mongoDB不支持join,其官网上推荐的Unityjdbc可以把数据取出来进行二次计算实现join运算,但收费版才有这个功能。其他免费的jdbc drive只能支持最基本的s
mongoDB不支持join,其官网上推荐的Unityjdbc可以把数据取出来进行二次计算实现join运算,但收费版才有这个功能。其他免费的jdbc drive只能支持最基本的sql语句,不支持join。如果用Java等编程语言将数据取出后实现join计算,也比较复杂。
用免费的esProc配合MonGoDB,可以实现join计算。这里通过一个例子来说明一下具体作法。
MongoDB中的文档orders保存了订单数据,employee保存了员工数据。如下:
connecting to: test
> db.orders.find();
{ "_id" :ObjectId("5434f88dd00ab5276493e270"), "ORDERID" : 1,"CLIENT" : "UJRNP
", "SELLERID" : 17,"AMOUNT" : 392, "ORDERDATE" : "2008/11/2 15:28" }
{ "_id" :ObjectId("5434f88dd00ab5276493e271"), "ORDERID" : 2,"CLIENT" : "SJCH"
, "SELLERID" : 6,"AMOUNT" : 4802, "ORDERDATE" : "2008/11/9 15:28"}
{ "_id" :ObjectId("5434f88dd00ab5276493e272"), "ORDERID" : 3,"CLIENT" : "UJRNP
", "SELLERID" : 16,"AMOUNT" : 13500, "ORDERDATE" : "2008/11/5 15:28"}
{ "_id" :ObjectId("5434f88dd00ab5276493e273"), "ORDERID" : 4,"CLIENT" : "PWQ",
"SELLERID" : 9, "AMOUNT" :26100, "ORDERDATE" : "2008/11/8 15:28" }
…
> db.employee.find();
{ "_id" :ObjectId("5437413513bdf2a4048f3480"), "EID" : 1,"NAME" : "Rebecca", "
SURNAME" : "Moore","GENDER" : "F", "STATE" : "California","BIRTHDAY" : "1974-1
1-20", "HIREDATE" :"2005-03-11", "DEPT" : "R&D","SALARY" : 7000 }
{ "_id" :ObjectId("5437413513bdf2a4048f3481"), "EID" : 2,"NAME" : "Ashley", "S
URNAME" : "Wilson","GENDER" : "F", "STATE" : "New York","BIRTHDAY" : "1980-07-
19", "HIREDATE" :"2008-03-16", "DEPT" : "Finance","SALARY" : 11000 }
{ "_id" :ObjectId("5437413513bdf2a4048f3482"), "EID" : 3,"NAME" : "Rachel", "S
URNAME" : "Johnson","GENDER" : "F", "STATE" : "New Mexico","BIRTHDAY" : "1970-
12-17", "HIREDATE" :"2010-12-01", "DEPT" : "Sales","SALARY" : 9000 }
…
Orders中的sellerid对应employee中的eid。需要查询出employee的state属性等于California的所有订单信息。其中orders数据量较大,不能一次装入内存。Employee数据量较小,Orders过滤之后的结果数据量也比较小。
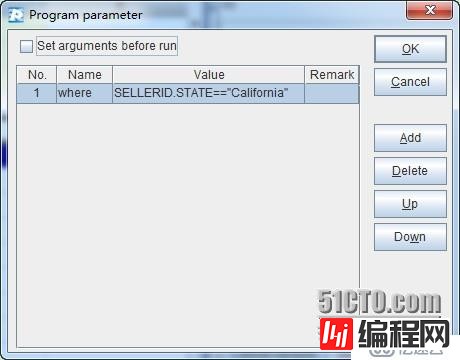
查询条件表达式可以作为参数传递给esProc,如下图:
esProc的程序代码如下:
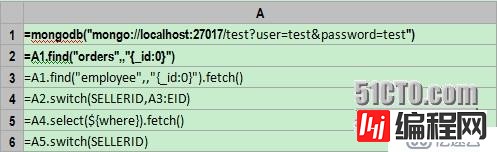
A1: 连接MongoDB数据库,ip和端口号是localhost:27017,数据库是test,用户名和密码都是test。
A2: 使用find函数从MongoDB中取数,形成游标。集合是orders,过滤条件是空,指定键_id不取出。esProc在find函数中采用了和mongdb的find语句一样的参数格式。esProc的游标支持分批读取和处理数据,可以避免数据量过大,内存出现溢出的情况。
A3: 取得employee中的数据。因为数据量不大,所以用fetch函数一次取出。
A4: 使用switch函数,将游标A2中SELLERID字段的值,转换为A3(employee)中的记录引用。
A5: 按照条件过滤。这里使用宏来实现动态解析表达式,其中的where就是传入参数。集算器将先计算${…}里的表达式,将计算结果作为宏字符串值替换${…}之后解释执行。这个例子中最终执行的是:=A4.select(SELLERID.STATE=="California")。由于SELLERID已经转化为employee的对应记录的引用,所以可以直接写SELLERID.STATE。过滤之后的结果数据量较小,所以一次取出。如果结果数据量仍然比较大的话,可以分批取出,比如每次取出10000条:fetch(10000)。
A6:将过滤结果中的SELLERID重新切换为普通值。
A6的计算结果是:
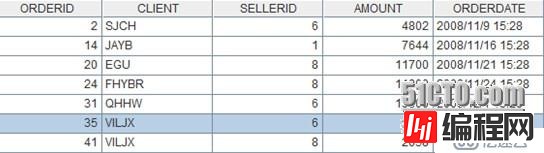
过滤条件发生变化时不用改变程序,只需改变where参数即可。例如,条件变为:state等于California的订单,或者CLIENT等于PWQ的订单。Where的参数值可以写为:CLIENT=="PWQ"||SELLERID.STATE=="California"。
esProc并不包含MongoDB的java驱动包。用esProc来访问MongoDB,必须提前将MongoDB的java驱动包(esProc要求2.12.2或以上版本的驱动,mongo-java-driver-2.12.2.jar)放到[esProc安装目录]\common\jdbc中。
esProc协助MongoDB计算的脚本很容易集成到java中,只要增加一行A7,写成result A6即可向java输出resultset形式的结果,具体的代码参考esProc教程。同样,用java调用esProc访问MongoDB也必须将mongdb的java驱动包放到java程序的classpath中。
集算器esProc的下载地址:Http://www.raqsoft.cn/?p=2643 .
--结束END--
本文标题: 集算器协助MongoDB之表间关联
本文链接: https://lsjlt.com/news/43386.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0