Python 官方文档:入门教程 => 点击学习
用 python 微调 ChatGPT (GPT-3.5 Turbo) 备受期待的 GPT-3.5 Turbo 微调功能现已推出,并且为今年秋季即将发布的 GPT-4 微调功能奠定了基础。 这不仅仅
备受期待的 GPT-3.5 Turbo 微调功能现已推出,并且为今年秋季即将发布的 GPT-4 微调功能奠定了基础。 这不仅仅是一次简单的更新——它是一个游戏规则改变者,为开发人员提供了完美定制人工智能模型的关键解决方案,并以前所未有的方式扩展这些自定义模型。 本文将你经历人工智能进化的惊心动魄之旅。

自 ChatGPT 推出以来,人们一直渴望能够塑造和微调 ChatGPT,以获得真正独特的用户体验。今天这个梦想已经实现了。开发人员现在可以进行监督微调,针对各自的用例将模型个性化。 微调就像一根魔杖,可以在各种用例中改变模型性能,具体体现在:
🚀 **增强可控性:**让模型成为你的终极助手。通过微调,你就是老板,指挥它按照你的指令工作,权力由你掌控。
💼 **美化输出格式:**微调可以打磨输出细节,摆脱不稳定的输出格式。现在,你的模型每次都能为你提供完美的格式。无论是代码补全还是精心设计 api 调用,该模型都能以干净、一致的格式为你提供支持。
🎭 **打造风格:**微调可让调节输出内容风格,确保模型与你想要的独特基调一致,使其更加贴合你的需求和场景。
微调不仅可以提高性能,还可以提高性能。借助 GPT-3.5 Turbo,提示可以得到简化,同时保持最佳性能。事实上,Openai 的一些早期测试人员通过将指令直接集成到模型中,将提示词大幅削减了惊人的 90%。 结果是闪电般快速的 API 调用大幅削减了成本。
训练数据需存储在纯文本文件中,每行均为 JSON(*.jsonl 文件),格式如下:
{ "messages": [ { "role": "system", "content": "你是一个智慧幽默的小说家。" }, { "role": "user", "content": "请写一篇20字以内的微型小说。" }, { "role": "assistant", "content": "《夜》\n男:疼么?\n女:恩!\n男:算了?\n女:别!” } ]}系统消息(system)提供系统提示。这告诉模型如何响应。例如,网页版 ChatGPT 的系统提示是:“你是一个有用的助手(You are a helpful assistant)”。
用户消息(user)提供提示词,通常是人们在 ChatGPT 输入框中输入的内容。
助理消息(assistant)提供了你希望模型给出的回答。
上传数据需要用到 openai SDK 和 API Key。通过如下命令安装 openai SDK。
pip install -U openai安装好 SDK 后,通过 openai.File.create方法上传数据集,下面是示例代码:
import openaiopenai.api_key = "YOUR_OPENAI_API_KEY"openai.File.create( file=open('/path/to/your/data.jsonl'), purpose='fine-tune',)上面的代码会返回一个 openai File 对象,其中包含文件大小、创建时间、上传状态和 ID 等信息。您可以通过 ID(类似于“file-xxxxxxx”)来检查 JSONL 文件中是否存在错误。
openai.File.retrieve('your_file_id')通过 openai.FineTuningJob.create创建微调任务
openai.FineTuningJob.create( training_file='your_file_id', model='gpt-3.5-turbo',)上面代码会返回一个 FineTuningJob 对象,其中包含重要信息,例如ID(类似于“ftjob-xxxxxxxx”),可用于检查作业的状态。由于此过程涉及更新大型神经网络的权重,一般需要较长时间(30 分钟、1 小时等),具体取决于你的训练数据量。
你可以用如下方式检查作业的状态:
openai.FineTuningJob.retrieve('ftjob-xxxxxxxx')上面代码将返回一个包含创建时间、完成时间、epoch 数等信息的对象。
如果任务尚未完成,finished_at 字段将为空。另一个字段,fine_tuned_model 也将为空。完成后,此字段将包含模型的 ID,你将在以后的调用中使用该 ID。
检查任务进展情况的另一种方法是使用 list_events 函数。
openai.FineTuningJob.list_events(id='ftjob-xxxxx', limit=10)该函数会返回消息告诉你相关信息,例如训练步骤/损失和该训练步骤的其他指标,以及训练完成后的模型 ID。
模型训练完成后就可以测试你的微调模型了。你可以将其与未微调的 GPT-3.5 Turbo 进行比较,可以按如下方式完成:
completion = openai.ChatCompletion.create( model='gpt-3.5-turbo', messages=[ {"role": "system", "content": "你是一个智慧幽默的小说家。"}, {"role" "user", "content": "请写一篇20字以内的微型小说。"} ])print(completion.choices[0].message)然后,尝试你自己的微调模型(使用从上一步检索到的模型 ID):
completion = openai.ChatCompletion.create( model='ft:gpt-3.5-turbo-xxxx:::' , # your model id messages=[ {"role": "system", "content": "你是一个智慧幽默的小说家。"}, {"role" "user", "content": "请写一篇20字以内的微型小说。"} ])print(completion.choices[0].message)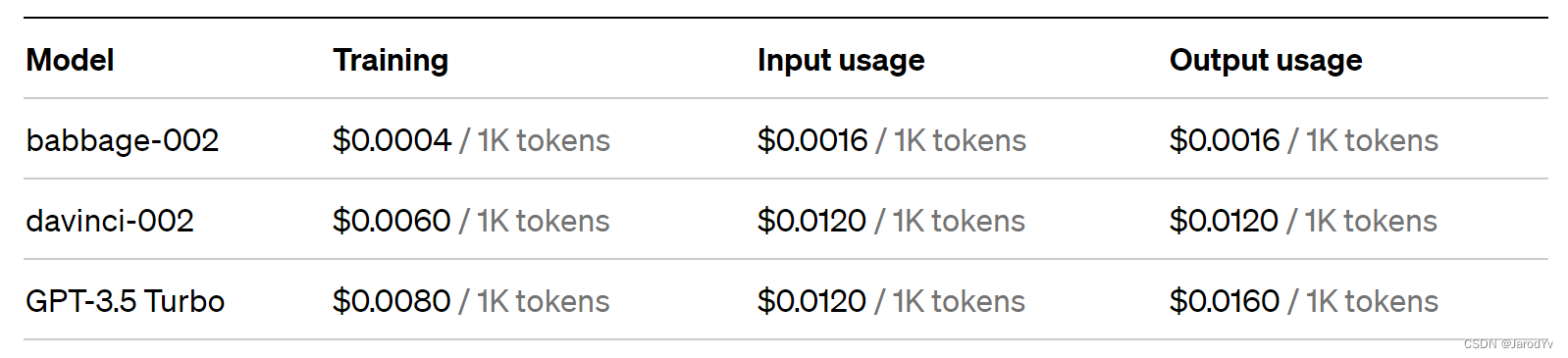
GPT-3.5 Turbo 训练成本为每1千 token 0.0080美元,折合人民币 0.0588 元(6分钱);使用成本输入每1千 token 0.0120美元,折合人民币 0.0881 元(9分钱);输出每1千 token 0.0160美元,折合人民币 0.1175 元(1毛2)。整体上比 GPT-3.5 Turbo 贵了不少。GPT-3.5 Turbo 4K 输入每1千 token 0.0015美元,折合人民币 0.0110元(1分钱),输入每1千 token 0.002美元,折合人民币 0.0147元(1分5)。这样算下来微调 GPT-3.5 Turbo 模型的使用成本是 GPT-3.5 Turbo 的 6 倍多。
当然这部分额外付出的成本能换来更强大的模型,整体投入产出比上还是非常划算的。
来源地址:https://blog.csdn.net/jarodyv/article/details/132758643
--结束END--
本文标题: 用 Python 微调 ChatGPT (GPT-3.5 Turbo)
本文链接: https://lsjlt.com/news/429764.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0