Python 官方文档:入门教程 => 点击学习
前言 如今进行入自媒体行业的人越来越多,短视频也逐渐成为了主流,但好多时候是想如何把视频里面的语音转成文字,比如,录制会议视频后,做会议纪要;比如,网课教程视频,想要做笔记;比如,需要提取视频中文案使
如今进行入自媒体行业的人越来越多,短视频也逐渐成为了主流,但好多时候是想如何把视频里面的语音转成文字,比如,录制会议视频后,做会议纪要;比如,网课教程视频,想要做笔记;比如,需要提取视频中文案使用;比如,需要给视频加个字幕;这时候,只要把视频转文字就好。
对于不是视频编辑专业人员,处理起来还是比较麻烦的,但网上也有好多可以用的小工具,这些工具大多数都标榜有自己技术和模型,但都是在线模型或者使用过一段时间之后就无法再使用了,这些工具实际上都是基于一些大公司提供的接口衍生出来的ai工具,使用效果也不错。但在处理的过程中,处理的文件要上传到大公司的服务器进行处理,这里可能会涉及到一些数据的安全问题。这些数据很大一部分有可能会涉及到数据泄露与安全的问题。
这个项目的核心算法是基于PaddlePaddle的语音识别加python实现,使用的模型可以有自己训练,支持本地部署,支持GPU与CPU推理两种文案,可以处理短语音识别、长语音识别、实现输入的语音识别。
想要把视频里面的语音进行识别,首先要对视频里面的语音进行提取,提取视频里的语音有很多用办法,可以借助视频编辑软件(如Adobe Premiere Pro、Final Cut Pro)中提取音频轨道,然后将其导出为音频文件。 也可以借助工具如FFmpeg或者moviepy,通过命令行将视频中的音频提取出来。
这里使用moviepy对视频里面的语音进行提取,MoviePy是一个功能丰富的Python模块,专为视频编辑而设计。使用MoviePy,可以轻松执行各种基本视频操作,如视频剪辑、视频拼接、标题插入等。此外,它还支持视频合成和高级视频处理,甚至可以添加自定义高级特效。这个模块可以读写绝大多数常见的视频格式,包括GIF。无论使用的是Mac、windows还是linux系统,MoviePy都能无缝运行,可以在不同平台上使用它。
MoviePy与FFmpeg环境安装:
pip install moviepy
pip install ffmpeg
因为使用moviepy提取出视频里面的音轨的比特率不是16000,不能直接输入到语音识别模型里面,这里还要借助FFmpeg的命来把音频采样率转成16000
提取音轨:
def video_to_audio(video_path,audio_path): video = VideoFileClip(video_path) audio = video.audio audio_temp = "temp.wav" if os.path.exists(audio_path): os.remove(audio_temp) audio.write_audiofile(audio_temp) audio.close() if os.path.exists(audio_path): os.remove(audio_path) cmd = "ffmpeg -i " + audio_temp + " -ac 1 -ar 16000 " + audio_path subprocess.run(cmd,shell=True)
PaddleSpeech是一款由飞浆开源全能的语音算法工具箱,其中包含多种领先国际水平的语音算法与预训练模型。它提供了多种语音处理工具和预训练模型供用户选择,支持语音识别、语音合成、声音分类、声纹识别、标点恢复、语音翻译等多种功能。在这里可以找到基于PaddleSpeech精品项目与训练教程:https://aistudio.baidu.com/projectdetail/4692119?contributionType=1
语音识别(Automatic Speech Recognition, ASR) 是一项从一段音频中提取出语言文字内容的任务。

目前 TransfORMer 和 Conformer 是语音识别领域的主流模型,关于这方面的教程可以看飞浆官方发的课程:飞桨PaddleSpeech语音技术课程
我当前的环境是win10,GPU是N卡3060,使用cuda 11.8,cudnn 8.5,为了之后方便封装,使用conda来安装环境,如果没有GPU,也可以装cpu版本:
conda create -n video_to_txt python=3.8
python -m pip install paddlepaddle-gpu==2.5.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
可以从官方git上下载到合适自己的模型:https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/README_cn.md
转换模型:
import argparseimport functoolsfrom ppasr.trainer import PPASRTrainerfrom ppasr.utils.utils import add_arguments, print_argumentsparser = argparse.ArgumentParser(description=__doc__)add_arg = functools.partial(add_arguments, argparser=parser)add_arg('configs', str, 'models/csfw/configs/conformer.yml', '配置文件')add_arg("use_gpu", bool, True, '是否使用GPU评估模型')add_arg("save_quant", bool, False, '是否保存量化模型')add_arg('save_model', str, 'models', '模型保存的路径')add_arg('resume_model', str, 'models/csfw/models', '准备导出的模型路径')args = parser.parse_args()print_arguments(args=args)# 获取训练器trainer = PPASRTrainer(configs=args.configs, use_gpu=args.use_gpu)# 导出预测模型trainer.export(save_model_path=args.save_model, resume_model=args.resume_model, save_quant=args.save_quant)使用模型进行短语音识别:
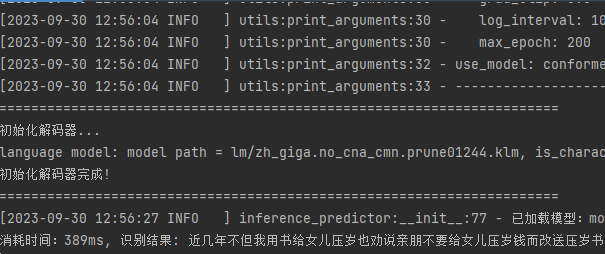
def predict(self, audio_data, use_pun=False, is_itn=False, sample_rate=16000): # 加载音频文件,并进行预处理 audio_segment = self._load_audio(audio_data=audio_data, sample_rate=sample_rate) audio_feature = self._audio_featurizer.featurize(audio_segment) input_data = np.array(audio_feature).astype(np.float32)[np.newaxis, :] audio_len = np.array([input_data.shape[1]]).astype(np.int64) # 运行predictor output_data = self.predictor.predict(input_data, audio_len)[0] # 解码 score, text = self.decode(output_data=output_data, use_pun=use_pun, is_itn=is_itn) result = { 'text': text, 'score': score} return result看看识别结果,是全部整成一块,并没有短句与加标点符号:
可以基于飞浆的ERNIE训练标点行号模型:
添加标点符号代码:
import JSONimport osimport reimport numpy as npimport paddle.inference as paddle_inferfrom paddleNLP.transformers import ErnieTokenizerfrom ppasr.utils.logger import setup_loggerlogger 来源地址:https://blog.csdn.net/matt45m/article/details/133429008
--结束END--
本文标题: 一键智能视频语音转文本——基于PaddlePaddle语音识别与Python轻松提取视频语音并生成文案
本文链接: https://lsjlt.com/news/429292.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0