flink cdc 介绍及使用 FlinkCDC读取Mysql 及 jdbc 连接参数配置、官方案例 1. Flink cdc 介绍2. 常见cdc开源方案3. Flink cdc 使用案例3

CDC 的全称是 Change Data Capture ,在广义的概念上,只要是能捕获数据变更的技术,我们都可以称之为 CDC。
目前通常描述的 CDC 技术主要面向数据库的变更,是一种用于捕获数据库中数据变更的技术。CDC 技术的应用场景非常广泛;
Flink 的 cdc 是基于日志的:实时消费日志,流处理,例如 mysql 的 binlog 日志完整记录了数据库中的变更,可以把 binlog文件当作流的数据源;保障数据一致性,因为 binlog 文件包含了所有历史变更明细;保障实时性,因为类似 binlog的日志文件是可以流式消费的,提供的是实时数据。

修改配置文件
vi /etc/my.cnfmy.cnf文件内容
# 第一个参数是打开binlog日志log_bin=ON# 第二个参数是binlog日志的基本文件名,后面会追加标识来表示每一个文件log_bin_basename=/usr/local/mysql/log-bin/mysql-bin# 第三个参数指定的是binlog文件的索引文件,这个文件管理了所有的binlog文件的目录log_bin_index=/usr/local/mysql/log-bin/mysql-bin.index修改完成后 查看 binlog 开启状态
show variables like '%log_bin%';如下图所示 ON 为开启状态

flink-connector-mysql-cdc 2.2 版本之前没有找到关于 jdbc 连接参数的配置,此处以 2.2 为主
<dependencies> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>1.7.21</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.21</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.11</artifactId> <version>1.13.0</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.13.0</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_2.11</artifactId> <version>1.13.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.1.3</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.49</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner-blink_2.11</artifactId> <version>1.13.0</version> </dependency> <!--mysql cdc --> <dependency> <groupId>com.ververica</groupId> <artifactId>flink-connector-mysql-cdc</artifactId> <version>2.2.0</version><!-- <scope>provided</scope>--> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastJSON</artifactId> <version>1.2.75</version> </dependency> <!--kafka--> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.1.1</version> </dependency> <!--本地调试flink ui--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-runtime-WEB_2.11</artifactId> <version>1.13.0</version> <scope>compile</scope> </dependency> </dependencies>Flink cdc
package flink_cdc;import com.ververica.cdc.connectors.mysql.source.MySqlSource;import com.ververica.cdc.connectors.mysql.table.StartupOptions;import org.apache.flink.api.common.eventtime.WatermarkStrategy;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.Properties;public class FlinkCDC_Mysql { public static void main(String[] args) throws Exception { //创建执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); Properties prop = new Properties(); prop.setProperty("autoReconnect","true"); //创建 Flink-MySQL-CDC 的 Source //initial (default): 在第一次启动时对被监视的数据库表执行初始快照,并继续读取最新的binlog (开启断点续传后从上次消费offset继续消费) //latest-offset: 永远不要在第一次启动时对被监视的数据库表执行快照,只从binlog的末尾读取,这意味着只有自连接器启动以来的更改 //timestamp: 永远不要在第一次启动时对监视的数据库表执行快照,直接从指定的时间戳读取binlog。使用者将从头遍历binlog,并忽略时间戳小于指定时间戳的更改事件 //specific-offset: 不允许在第一次启动时对监视的数据库表进行快照,直接从指定的偏移量读取binlog。 MySqlSource<String> build = MySqlSource.<String>builder() .serverTimeZone("UTC") .hostname("localhost") .port(3306) .username("root") .passWord("123456") .databaseList("test") //tableList为可选配置项,如果不指定该参数,则会读取上一个配置下的所有表的数据,注意:指定的时候需要使用"db.table"的方式 .tableList("test.test") .startupOptions(StartupOptions.latest()) //自定义反序列化器 .deserializer(new FlinkCdcDataDeserializationSchema()) //jdbc连接参数配置 .jdbcProperties(prop) .build(); //使用 CDC Source 从 MySQL 读取数据 DataStreamSource<String> mysqlDS = env.fromSource(build, WatermarkStrategy.noWatermarks(), "MysqlSource"); //打印数据 mysqlDS.printToErr("------>").setParallelism(1); mysqlDS.addSink(new MysqlSink()); //6.执行任务 env.execute("FlinkCDC_mysql"); }}自定义反序列化类
自定义反序列化类解析读入mysql的binlog为指定的json格式(实现接口DebeziumDeserializationSchema重写deserialize、getProducedType方法)
package flink_cdc;import com.alibaba.fastjson.JSONObject;import com.ververica.cdc.debezium.DebeziumDeserializationSchema;import io.debezium.data.Envelope;import org.apache.flink.api.common.typeinfo.TypeInfORMation;import org.apache.flink.util.Collector;import org.apache.kafka.connect.data.Field;import org.apache.kafka.connect.data.Struct;import org.apache.kafka.connect.source.SourceRecord;public class FlinkCdcDataDeserializationSchema implements DebeziumDeserializationSchema<String> { @Override public void deserialize(SourceRecord sourceRecord, Collector<String> collector) throws Exception { Struct valueStruct = (Struct)sourceRecord.value(); Struct sourceStruct = valueStruct.getStruct("source"); //获取数据库名称,表名,操作类型 String database = sourceStruct.getString("db"); String table = sourceStruct.getString("table"); String type = Envelope.operationFor(sourceRecord).toString().toLowerCase(); if (type.equals("create")) type="insert"; JSONObject jsonObject = new JSONObject(); jsonObject.put("database",database); jsonObject.put("table",table); jsonObject.put("type",type); //格式转换 Struct beforeStruct = valueStruct.getStruct("before"); JSONObject beforeDataJson = new JSONObject(); if (beforeStruct != null) { for (Field field : beforeStruct.schema().fields()) { beforeDataJson.put(field.name(),beforeStruct.get(field)); } } Struct afterStruct = valueStruct.getStruct("after"); JSONObject afterDataJson = new JSONObject(); if (afterStruct != null) { for (Field field : afterStruct.schema().fields()) { afterDataJson.put(field.name(),afterStruct.get(field)); } } jsonObject.put("beforeData",beforeDataJson); jsonObject.put("afterData",afterDataJson); //向下游传递数据 collector.collect(jsonObject.toJSONString()); } @Override public TypeInformation<String> getProducedType() { return TypeInformation.of(String.class); }}Mysql Sink
不需要可忽略
package flink_cdc;import com.alibaba.fastjson.JSONObject;import org.apache.flink.configuration.Configuration;import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;import java.sql.Connection;import java.sql.DriverManager;import java.sql.PreparedStatement;public class MysqlSink extends RichSinkFunction<String> { Connection connection = null; PreparedStatement insertSmt = null; @Override public void open(Configuration parameters) throws Exception { String url = "jdbc:mysql://localhost:3306/test?autoReconnect=true&useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=false"; connection = DriverManager.getConnection(url,"root","123456"); insertSmt = connection.prepareStatement("REPLACE into test2(id,name) values (?,?)"); } @Override public void invoke(String value, Context context) throws Exception { System.err.println(value); JSONObject jsonObject = JSONObject.parseObject(value); System.out.println(jsonObject.get("afterData")); TestBean afterData = JSONObject.parseObject(JSONObject.toJSONString(jsonObject.get("afterData")), TestBean.class); //直接执行更新语句 insertSmt.setInt(1,afterData.getId()); insertSmt.setString(2,afterData.getName()); insertSmt.execute(); } @Override public void close() throws Exception { insertSmt.close(); connection.close(); }}sink测试实体
package flink_cdc;public class TestBean { private int id; private String name; public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; }}基于 Flink CDC 构建 MySQL 和 Postgres 的 Streaming ETL
假设我们正在经营电子商务业务,商品和订单的数据存储在 MySQL 中,订单对应的物流信息存储在 Postgres 中。 对于订单表,为了方便进行分析,我们希望让它关联上其对应的商品和物流信息,构成一张宽表,并且实时把它写到 elasticsearch 中。
通过Flink Mysql/Postgres CDC 来实现这个需求,系统的整体架构如下图所示:
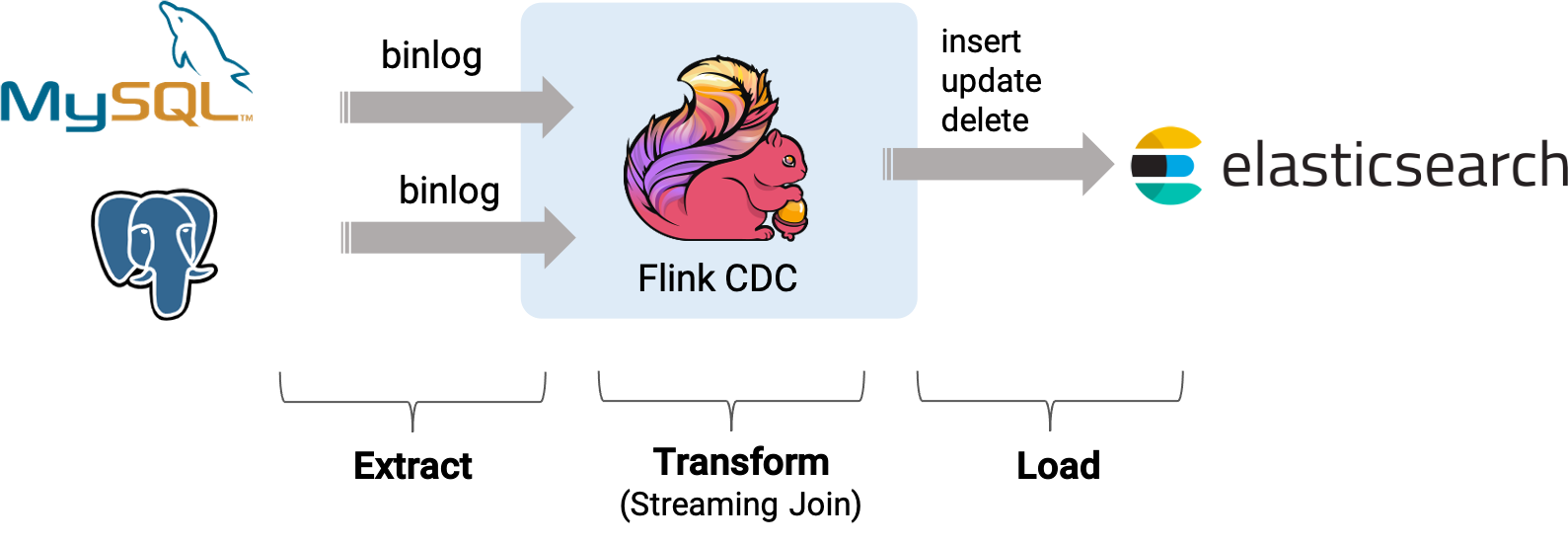
基于 Flink CDC 同步 MySQL 分库分表构建实时数据湖
在 OLTP 系统中,为了解决单表数据量大的问题,通常采用分库分表的方式将单个大表进行拆分以提高系统的吞吐量。 但是为了方便数据分析,通常需要将分库分表拆分出的表在同步到数据仓库、数据湖时,再合并成一个大表。
将数据从 MySQL 同步到 Iceberg 为例的整个流程,架构图如下所示:
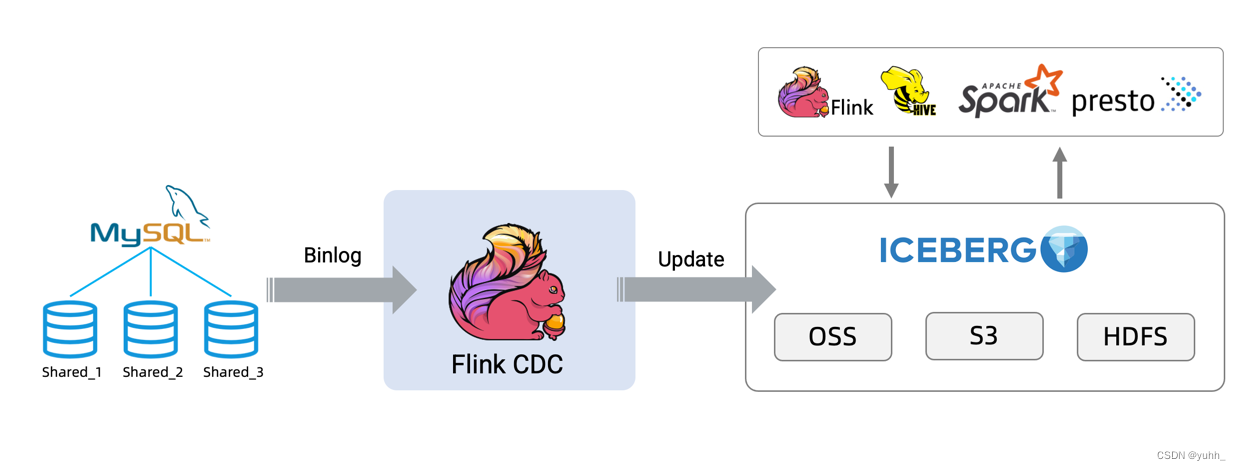
也可以使用不同的 source 比如 oracle/Postgres 和 sink 比如 Hudi 来构建自己的 ETL 流程。
Flink cdc 官方文档地址:https://ververica.GitHub.io/flink-cdc-connectors/master/index.html
来源地址:https://blog.csdn.net/haoheiao/article/details/126519588
--结束END--
本文标题: Flink cdc 介绍及使用 FlinkCDC读取mysql 及 jdbc 连接参数配置
本文链接: https://lsjlt.com/news/409707.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0