,而且中间的比如说往这里写的TP还可以自己写,然后数据传输留的通道也可以保持,只是你把下面这个核换成一个可以专门支持这种场景能力的产品,比如腾讯云TBase,它就可以专门支持这样的场景然后来解决,这样才好。
做一个小结,我们虽然只讨论了性能问题,性能问题其实只是数据库发展过程中碰到的各种复杂问题其中的一个,而且目前看来,甚至于它大多数时候不是最严重的,是吧?安全性、可靠性那些才是挺难的。另外,每一个方案都是妥协的结果,读写分离看上去很美,实际上它不能解决写的问题,分库分表看上去更美,但是中间proxy往往要处理SQL兼容性的问题,因为那个时候你的proxy就需要做很多数据本身的操作,就会碰到语法兼容性的问题。数据库后来就会碰到更多的挑战了,在我看来接下来智能化运维是重点方向之一,当然现在大家基本上也是每个系统也做到了智能辅助,做到智能辅助就算不错了。现在业务量越来越大,像我们在疫情期间支持腾讯会议的时候,我们一些智能化的能力会减少DBA的工作量,并且提升线上的服务质量,DBA的精力可以解放出来去做更有价值的事情。
Q1:讲讲微盟的删库事件?
A1:我觉得只是微盟这次运气不好,碰到这个事情比较严重。说回我们在腾讯运营的服务过程中,经常碰到这种客户,需要回滚,恢复误删的数据。另外一个公司,也是比较有名的互联网公司最近也碰到一个误删库了,那这个怎么办?如果你用云数据服务,碰到这种情况,之后就是一个常规操作,找一下昨天的备份,然后把日志下载再应用就行了。有同学会说你放在云上,我是个黑客想恶意操作,进去把数据和备份删了,你不是一样蒙圈?其实实际上云会考虑更多的点,腾讯云这边假设你真的有操作数据库、生产库的权限,那么或者你可以把库删掉,但是备份是删不了的。我们的备份有两种,一个是定期备份,一个是用户主动生成的备份,定期备份的备份是不让删除的,比如说你配置了一天备一次保留7天,你只能把数据删掉,这固定保留7天的备份是不能删的,如果真的出现了这种情况的时候,我们会保证一定能够恢复出来。那我们在内部的工程师会不会有这样的权限?也没有。其实我们是分开的,可以管理生产服务器的工程师访问不了备份。其实发展到现在每个公司对数据库能力的理解不会差很多,尤其人才流动,所以各个公司数据库的leader其实我觉得水平都是差不太多的,而云的一个好处是以前碰到过各种突发情况的训练,通过不断迭代,终于构建出一个可以cover住大部分场景问题的解决方案。
Q2:TBase是基于PG演进出来的HTAP数据库,为什么不考虑在TDSQL中加入OLAP的能力呢?
A2:TDSQL我们会考虑,因为刚才说了TDSQL本身上面的框架就可以支持读写分离,也可以支持分库分表,中间那一层proxy,其实已经可以认为它已经完全兼容了MySQL的协议,接下来下面如果要AP的,其实换成AP节点是可以的,实际上也在我们的路线里面,只是说目前还没有把它产品化出来,就放到云上而已。
Q3:MySQL的分布分表有哪些成熟的可靠的方案?
A3:其实我看到最成熟就是找个维度分表,取决于你的查询模式。举个例子,如果你是做在线教育的,然后假设你是一个学生表,你就按学生ID或者按学生城市做这样的分表,基本上这样就可以了,我感觉没有很复杂的点。当然你需要解决的问题是如果你按城市分的表,按城市分库,这时候你要做一个查询,这个查询要统计所有9岁学生的情况,这个时候你就不得不给每一个分库下发查询,这样成本消耗比较高,性能会差一点,当然对应的有一些解决方案了。你业务做了分布分表,假设一些统计类的需求,需要做这种不是基于分表索引的查询的时候,你可以怎么做?可以有一个汇总的大库,要把数据汇总回去,大库里面就可以建各种索引,具体实施上可能有差异,大方向上场景就是这类架构,好像发展这么多年也没有搞出新花样。
Q4:TDSQL的分库分表模式,对MySQL语法支持如何?
A4:是这样的,所有只要你用了分布分表模式的,我都会建议上来之前一定要做一次业务回归,目前看来90%以上的客户都是直接迁上来就能用,但如果你的语句里面有那种groupby大量数据的时候,其实也兼容,但是它的性能会差一点,或者说性能跟你在本地的时候不太一样,这个时候就要经过测试,而兼容性以我们目前的情况来说改造量还是比较小。
Q5:为什么基于中间件的分库分表的方案,各家公司很少会去实现分布式事务 和 数据resharding ?
A5:不会啊,我们做得很多啊,实际上分布事务我所了解的几个大的公司都在做,因为这个是绕不开的,毕竟分布分表是一种方向,而下面的节点之间做分布式事务是另外一个方向,而这个方向确实理论挑战会更大一点,它有它的好处,就是proxy这一层可以做得很轻,甚至于proxy的兼容性问题就直接彻底被解决了。然后选主等就可以在底层自己做,实际上有在做像比如说目前在研发中的TDSQL3.0。我们现在在线上使用的TDSQL2.0其实就是标准的分库分表的方案。
Q6:可以教教调试MySQL?
A6:调试MySQL要看碰到什么问题,如果是比较简单的,比如说索引,那比较简单,如果说是碰到语句都对但是性能慢的,这种比较偏于操作型的操作。如果是MySQL这种自己调优的话,其实可以做一些基本的诊断、开慢查询日志,像percona toolkit有一些工具,可以直接跑这个工具看到结论。当然慢查询日志分析存在一个问题,可能很多语句不是慢查询,就是还不到高峰期的时候,它可能执行200ms,一看慢查询设置的是1s,所以会以为没什么问题。但是呢,如果压力一大就撑不住。这个时候如果能够有个系统,把所有的语句执行的情况都记录起来,然后再去做诊断,那肯定比只有慢查询要好。比如腾讯云MySQL就支持审计日志,你只要开了审计日志,那里面就会有所有的信息,当然你也可以使用DBbrian直接去诊断一下,看看现在的数据库里有什么问题,一般DBbrain会告诉你存在什么问题,应该怎么加索引,可以通过这种方式去了解为什么要这样做,了解它的原理。
Q7:TDSQL适用的行业和场景可以举例说明一下嘛?
A7:MySQL高可用架构可以适用很多场景,底层的安全配置也会在不同的场景不同的应用。举个例子,比如说TDSQL放在游戏里面,可能只要开启一个异步就可以了,不用开全同步,但是像张家港银行这种案例,TDSQL要放到银行的核心系统里面去的时候,能不能用呢,可以。我们有个配置,必须是全同步,至少一主两从,数据写进去后,另外两个节点都不给我返回,我就不写了,就会直接报错,至少有一个给我反馈说成功了,它才会往里面写,所以现在像TDSQL,我们是定位在做金融数据库上面的。那我想用普通的读写分离方法,能不能用TDSQL呢?可以,也没有问题,最后由你来决定了,比如我不希望当有两个从节点都坏了,就不能写。我希望还是可以正常读写,那你可以设置成退化的异步模式。适用场景还是蛮多的,行业不限,还是取决于数据的定位。
Q8:怎么判断MySQL当前需要分库分表?通过什么参数可以看到吗?
A8:一般说我们什么时候需要分库分表,第一个很明显的,如果你的数据量大,撑不住了可以使用,比如说一台机器只有10T,但是一个库快满了,这时候分库分表比较好理解,那如果是空间还没到,但是性能撑不住了呢,就可以有几个指标,比如说一个是写的RT,还有一个是读写的RT,还有一个是读的命中率,因为我们知道MySQL是B+树的结构,那如果是层数比较少的时候,就是大多数的索引都在内存里,那你每一次查询都可以在内存里完成,最后,随着数据量的增大那是不可能了,所以你有1T的数据,100G的内存,那么会有十分之一的数据直接在内存里面,假设再更大一些,那你的命中率就会降低,这里有什么参数可以看呢,就是show engine innodb status这个命令里面有个内存命中率,你一般看正常线上业务的命中率,如果是线上的OLAP,正常的命中率要为99%以上,99.2%、99.3% 这样才算正常,比如说如果掉到了97%、95% 这种,那就可能就要考虑一下了,可能你还没有发现这个问题,业务线来找你了,说为什么我的这个请求慢了。为什么会出现这种情况呢,就是因为我们知道InnoDB是B+tree组织的,你要访问一个数据的时候,你从树根开始找,要找好几层才能找到,找到最下面那个叶子节点。虽然现在ssd快了,但是如果IO压力大了,比如说10ms,那你有一次IO加载10ms还好点,如果树很高,在索引遍历的过程中需要去访问磁盘了,那这个时候性能就慢下来了,所以呢,内存命中率是一个比较重要的参考指标,其实核心是慢查询,就是业务的反馈。
Q9:您认为目前云数据库的痛点和难点分别是什么呢?
A9:我们分两块,先说用户。比如说我是一个用户,我用云数据库,觉得首先的痛点就是要提升用户使用这个产品的易用性。我是一个专业的DBA用这个数据库能不能把我的能力发挥出来,在腾讯云数据库现在可以看到好多监控信息,但是我能不能更多一些?这个系统有没有办法帮我更多的去提供诊断能力?让我能够更快的定位问题?然后把精力省下来去解决我们公司内部这种业务架构问题、数据架构问题,把我从一个DBA变成一个数据架构师。
另一部分说云服务商,比如说腾讯云现在有很多的客户,那每个客户都来问数据库为什么慢了,我们团队那十几个DBA同学早也疯了,我们系统要有这样的能力,能够不只是DBA能解决的了,我们的一线架构师、售后甚至客服的同学用一套工具就能解决大部分的问题。有这个可诊断性,可以能让很多能力发挥出来,可以让后端解放,可以让一线轻松,然后可以让我们的客户有工具了,可以诊断了,可以发挥个人的专业技能。
Q10:除了云数据库平台自己的备份,云主机自建数据库的情况,平台会自动备份数据吗?
A10:如果你是在云主机上面,就是虚拟机上面创建数据库的话,虚拟机本身会有快照备份,但是这个快照只有点的快照。举个例子,我今天下午五点不小心误删了数据,那我拿到今天凌晨12点那个备份可能不够用,那我还需要中间的binglog,那这个时候呢,你做一个磁盘级别的镜像未必有能力真的精确追到五点,如果你用数据库就没有这个问题,因为我们是天然以实例级别和日志级别来备份的数据。
Q11:TDSQL考虑加入AP功能,那么TBASE和TDSQL的定位有什么不同?
A11:TDSQL加入AP能力就是看你要解决的问题有多大,我举个例子,假设我要在TDSQL加一个搜索能力,那我除了用Innodb的全文检索以外,还可以在里面放一个sphinxSE引擎,后面挂一个sphinx,也可以跑,但是你说我要用它来支撑,比如说这个腾讯首页的搜索,那肯定撑不住。那时候就需要搭建一个专门的搜索引擎来支持。所以我们往TP系统里面加这种能力,它只能是解决跟我TP很接近,但是不需要那么大的计算量的搜索,我可以支持一下,其实这种场景使用已经很多了,因为它有一个好处是数据闭环,就是数据进去TDSQL以后你不用出去,你在这里写完后,我在这里分析,分析完以后,你直接拿走,这样用户的易用性高,但是这个方案会这样设定为小型的AP系统,像这种AP系统场景有很多的,比如你要给老板做一个报表,日报啊,运营分析系统啊,像这种在关系数据TP里面加上AP的能力这是可以的,那你说我想把它构建成一个超级搜索引擎,那就不是来干这个的。
Q12:proxy 会不会有单点问题?
A12:不是一个,其实可以是有很多个,proxy其实是最不容易成为单点了,举个例子,比如像我们的TDSQL默认是三个proxy,腾讯云Redis默认是五个proxy,实际上你会发现proxy才更好加节点,proxy没有状态,挂了一台, 我直接找另一把它启动起来就行了,所以proxy不太会容易成为单点的。
Q13:TDSQL在一主一备模式下通过网关访问数据库,进行查询压测时主节点的cpu使用率很高 备节点很低,可能是什么原因导致的呢?
A13:如果你只有一主一备,你要确认一下你的分库规则,你可能把所有的请求都发给主库了,但TDSQL是有监控的,你可以看哪个主节点和备节点上面分别查询的请求,举个例子,如果查询全在主节点,备节点没有,那你可能要配置下你的路由规则。
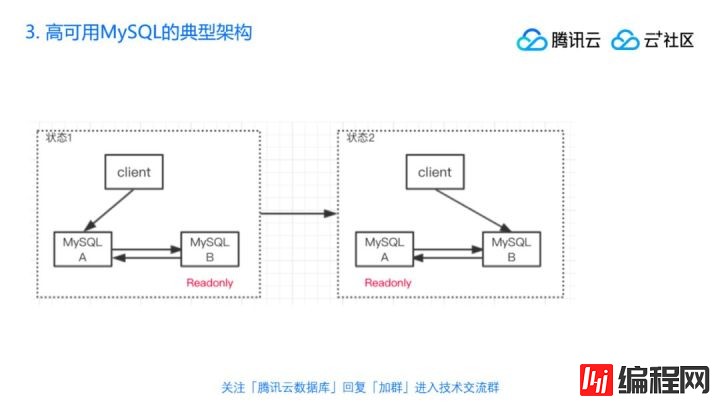
Q14:MySQL双主模型时,数据不一致怎么解决?
A14:我每次说到这个就要特别讲一下,我们这个图里面,说的双主其实是,你在任何一个时刻一边都是Readonly的,状态1的时候B节点是Readonly然后状态2的时候A是Readonly,这种就是比较常见的做法,但是有没有这种多节点写入的方案呢?有几个,比如说像这种方案也可以多写,也就是说客户端既可以往A写也可以往B写,这种如果你用传统的,比如说现在的MySQL的能力,那就要由业务方来保证我写入的数据量两边不冲突,左边都写一个城市数据,右边都写一个城市的数据,然后两边去同步,这样不冲突,这是一种。那当然有MRG还有比如Innodb cluster,它自己会做事务之间的冲突检测,据我了解这个在国内用的并不多,或者说不会把它当为常态互相写,毕竟你两边写,即使你能做到两边不冲突,但是成本会很高。每次要写一个事务的时候,都要去问下另外一个节点能不能写,它告诉我能写才写,不能写我就放弃,那这样的话这个性能就会降下来,所以真正多写的结构,据我了解,有的公司是用在做切换的时候,当我从A切换到B的时候,比如看图中架构,如果我从A切换到B的时候有一段时间内是不可写的,我要把A停写,然后B同步完后,把请求连到B这边,那如果你可以支持多写,中间成本会高些,但是毕竟能写,这样的话我就可以同时往A和B同时写,在很短的时间内把A的更新去掉,这样的业务的好处就是,业务发现完全不停机,不停写,但是也只是用在这么一个短暂的时候,它本身天然就与物理规律有点冲突。
Q15:现在推不推荐上MYSQL8呢?
A15:推荐,已经一年多了,我们自己在腾讯云测试环境上测试8.0的性能还是比5.7好不少,所以今年上半年我们应该会推出MySQL8.0的版本。
Q16:原来业务用Oracle,单机能力很强,现在可以用TDSQL或TBase来替换吗?
A16:我觉得ok,把oracle换成MySQL体系,这个事情呢已经经过证明了,能这么做。
Q17:主从复制是异步的,怎么保证读取数据的一致性?
A17:这是个大问题,因为今天我们确实没有时间提到这个,《MySQL实战45讲》里面有一篇专门讲这个的,有一些方法,比如说,故意慢一点去读,或者说查询的时候有些请求有一定敏感请求放主库等有各种方法,还有一些可以用GTID来解决。
Q18:怎么入门MySQL源码?
A18:如果你真的想入MySQL源码的话,你可以这样,首先你得有一套MySQL源码下载下来,然后你可以开debug日志,执行一个简单语句,debug日志会列出所有调用的函数,然后你就照着函数去数据库源码里面找下看看在哪里,可以给自己一个问题。举个例子,你执行一个select1,当然返回的就是1对不对,你先给自己一个需求,比如我现在想给它写一个bug,这时候返回2,那我该怎么做,可以试试。当然如果你开发功底不错可以考虑我们团队,我们团队天然干这个的。
Q19:读写分离的话,主从同步延迟很大,读的是延后的数据,不是有损伤吗,一些调优的参数都试过了,这时是不是该分库分表了?
A19:如果你的这个主库和从库的配置是一样的,而主库有读写,从库上并没有压力的时候还有延迟,那很可能是因为你的并行度不够,就是你可能没有开启并行复制,你可以开下并行复制试下。如果由于对从库的查询压力过大,导致从库cpu消耗过大,导致延迟,这种情况可以多加几个从库,分库分表当然也是一个解法。什么情况下说需要分库分表呢,就是你主库更新量太大了,大到MySQL开启了并行复制都撑不住的时候,可能需要考虑,这个话题比较复杂,大家可以搜一些文章。

直播互动福利:每晚直播间也同样会送出多份腾讯公仔,更有腾讯徽章、腾讯云代金券等好礼送上!快快预约报名吧!

扫码关注后回复「加群」提前加入沙龙交流群
--结束END--
本文标题: 直播回顾 | 丁奇剖析数据库性能
本文链接: https://lsjlt.com/news/48075.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0