Python 官方文档:入门教程 => 点击学习
文章目录 一、urllib的基本用法二、urllib类型和方法类型方法 三、urllib下载下载网页下载图片下载视频 四、请求对象的定制五、编解码1.get请求方式urllib.par
获取百度首页的源码
定义一个url (要访问的地址)
url = 'Http://www.baidu.com'模拟浏览器向服务器发送请求(response响应)
response = urllib.request.urlopen(url)获取响应中的页面源码
content = response.read()打印数据
print(content)输出:
read方法 返回的是字节形式的二进制数据,所以输出的是一堆看不懂的东西
我们这时候就要将二进制数据转换成字符串
二进制 ——>字符串 (这个过程叫做解码)
解码:decode(‘编码的格式’)
content = response.read().decode('utf-8')这时候输出为:
总代码块:
import urllib.requesturl = 'http://www.baidu.com'response = urllib.request.urlopen(url)content = response.read().decode('utf-8')print(content)输出response的类型
print(type(response))输出结果:
response是HTTPResponse的类型
1. 按照一个字节一个的去读
content = response.read()print(content)返回多少个字节,括号里就填多少
content = response.read(5)print(content)2. 读取一行
content = response.readline()print(content)3. 一行一行的读,直到读完为止
content = response.readlines()print(content)4. 返回状态码,可以查看写的有没有问题
print(response.getcode())这里返回的是:200,那就证明我们的逻辑没有错
5. 返回url(http://www.baidu.com)
print(response.geturl())6. 获取状态信息
print(response.getheaders())总结:
url代表的下载路径 filename是文件的名字
在python中,可以写变量的名字,也可以直接写值
import urllib.requesturl_page = 'http://www.baidu.com'urllib.request.urlretrieve(url_page, 'baidu.html')先在网站上找到要下载的图片,并复制图片地址/链接
将地址写入代码中
url_img = 'https://ts1.cn.mm.bing.net/th/id/R-C.5859dafce1fb55e11b2b283D2fa9dc6b?rik=cUDFlghg9sfiBQ&riu=http%3a%2f%2f5b0988e595225.cdn.sohucs.com%2fimages%2f20200322%2f82948cdc4da74564a6968b471783444c.jpeg&ehk=d7X5lIX%2f%2fqEtF5OjxRKT9Hxm9cTlkLLocNXptXKPBg0%3d&risl=&pid=ImgRaw&r=0'urllib.request.urlretrieve(url=url_img, filename='lisa.jpg')运行后会生成图片文件:
先找到要下载视频的url
打开视频界面的开发者工具 找到视频的src后面跟的就是视频地址
找到视频的src后面跟的就是视频地址
将地址写入代码中,并生成.mp4文件
url_video = 'blob:https://www.iqiyi.com/58d4730b-288a-44f0-bed5-38c494a1f6e5'urllib.request.urlretrieve(url_video, '123.mp4')用https的协议访问
import urllib.requesturl = 'https://www.baidu.com'response = urllib.request.urlopen(url)content = response.read().decode('utf-8')print(content)# 访问失败!!!UA介绍:User Agent中文名为用户代理,简称UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU类型、浏览器及版本、浏览器内核、浏览器渲染引擎、浏览器语言、浏览器插件等
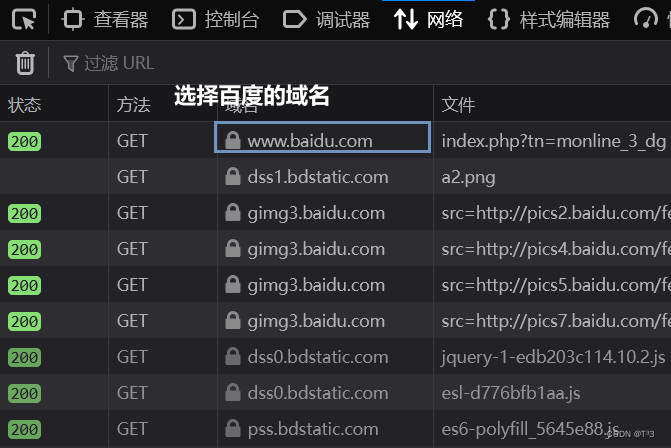
打开一个百度首页,找到UA所在位置
 检查界面:
检查界面:
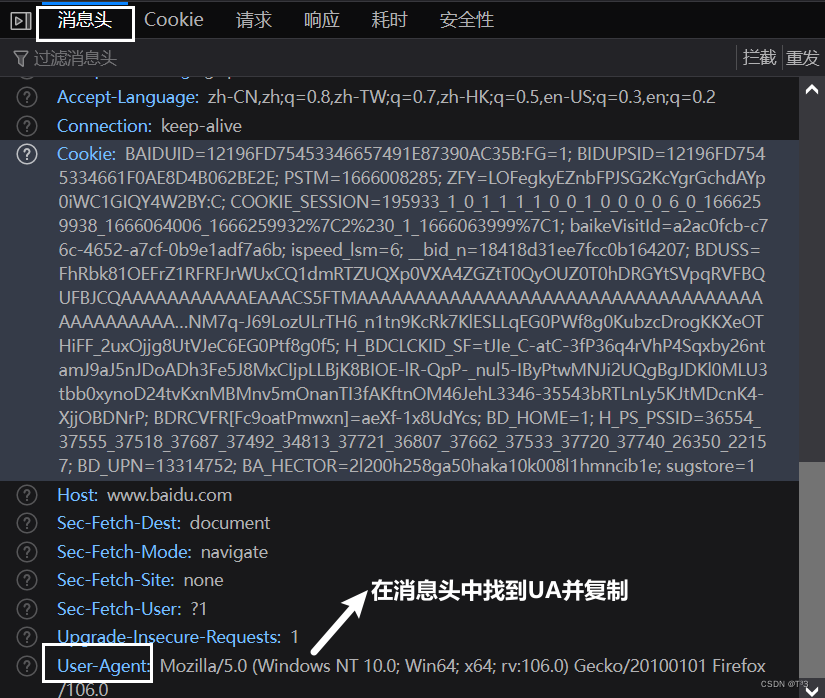
定义一个字典,将UA放入字典中
headers = {'User-Agent': 'Mozilla/5.0 (windows NT 10.0; Win64; x64; rv:106.0) Gecko/20100101 Firefox/106.0'}因为urlopen中不能存储字典类型的数据
 所以headers不能传递进去
所以headers不能传递进去
这时候就需要请求对象的定制
request = urllib.request.Request(url=url, headers=headers)注意:因为参数问题 不能直接写url和headers,中间还有data,所以我们需要关键字传参
https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6
获取百度搜索周杰伦的页面
url = url = 'https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6'定制请求对象
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:106.0) Gecko/20100101 Firefox/106.0'}将周杰伦三个字变成unicode编码的格式(urllib.parse)
name = urllib.parse.quote('周杰伦')请求对象的定制
request = urllib.request.Request(url=url, headers=headers)模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)获取响应内容
content = response.read().decode('utf-8'总代码:
import urllib.requesturl = 'https://www.baidu.com/s?wd='headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:106.0) Gecko/20100101 Firefox/106.0'}name = urllib.parse.quote('周杰伦')url = url + namerequest = urllib.request.Request(url=url, headers=headers)response = urllib.request.urlopen(request)content = response.read().decode('utf-8')print(content)urlencode:适用于多个参数的时候
获取页面源码
https://www.baidu.com/s?wd=周杰伦&sex=男&location=中国台湾省
import urllib.parsedata = { 'wd': '周杰伦', 'sex': '男'}a = urllib.parse.urlencode(data)print(a)# wd=%E5%91%A8%E6%9D%B0%E4%BC%A6&sex=%E7%94%B7多个参数需要变成encode的时候
import urllib.requestimport urllib.parsebase_url = 'https://www.baidu.com/s?'data = { 'wd': '周杰伦', 'sex': '男', 'location': '中国台湾省'}new_data = urllib.parse.urlencode(data)url = base_url + new_dataheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:106.0) Gecko/20100101 Firefox/106.0'}request = urllib.request.Request(url=url, headers=headers)response = urllib.request.urlopen(request)content = response.read().decode('utf-8')print(content)先打开百度翻译的界面,输入一个词,打开开发者工具,找到post请求的sug文件
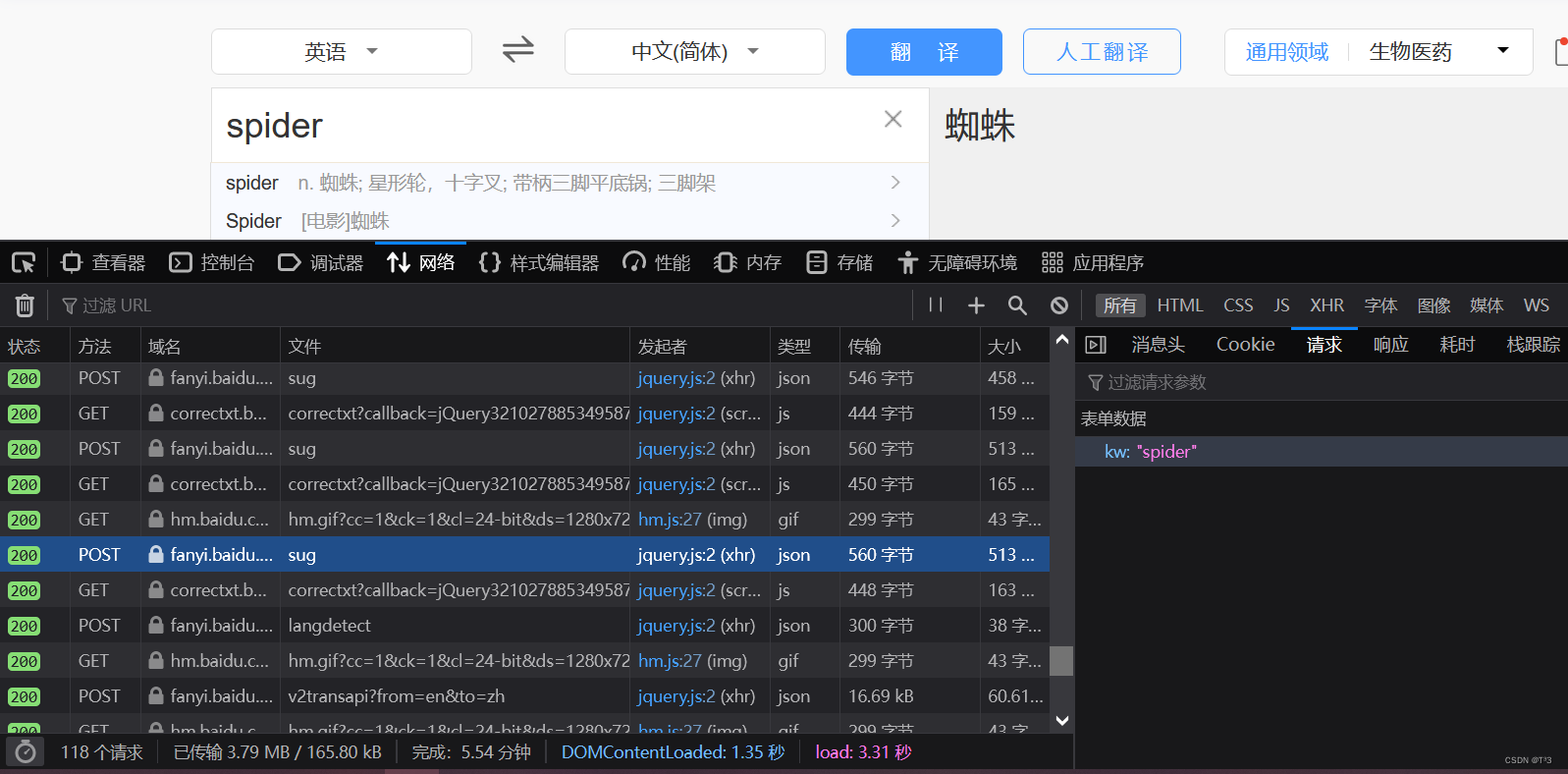 kw=spider
kw=spider
复制URL地址
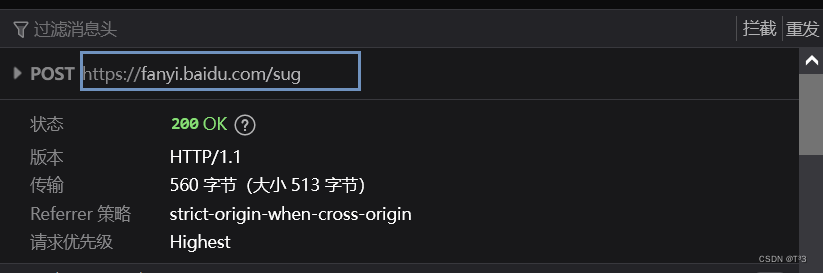 开始编写代码:
开始编写代码:
请求路径的URL
url = 'https://fanyi.baidu.com/sug'请求头
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:106.0) Gecko/20100101 Firefox/106.0'}请求参数
data = { 'kw': 'spider'}post的请求参数 必须要进行编码(encode(‘utf-8’))
data = urllib.parse.urlencode(data).encode('utf-8')post的请求参数,是不会拼接在url的后面的,而是需要放在请求对象定制的参数中
request = urllib.request.Request(url=url, data=data, headers=headers)获取相应数据
content = response.read().decode('utf-8')总代码块
import urllib.requestimport urllib.parseurl = 'https://fanyi.baidu.com/sug'headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:106.0) Gecko/20100101 Firefox/106.0'}data = { 'kw': 'spider'}data = urllib.parse.urlencode(data).encode('utf-8')request = urllib.request.Request(url=url, data=data, headers=headers)response = urllib.request.urlopen(request)content = response.read().decode('utf-8')print(content)这里的content的类型是str
字符串——>JSON对象
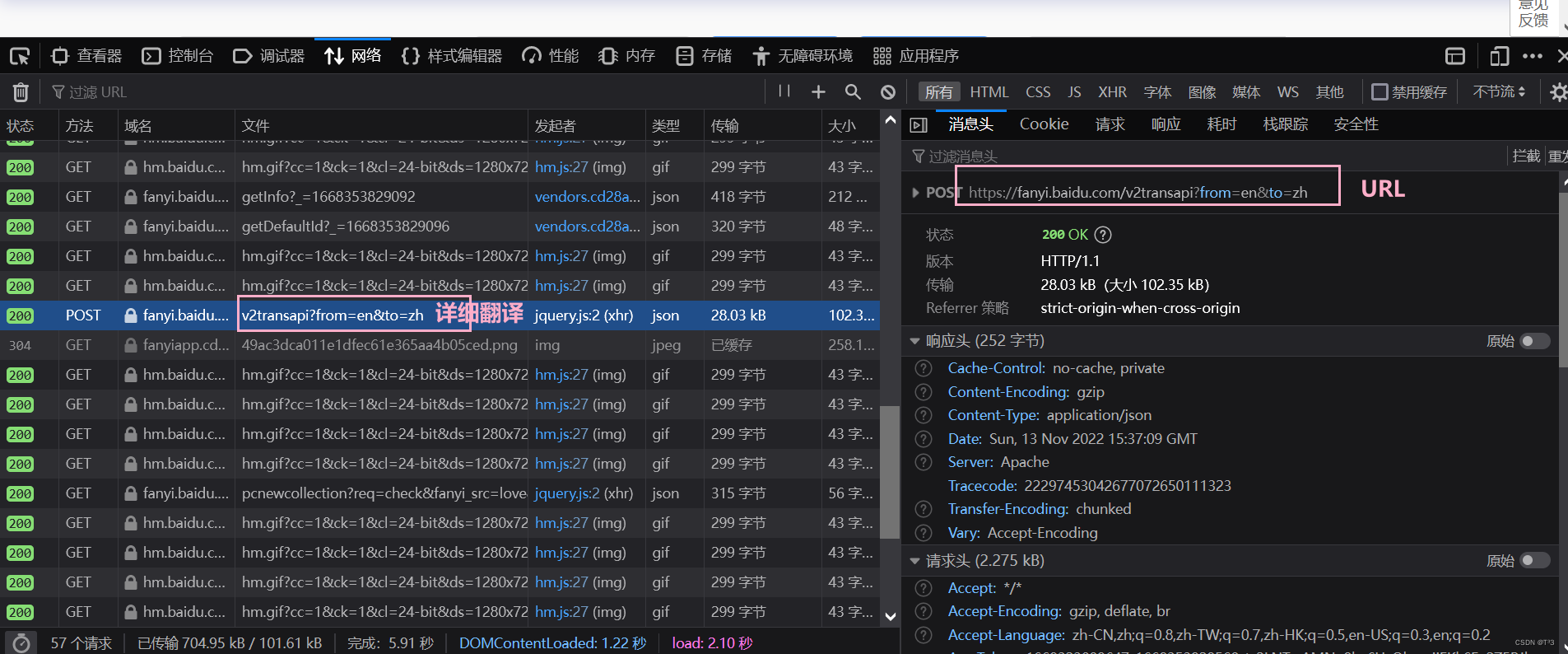
import jsonobj = json.loads(content)print(obj)先复制URL
https://fanyi.baidu.com/v2transapi?from=en&to=zh
请求头
在所有请求头中,找到起作用的一个——cookie
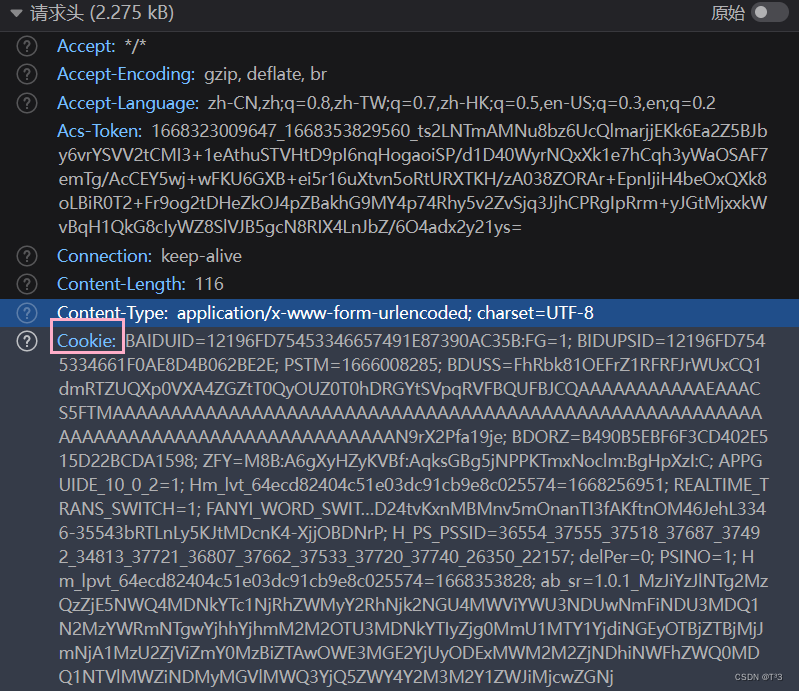 3.在表单数据中找到请求参数
3.在表单数据中找到请求参数

代码实现:
import urllib.requestimport urllib.parseurl = 'https://fanyi.baidu.com/v2transapi?from=en&to=zh'headers = { 'Cookie': 'BAIDUID=12196FD75453346657491E87390AC35B:FG=1; BIDUPSID=12196FD7545334661F0AE8D4B062BE2E; PSTM=1666008285; BDUSS=FhRbk81OEFrZ1RFRFJrWUxCQ1dmRTZUQXp0VXA4ZGZtT0QyOUZ0T0hDRGYtSVpqRVFBQUFBJCQAAAAAAAAAAAEAAACS5FTMAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAN9rX2Pfa19je; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; ZFY=M8B:A6gXyHZyKVBf:AqksGBg5jNPPKTmxNoclm:BgHpXzI:C; APPGUIDE_10_0_2=1; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1668256951; REALTIME_TRANS_SWITCH=1; FANYI_Word_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; BDSFRCVID=umLOJeC62ZlGj87jjNM7q-J69LozULrTH6_n1tn9KcRk7KlESLLqEG0PWf8g0KubzcDrogKKXeOTHiFF_2uxOjjg8UtVJeC6EG0Ptf8g0f5; H_BDCLCKID_SF=tJIe_C-atC-3fP36q4rVhP4Sqxby26ntamJ9aJ5nJDoADh3Fe5J8MxCIjpLLBjK8BIOE-lR-QpP-_nul5-IByPtwMNJi2UQgBgjdkl0MLU3tbb0xynoD24tvKxnMBMnv5mOnanTI3fAKftnOM46JehL3346-35543bRTLnLy5KJtMDcnK4-XjjOBDNrP; H_PS_PSSID=36554_37555_37518_37687_37492_34813_37721_36807_37662_37533_37720_37740_26350_22157; delPer=0; PSINO=1; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1668353828; ab_sr=1.0.1_MzJiYzJlNTg2MzQzZjE5NWQ4MDNkYTc1NjRhZWMyY2RhNjk2NGU4MWViYWU3NDUwNmFiNDU3MDQ1N2MzYWRmNTgwYjhhYjhmM2M2OTU3MDNkYTIyZjg0MmU1MTY1YjdiNGEyOTBjZTBjMjJmNjA1MzU2ZjViZmY0MzBiZTAwOWE3MGE2YjUyODExMWM2M2ZjNDhiNWFhZWQ0MDQ1NTVlMWZiNDMyMGVlMWQ3YjQ5ZWY4Y2M3M2Y1ZWJiMjcwZGNj'}data = { 'from': 'en', 'to': 'zh', 'query': 'love', 'simple_means_flag': '3', 'sign': '198772.518981', '填写自己的token', 'domain': 'common'}# post请求的参数必须进行编码 并且要调用data = urllib.parse.urlencode(data).encode('utf-8')# 请求对象的定制request = urllib.request.Request(url=url, data=data, headers=headers)# 模拟浏览器向服务器发送请求response = urllib.request.urlopen(request)# 获取响应数据content = response.read().decode('utf-8')import jsonobj = json.loads(content)print(obj)获取到了数据:

来源地址:https://blog.csdn.net/qq_64451048/article/details/127775623
--结束END--
本文标题: 【urllib的使用(上)】
本文链接: https://lsjlt.com/news/408403.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作



0