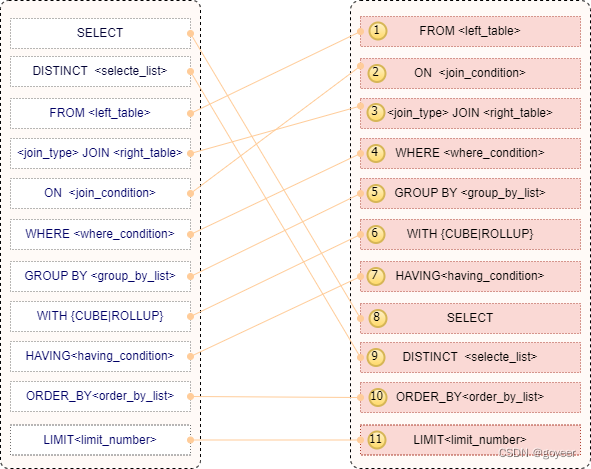
【Mysql系列】- SELECT语句执行顺序 文章目录 【MySQL系列】- SELECT语句执行顺序一、MYSQL逻辑查询处理的步骤图二、MYSQL执行顺序详解2.1 执行FROM操作2.
这一步需要做的是对FROM子句前后的两张表进行笛卡尔积操作,也称作为交叉连接,生成虚拟表VT1。如果FROM子句前的表包含a行数据,FROM子句后的表中包含b行数据,那么虚拟表VT1将包含a*b行数据。
SELECT查询共有3个过滤流程,分别是ON、WHERE、HAVING。ON是最先执行的过滤流程。 在大多数的编程语言中,逻辑表达式的值只有两种:TRUE 和 FALSE。但是在关系数据库中起逻辑表达式作用的并非只有两种,还有一种称为三值逻辑的表达式。这是因为在数据库中对NULL值的比较与大多编程语言不同。在C语言中,NULL == NULL的比较返回的是1,即相等,而在关系型数据库中,NULL的比较就不一样了。对于在ON过滤条件下的NULL值比较,此时的比较结果为UNKNOWN,却被视为FALSE来处理,即两个NULL并不相同。但是在下面两种情况认为两个NULL值的比较是相等的
因此在生成虚拟表VT2的时候,会增加一个额外的列来表示ON过滤条件的返回值,返回值有FALSE 、 TRUE 、 UNKNOWN。
这一步只有在连接类型是OUTER JOIN时才发生,如LEFT OUTER JOIN , RIGHT OUTER JOIN , FULL OUTER JOIN.虽然在大多数时候可以省略OUTER关键字,但OUTER代表的就是外部行。关于保留表:
添加外部行的工作就是在VT2表的基础上添加保留表中被过滤掉的数据,非保留表中的数据被赋NULL值,最后生成虚拟表VT3
对上一步骤产生的虚拟表VT3进行WHERE条件过滤,只有符合
在当前应用WHERE过滤器时,有两种过滤是不被允许的:
此外,在WHERE过滤器中进行的过滤和在ON过滤器中进行的过滤是有所不同的:
在本步骤中根据指定的列对上个步骤中产生的虚拟表进行分组,最后得到虚拟表VT5; MySQL对查询做了加强,使得在GROUP BY 后面可以使用SELECT中定义的别名。
在MySQL中,Group By中可以使用别名;WHERE中不能使用别名;ORDER BY中可以使用别名。在oracle,Hive中别名的使用都是严格遵循SQL执行顺序的,GROUP BY后面不能用别名。
ROLLUP
如果指定了ROLLUP选项,那么将创建一个额外的记录添加到虚拟表VT5的最后,并生成虚拟表VT6
CUBE
对于CUBE选项,MySQL数据库虽然支持该关键字的解析,但是并未实现功能。
在该步骤中对于上一步产生的虚拟表应用HAVING过滤器,HAVING是对分组条件进行过滤的筛选器。生成的虚拟表VT7
虽然SELECT是查询中最先被指定的部分,但是知道步骤8时才真正进行处理,在这一步中,将SELECT中指定的列从上一步产生的虚拟表中选出。
如果在查询中指定了DISTINCT子句,则会创建一张内存临时表VT9(如果内存放不下就放到磁盘上)。这张临时表的表结构和上一步产生的虚拟表一样,不同的是对进行DISTINCT操作的列增加了一个唯一索引,以此来去除重复的数据。
根据ORDER BY子句中指定的列上对上一步输出的虚拟表进行排列,返回新的虚拟表,最后得到的虚拟表VT10。
在该步骤中应用LIMIT子句,从上一步骤的虚拟表中选出从指定位置开始的指定行数据。对于没有应用ORDER BY 的LIMIT子句,结果同样可能是无序的,因此LIMIT语句通常和ORDER BY子句一起使用。
MYSQL语句每个步骤都会产生一个虚拟表,该虚拟表被用作下一个步骤的输入。这些虚拟表对调用者(客户端应用程序或者外部查询)不可用。只有最后一步生成的表才会给调用者。如果没有在查询中指定某一个子句,将跳过相应的步骤。
来源地址:https://blog.csdn.net/songjianlong/article/details/133915449
--结束END--
本文标题: 【MySQL系列】- SELECT语句执行顺序
本文链接: https://lsjlt.com/news/433511.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0