Adaptive Hash Index(以下简称 AHI)估计是 Mysql 的各大特性中,大家都知道名字但最说不清原理的一个特性。本期图解我们为大家解析一下 AHI 是如何构建的。 首先我们思考一下 AHI 是为了解决什么问题: 随着
![图解MySQL | [原理解析] Adaptive Hash Index 是如何建立的](/upload/202205/01/uohvt0sjalb.jpg)
Adaptive Hash Index(以下简称 AHI)估计是 Mysql 的各大特性中,大家都知道名字但最说不清原理的一个特性。本期图解我们为大家解析一下 AHI 是如何构建的。
首先我们思考一下 AHI 是为了解决什么问题:
AHI 在实现上就是一个哈希表:从某个检索条件到某个数据页的哈希表,仿佛并不复杂,但其中的关窍在于哈希表不能太大(哈希表维护本身就有成本,哈希表太大则成本会高于收益),又不能太小(太小则缓存命中率太低,没有任何收益)。
这就是 AHI(中文名:自适应哈希索引)中"自适应"的用途:建立一个"不大不小刚刚好"的哈希表。
本文主要讨论 MySQL 是如何建立起一个"刚刚好"的 AHI 的,如图 1 所示:需要经历三个关卡,才能为某个数据页建立 AHI,之后的查询才能使用到该 AHI。

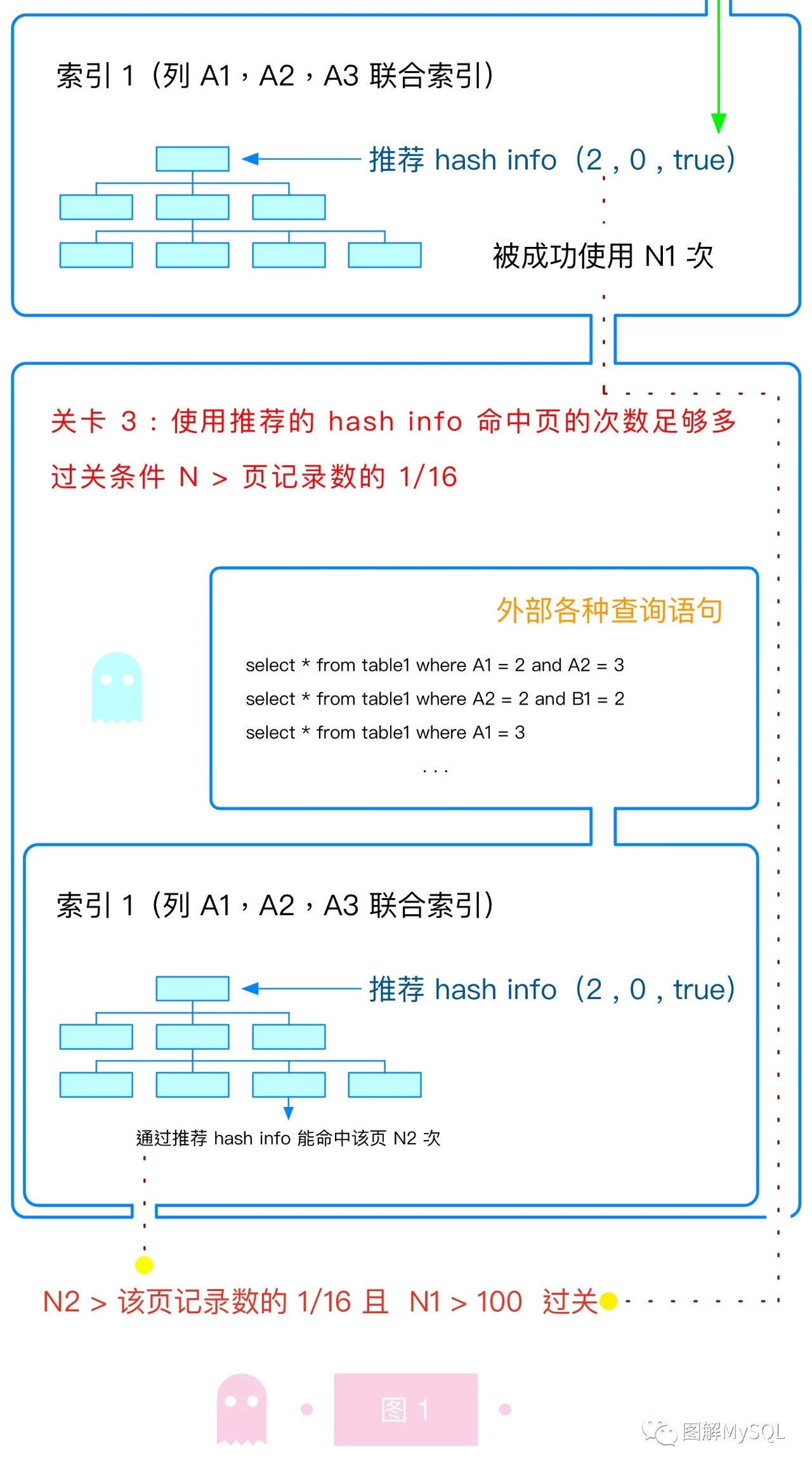
我们逐个关卡来介绍: 关卡 1:某个索引树要被使用足够多次 AHI 是为某个索引树建立的(当该索引树层数过多时,AHI 才能发挥效用)。如果某索引只被使用一两次,就为之建立 AHI,会导致 AHI 太多,维护成本高于收益。因此建立 AHI 的第一关就是:只为频繁使用的索引树建立 AHI。
关卡 2:该索引树上的某个检索条件要被经常使用 显而易见,如果我们为了一个很少出现的检索条件建立 AHI,肯定是入不敷出的。
在此我们插播一个新概念 hash info,hash info 是用来描述一次检索的条件与索引匹配程度(即此次检索是如何使用索引的)。建立AHI时,就可以根据匹配程度,抽取数据中匹配的部分,作为 AHI 的键。关卡 2 就是为了找到经常使用的 hash info。hash info 包括以下三项:
我们通过一个例子来简要介绍 hash info 中第一项。假设一张表 table1,其索引是(A1, A2)两列构成的索引:
关卡 3:该索引树上的某个数据页要被经常使用如果我们为表中所有数据建立 AHI,那 AHI 就失去了缓存的意义:内存已不足以存放其身躯,必然要放到磁盘上,那么其成本显然已经不低于收益。回忆一下,AHI 是为了缩短 B+ 树的查询成本设计的,如果把自己再放到磁盘上,就得变成另一颗 B+ 树(B+ 树算法是处理磁盘查询的高效结构),如此循环往复,呜呼哀哉。
因此我们只能为表中经常被查询的部分数据建立 AHI。所以关卡 3 的任务就是找出哪些数据页是经常被使用的数据页。
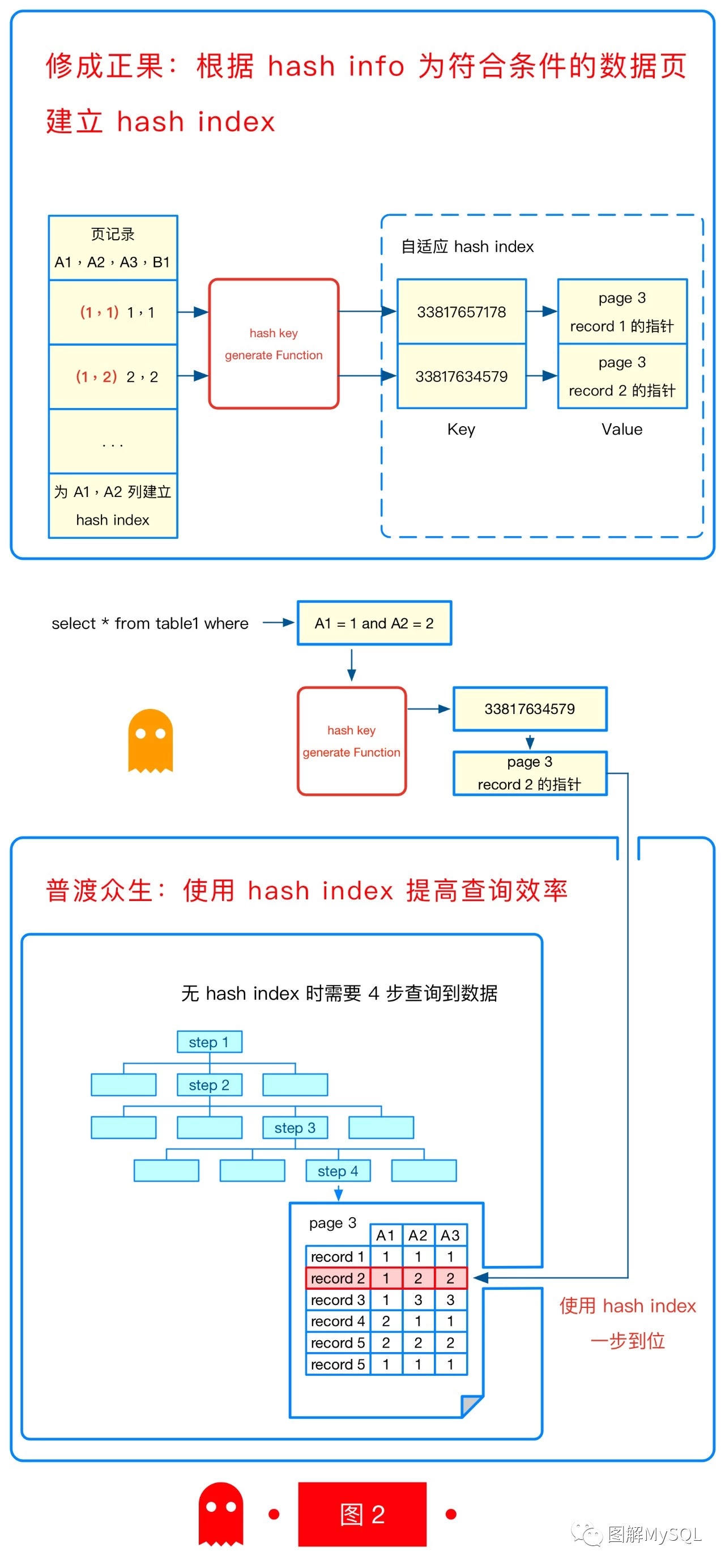
修成正果:终于开始建立 AHI 终于可以开始建立 AHI 了, 我们举个例子说明如何建立 AHI。假设以上三个关卡的通关情况如下:
普度众生:终于可以使用 AHI 我们终于可以 AHI 加速查询了,假设查询条件是 A1=1 and A2=2,其满足条件:
总结 我们回顾一下 MySQL 建立 AHI 的整个过程:
运维建议 理解了 AHI 的建立过程,在运维过程中就更容易理解 AHI 的状态,我们简要盘点一下 AHI 的运维:
--结束END--
本文标题: 图解MySQL | [原理解析] Adaptive Hash Index 是如何建立的
本文链接: https://lsjlt.com/news/4317.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0