简介 Xtrabackup是由percona开源的免费数据库热备份软件,它能对InnoDB数据库和XtraDB存储引擎数据库进行非阻塞的备份,其具备以下一些优点: 1)备份速度快,物理备份可靠 2)备
Xtrabackup是由percona开源的免费数据库热备份软件,它能对InnoDB数据库和XtraDB存储引擎数据库进行非阻塞的备份,其具备以下一些优点:
1)备份速度快,物理备份可靠
2)备份过程不会打断正在执行的事务
3)能够基于压缩等功能节约磁盘空间和流量
4)自动备份校验
5)还原速度快
6)可以流传将备份传输到另外一台机器上
7)在不增加服务器负载的情况备份数据
Xtrabackup热备和恢复原理如下图所示:
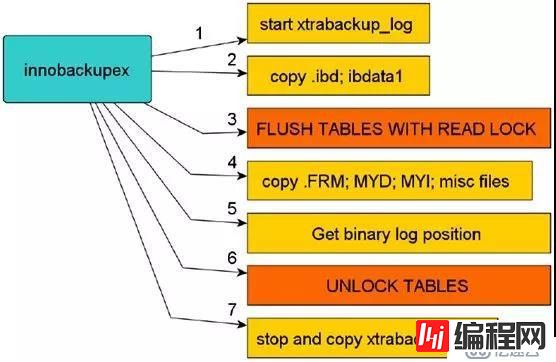
备份开始时首先会开启一个后台检测进程,实时检测Mysql redo的变化,一旦发现redo中有新的日志写入,立刻将日志记入后台日志文件xtrabackup_log中。之后复制innodb的数据文件和系统表空间文件ibdata1,待复制结束后,执行flush tables with read lock操作,复制.frm,MYI,MYD,等文件,最后会发出unlock tables,停止xtrabackup_log。
恢复阶段则启动xtrabackup内嵌的innodb实例,回放xtrabackup日志xtrabackup_log,将提交的事务信息变更应用到innodb数据/表空间,同时回滚未提交的事务(这一过程类似innodb的实例恢复)。如图所示:
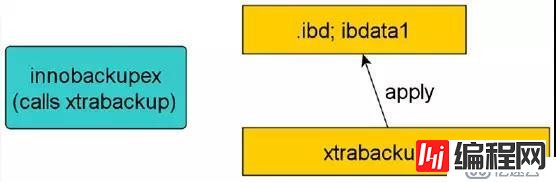
Xtrabackup的增量备份过程和全量类似,只针对增量备份过程中的”增量”进行处理,主要是相对innodb而言,对myisam和其他存储引擎而言,它仍然是全量备份。
从备份恢复的流程上看,备份过程主要受拷贝文件和日志生成速度影响,即和磁盘io、网络以及系统压力有关;恢复过程则主要和IO、并发控制相关,本文下面将主要讨论Xtrabackup恢复阶段的优化。
Xtrabackup的恢复过程实则是调用内嵌innodb的恢复逻辑来实现的(修改了一些参数的默认值,如恢复时buffer pool缓存页面数目),而innodb的恢复一直以来都不是那么的高效,社区也有很多innodb崩溃恢复流程的优化方案。
在实际生产环境中,动辄上T的数据在使用Xtrabackup进行热备时通常要产生几十G甚至更大的日志文件,受限于备份恢复虚拟机的配置,这样的备份在恢复时往往需要数个小时,平均恢复速度仅为1-4M/s(热数据分布相关),这样的速度给现网实例的运维造成了很大的麻烦。
通常情况下,InnoDB的恢复过程中的内存分配类型为MEM_HEAP_BUFFER,即在buffer pool中开辟一段内存用于存放日志记录,当需要恢复的日志文件很大时,可能存在内存不足的情况,根据内存是否充足把日志的处理分为两种方式:
1、开辟的内存足够所有保存日志记录

在内存足够的情况下,日志的解析和回放是串行的,而日志的回放是并行的,可能参与的线程包括主线程以及各个IO线程,极端情况下可能会有log_checkpoint线程以及其他工作线程。
2、开辟的内存不足以保存所有的日志记录
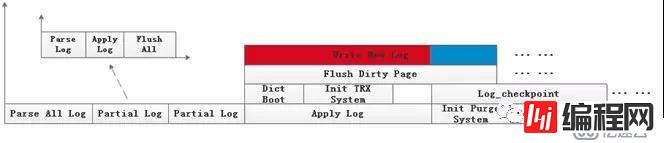
在内存不足的情况下,日志解析需要进行两轮,第一轮解析到某个lsn之后发现内存不足,后续的解析将放弃保存log record到hash table,直到解析完所有日志,最后清空这一轮生成的hash table,第一轮留给下一轮解析的遗产是所有需要打开tablespace的信息和所有DDL相关信息,用于恢复开始时的tablespace构建;第二轮在发现内存不足时,把已经解析的日志全部应用到页面上,此时ibuf的merge是被禁止的(不能产生新的日志),这就需要在应用完日志之后将所有脏页刷盘,并失效buffer pool中的所有页面,最后清空hash table,进行后续日志的解析和回放,剩余逻辑和1相同。
从实际情况看,整体日志恢复速度较慢,平均1-4M每秒,对于数百兆的崩溃恢复以及更大的备份日志恢复来说,这样的速度远远不够。
从以上分析来看,日志解析回放的恢复过程存在以下几个可以优化的地方:
1、日志的解析
2、日志内存不足时的page flush
3、日志解析和回放的并行
log record中没有日志长度信息,由于通常情况下日志是格式化的,解析日志文件推进的过程中需要使用简单的元数据结构体传入到处理函数中,从而计算单条日志的边界,恢复的过程就是从last checkpoint lsn逐条推进到没有合法日志为止,这种元数据结构实则为dict_index_t和dict_table_t结构,日志解析和回放过程中都需要使用这种数据结构,InnoDB的对它们的处理比较粗放,每条log record解析和回放都需要malloc和free以上一对结构。
在mysql社区这两个问题已经被提出,同时也提出了解决方案,如:
1、对应(Bug#82937),解决方案为在log record header中增加长度信息,如下图所示:

如此,log record的边界依靠length即可求到,省去大量元数据结构的malloc和free,以及解析日志格式的函数调用,这一优化可提升解析性能60%。
2、对应(Bug#82176),log record在回放时确实需要元数据结构,但需要的信息远远少于Runtime,根据分析,相同列数的表可以共享此数据结构,在使用前重新初始化一些属性即可,这样就可以通过引入元数据cache来减少不必要的malloc和free。产品实测中,cache对单线程解析有30%+的提升,同样社区也有阿里团队类似的优化贡献。
但从解析角度出发,优化前单核速度可以达到60-80M/s,优化后可以达到120-160M/s,绝对速度已经相当可观。
以innodb5.6的恢复为基准,通常情况下日志文件要被扫描三遍,即解析三次,即便有120M/s的速度,重复的扫描也浪费了一部分的时间,如果对日志解析速度有更高的要求,为了追求更高的解析速度,可以引入多线程并行解析,而能否并行解析的关键在于日志如何有效的切分成若干个完整的分片。
并行解析的可行性建立在能否在以LOG BLOCK组织的连续的日志文件中划分出完整的日志片段这个问题上。InnoDB日志解析的预读缓冲区为RECV_SCAN_SIZE(64K),其实也是分次读取和解析的,但其能通过边界计算处理跨越64K边界的日志记录,跨越边界的整个日志记录将在下一个64K中全部读取,相当于下一次读取的日志块和上一次是有重叠的。
由此,我们按照固定大小(LOG BLOCK的整数倍,如10M)切分日志块,第一个分片的第一个BLOCK的起始位置通过checkpoint lsn定位,其余分片的第一个BLOCK起始位置通过LOG_BLOCK_FIRST_REC_GROUP来确定,如果某个分片内日志不能完整结束,则向下一个分片移动,直到解析出完整的日志为止,分片的移动可能导致两个分片解析到同一个log record,由于日志回放是幂等的,所以重复的日志记录只要按照lsn有序,多次回放不影响正确性。日志文件的分片窗口如下图所示:
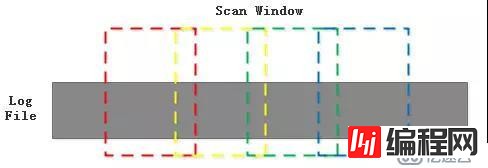
应用并行解析后的恢复流程将减少大量的解析时间,如下图所示:
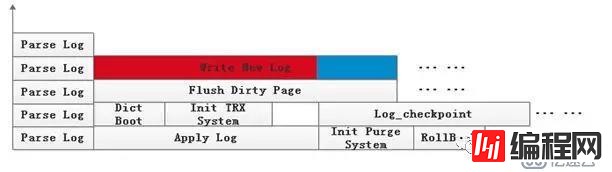
以上分析中,我们发现当分配的buffer pool不足以放下所有日志记录时(大实例绝大多数会发生),日志就会被解析多次,然后分批的进行回放,每次回放完成的页面由于不能执行ibuf merge,只能触发page cleaner全部刷到磁盘,而且当热页面比较分散时,每一轮的回放涉及的页面远远超过Xtrabackup默认的512个页面的buffer,这就导致产生了大量single page的淘汰,每个页面都需要调用一次fil_flush(fsync),形成严重的性能瓶颈,大实例尤为严重。
结合现网Xtrabackup进行热备的方式,发现目前整个备份恢复过程其实是整体完成的(原子的),一次备份(全量或增量)只有完整的恢复完才算成功,如此就可以在page flush上进行比较巧妙的优化,即将恢复阶段所有的page flush改为只写文件缓存,而不调用fli_flush,fsync操作交给操作系统批量调度,换句话说就是将同步的刷脏变成了异步,整个恢复完成时fil_close将会把所有未落盘的脏页全都刷下去,页面淘汰不再成为瓶颈,每一轮的回放速度将大大提升。
如下图所示,日志的解析和回放并行在InnoDB中的大致方案,不同与串行方式,解析过程不再独立存在,而是与回放线程(写新日志)、IO线程以及checkpoint线程并发,这样的并发受限于InnoDB的一些现有机制,如内存管理、刷脏机制、tablespace以及checkpoint机制等,下面将逐一展开分析:
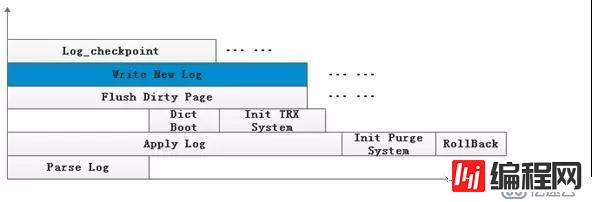
1、内存管理
InnoDB恢复阶段所需内存申请类型为MEM_HEAP_BUFFER,从buffer pool中划分一块内存,大小有限,因此存在先前提到的两阶段解析。由于MEM_HEAP_BUFFER类型的特点,多次申请,统一释放,如果和回放并行,当内存达到上限时,解析不得不停止下来,等待所有日志apply结束,回收内存之后再继续进行解析。
可以将日志解析和回放理解成生产者和消费者,日志回放为消费者,回放过后的日志记录即可回收,将内存类型设置为MEM_HEAP_DYNAMIC,每条日志记录解析时malloc自己的内存,回放结束后将其释放,因为回放是并发的,总体来说内存是大体稳定的。
2、新日志生成
InnoDB通过恢复阶段依然通过log_sys管理日志,ibuf merge产生的日志需要写在同一个日志文件中,但通常情况下,解析线程不结束解析过程是无法得到系统持久化lsn的,因此新日志的起始lsn以及写入日志文件的offset无法确定,从而解析阶段产生新日志通常是不可能实现的。
如果在恢复初期不能得到持久化lsn,将会对生成新日志形成障碍。对于InnoDB的恢复,也有例外存在,如InnoDB如果需要两阶段解析的话,第一阶段结束后系统持久化lsn其实已经可以确定;对于Xtrabackup来说,拷贝得到的日志在拷贝结束时是可以确定结束lsn(即最终持久化的lsn)。因此,对于Xtrabackup的恢复而言,不存在生成新日志的障碍。
最后,InnoDB恢复阶段log_sys中某些属性也在恢复逻辑中被使用,如buffer等,和写日志逻辑是冲突的,需要将log_sys中有冲突的属性转移到recv_sys中实现。
3、刷脏机制和增量checkpoint
InnoDB使用flush list管理脏页面,脏页面在flush list中以首次变脏时的lsn为顺序排序,每当脏页被刷盘之后,就从flush list中将其移除,增量checkpoint机制定时扫描flush list中最小的lsn,以此为checkpoint lsn进行打点,选取打点的lsn必须满足“在flush list中,小于这个lsn的所有修改涉及的页面都在这个lsn所属页面之前”的原则,这个原则直接依赖于页面按照首次变脏lsn有序。
在InnoDB的恢复中,页面在flush list中的顺序不是在解析日志的时候维护的,而是在具体某个页面回放完日志之后才确定的(页面回放完日志之后插入到flush list),由于多线程回放,主线程按照hash table的桶顺序回放,或者按需回放(读取某个页面),因此flush list中脏页的顺序并不完全按照首次修改有序,直到所有的页面都回放完日志,最终的flush list的状态才是完全正确的状态,因此,在InnoDB的恢复中,log_checkpoint才是在所有页面全部回放完日志记录之后进行的。
解析和回放并行势必会产生新的日志,而日志缓冲区和日志文件大小是有限的,如果新日志的产生没有足够的空间,此时还不能做log checkpoint,那么恢复过程可能会卡死;解析和回放并行产生的脏页,在IO允许的情况下,及时持久化并推进checkpoint,避免恢复过程中异常退出之后再次重新恢复。
能否在解析日志时进行checkpoint,根本问题是如何时刻维护flush list的顺序。页面的修改顺序就是其在日志中出现的顺序,其顺序和首次修改完全等价,因此可以在日志解析时peek页面是否在buffer pool中,如果不在则将其load上来,此时不必实际读取页面,只需要在flush list中占一个位置即可,如果从flush list中刷脏页时页面还没有load上来,那么就必须发生一次同步IO。通过这种方式,可以在解析日志时一直维护flush list的顺序,由此解决恢复阶段checkpoint的限制。
4、Tablespace
InnoDB恢复时的fil_space信息从日志记录中类型为MLOG_FILE_NAME的日志获得,因为恢复阶段SYS_TABLESPACE系统表中的记录可能是不完整的,MLOG_FILE_NAME类型的记录在每次tablespace首次变脏或者checkpoint的时候写入日志,为的是在恢复时能够打开所有需要的tablespace(Mysql 5.7.5引入的优化,先前的版本是打开所有ibd文件来load tablespace)。
如下图所示,当最后一次checkpoint发生在lsn为1000时,T1表在checkpoint之后仍然有修改,而T1表的MLOG_FILE_NAME日志在写MLOG_CHECKPOINT之前,在T1的最后一条日志之后。如果解析和回放并发,当T1的最后一条日志需要被重放时,T1的FIL_NAME日志没有解析到,它的tablespace就不会load,此时重放以及后续的IO可能出现问题;系统表有可能还没有恢复,所以此时通过dict_load的方式也是不可行的。
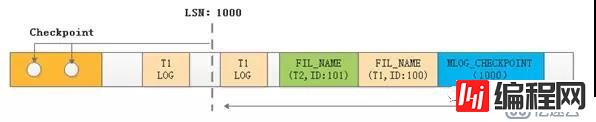
此外,如果某个表在checkpoint之后存在修改,并且在后续的操作中被drop,如下图所示,那么恢复过程可以忽略这个表的日志,因为不需要也不可能恢复(物理文件已经删除,没有tablespace),这个过程是在recv_init_crash_recovery_spaces()中完成的,它要求先将日志全部解析,生成完整的FIL_NAME表,然后统筹那些表不需要恢复。

如果解析和回放并行,Tablespace的Load可以在解析日志前通过扫描所有ibd文件,load所有已存在的tablespace方式完成;或者将当前系统表中已存在的表通过dict_load的方式全部加载,即使此时的tablespace是不完整的。此外,对于删掉或者truncate掉的表,如果在回放日志时fil_space不存在,或者page no超过tablespace的size,则不回放相关日志记录。
从以上可行性分析来看,解析和回放在InnoDB中从理论上是可以实现并行的,但需要一些关键机制的适配,涉及内容比较多,复杂度高,结合性能收益,我们将对实际实施的优化进行取舍。
从收益来看,假设日志解析总时间为Xa,回放总时间为(10-X)a,在引入dict_index cache以及并行解析日志之后,整个解析和回放的时间会提升10/(10-(1-0.7/N)*X))倍,其中0.7为dict_index cache单线程提升的效果,N为并发解析线程数,由公式可以看到,当解析时间占比比较大时,增加并发解析线程数,就能大大提升恢复效率;如果回放时间占比大时,即使将解析和回放并行,收益也是很有限的。
综上,鉴于解析和回放并行的高复杂度和有限的收益以及解析和回放代价占比,目前恢复的优化方案主要针对单线程的解析优化和页面的刷盘优化,具体实施方案如下:
1、dict_index cache
对每一个独立的解析线程,增加线程级cache(避免不必要的锁开销),cache的搜索key为列数,两个列数相同的表共享一对dict_index和dict_table结构,使用前需要重新初始化结构上的一些字段。
对于主线程、若干个IO线程以及可能执行回放任务的checkpoint线程,也增加线程级cache,用于回放阶段的优化
2、控制多次解析
首先将innodb 5.6中最多扫描日志三次的机制改为最多扫描两次,其实是消除mlog_checkpoint的作用;提供配置参数,配置在热备产生大量日志的情况下,跳过第一轮log record加入log hash table的操作,使得第一轮扫描变为快速构造tablespace,对高负载的小实例热备有一些作用,参考生成日志文件大小和buffer pool的大小进行配置。
3、延迟刷脏
提供配置参数,配置在恢复阶段脏页刷盘方式,实施异步刷脏。
开发机:Dev-VD2
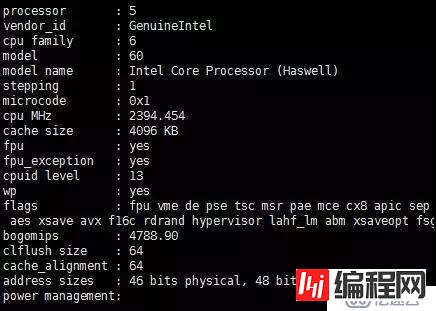
数据库参数
port=3306
max_connections=100
innodb_buffer_pool_size=4G
innodb_buffer_pool_instances=2
innodb_file_per_table=1
innodb_flush_log_at_trx_commit=0
innodb_log_buffer_size=512M
innodb_log_file_size=1G
目前,所有5.6版本(之前)日志解析都需要默认进行三次,结合Xtrabackup自身的特点,两次完全足够,本章节就不再对比解析三次的测试。(单位ms)
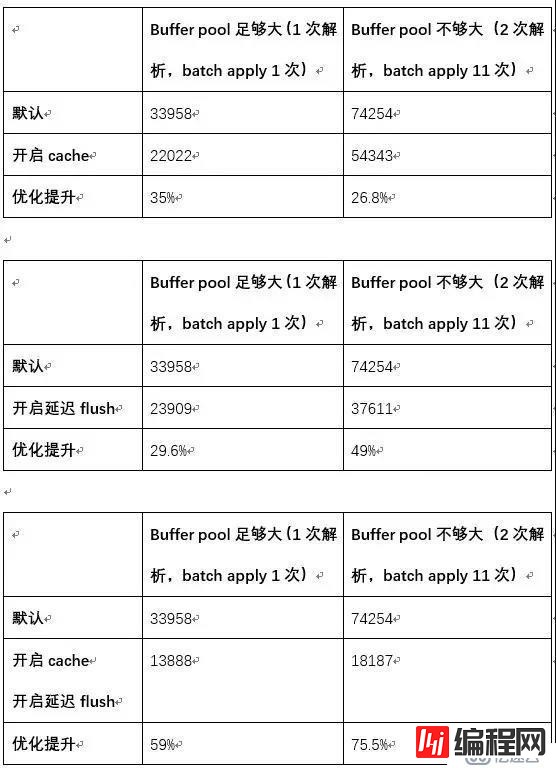
以上测试均是小实例、虚拟机上的测试对比,这些优化在不同场景下提升幅度各有不同,大部分在30%-75%之间,受系统负载,IO,热数据分布等因素影响;现网中一个2T的实例,某次热备产生20G的日志,优化后恢复时间从原先的4小时降低到10分钟,恢复速度大幅提升了20余倍。
针对不同场景的实例,可以进一步的深度优化,如前所述的并行解析、日志格式引入长度信息(需考虑兼容性问题)、结合Xtrabackup自身tablespace处理特点优化tablespace的构建等;InnoDB恢复时日志相关的内存管理比较粗放,也有优化的空间;此外,恢复阶段的锁如recv_sys的mutex、fli_system的mutex、flush list的mutex以及buffer pool的mutex都有一定的优化空间。
不管采用何种方式优化,当实例和日志很大时,解析优化所带来的效果将会越来越小,其在整个恢复过程中已不再成为瓶颈,瓶颈一般都会转移到IO上来,因此后续的优化需要结合特定场景具体分析,有的放矢地进行针对性的优化。
--结束END--
本文标题: 如何让xtrabackup恢复速度提升20倍?
本文链接: https://lsjlt.com/news/41977.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0