前言 过去半年,随着ChatGPT的火爆,直接带火了整个LLM这个方向,然LLM毕竟更多是基于过去的经验数据预训练而来,没法获取最新的知识,以及各企业私有的知识 为了获取最新的知识,ChatGPT plus版集成了bing搜索的功能,有的模
过去半年,随着ChatGPT的火爆,直接带火了整个LLM这个方向,然LLM毕竟更多是基于过去的经验数据预训练而来,没法获取最新的知识,以及各企业私有的知识
所以越来越多的人开始关注langchain并把它与LLM结合起来应用,更直接推动了数据库、知识图谱与LLM的结合应用
本文侧重讲解
阅读过程中若有任何问题,欢迎随时留言,会一一及时回复/解答,共同探讨、共同深挖
通俗讲,所谓langchain (官网地址、GitHub地址),即把AI中常用的很多功能都封装成库,且有调用各种商用模型api、开源模型的接口,支持以下各种组件

初次接触的朋友一看这么多组件可能直接晕了(封装的东西非常多,感觉它想把LLM所需要用到的功能/工具都封装起来),为方便理解,我们可以先从大的层面把整个langchain库划分为三个大层:基础层、能力层、应用层
Models:模型
各种类型的模型和模型集成,比如OpenAI的各个API/GPT-4等等,为各种不同基础模型提供统一接口
比如通过API完成一次问答
import osos.environ["OPENAI_API_KEY"] = '你的api key'from langchain.llms import OpenAIllm = OpenAI(model_name="text-davinci-003",max_tokens=1024)llm("怎么评价人工智能")得到的回答如下图所示

LLMS层
这一层主要强调对models层能力的封装以及服务化输出能力,主要有:
比如Google's PaLM Text APIs,再比如 llms/openai.py 文件下
model_token_mapping = { "gpt-4": 8192, "gpt-4-0314": 8192, "gpt-4-0613": 8192, "gpt-4-32k": 32768, "gpt-4-32k-0314": 32768, "gpt-4-32k-0613": 32768, "gpt-3.5-turbo": 4096, "gpt-3.5-turbo-0301": 4096, "gpt-3.5-turbo-0613": 4096, "gpt-3.5-turbo-16k": 16385, "gpt-3.5-turbo-16k-0613": 16385, "text-ada-001": 2049, "ada": 2049, "text-babbage-001": 2040, "babbage": 2049, "text-curie-001": 2049, "curie": 2049, "davinci": 2049, "text-davinci-003": 4097, "text-davinci-002": 4097, "code-davinci-002": 8001, "code-davinci-001": 8001, "code-cushman-002": 2048, "code-cushman-001": 2048, }Index(索引):Vector方案、KG方案
对用户私域文本、图片、pdf等各类文档进行存储和检索(相当于结构化文档,以便让外部数据和模型交互),具体实现上有两个方案:一个Vector方案、一个KG方案
对于Vector方案:即对文件先切分为Chunks,在按Chunks分别编码存储并检索,可参考此代码文件:langchain/libs/langchain/langchain/indexes /vectorstore.py
该代码文件依次实现
模块导入:导入了各种类型检查、数据结构、预定义类和函数
接下来,实现了一个函数_get_default_text_splitter,两个类VectorStoreIndexWrapper、VectorstoreIndexCreator
_get_default_text_splitter 函数:
这是一个私有函数,返回一个默认的文本分割器,它可以将文本递归地分割成大小为1000的块,且块与块之间有重叠
# 默认的文本分割器函数def _get_default_text_splitter() -> TextSplitter: return RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)接下来是,VectorStoreIndexWrapper 类:
这是一个包装类,主要是为了方便地访问和查询向量存储(Vector Store)
vectorstore: VectorStore # 向量存储对象 class Config: """Configuration for this pydantic object.""" extra = Extra.forbid # 额外配置项 arbitrary_types_allowed = True # 允许任意类型# 查询向量存储的函数def query( self, question: str, # 输入的问题字符串 llm: Optional[BaseLanguageModel] = None, # 可选的语言模型参数,默认为None retriever_kwargs: Optional[Dict[str, Any]] = None, # 提取器的可选参数,默认为None **kwargs: Any # 其他关键字参数) -> str: """Query the vectorstore."""# 函数的文档字符串,描述函数的功能 # 如果没有提供语言模型参数,则使用OpenAI作为默认语言模型,并设定温度参数为0 llm = llm or OpenAI(temperature=0) # 如果没有提供提取器的参数,则初始化为空字典 retriever_kwargs = retriever_kwargs or {} # 创建一个基于语言模型和向量存储提取器的检索QA链 chain = RetrievalQA.from_chain_type( llm, retriever=self.vectorstore.as_retriever(**retriever_kwargs), **kwargs ) # 使用创建的QA链运行提供的问题,并返回结果 return chain.run(question)提取器首先从大型语料库中检索与问题相关的文档或片段,然后生成器根据这些检索到的文档生成答案。
提取器可以基于许多不同的技术,包括:
a.基于关键字的检索:使用关键字匹配来查找相关文档
b.向量空间模型:将文档和查询都表示为向量,并通过计算它们之间的相似度来检索相关文档
c.基于深度学习的方法:使用预训练的神经网络模型(如BERT、RoBERTa等)将文档和查询编码为向量,并进行相似度计算
d.索引方法:例如倒排索引,这是搜索引擎常用的技术,可以快速找到包含特定词或短语的文档
这些方法可以独立使用,也可以结合使用,以提高检索的准确性和速度
# 查询向量存储并返回数据源的函数 def query_with_sources( self, question: str, llm: Optional[BaseLanguageModel] = None, retriever_kwargs: Optional[Dict[str, Any]] = None, **kwargs: Any ) -> dict: """Query the vectorstore and get back sources.""" llm = llm or OpenAI(temperature=0) # 默认使用OpenAI作为语言模型 retriever_kwargs = retriever_kwargs or {} # 提取器参数 chain = RetrievalQAWithSourcesChain.from_chain_type( llm, retriever=self.vectorstore.as_retriever(**retriever_kwargs), **kwargs ) return chain({chain.question_key: question})最后是VectorstoreIndexCreator 类:
这是一个创建向量存储索引的类
vectorstore_cls: Type[VectorStore] = Chroma # 默认使用Chroma作为向量存储类 embedding: Embeddings = Field(default_factory=OpenAIEmbeddings) # 默认使用OpenAIEmbeddings作为嵌入类 text_splitter: TextSplitter = Field(default_factory=_get_default_text_splitter) # 默认文本分割器 # 从加载器创建向量存储索引的函数 def from_loaders(self, loaders: List[BaseLoader]) -> VectorStoreIndexWrapper: """Create a vectorstore index from loaders.""" docs = [] for loader in loaders: # 遍历加载器 docs.extend(loader.load()) # 加载文档 return self.from_documents(docs) # 从文档创建向量存储索引的函数 def from_documents(self, documents: List[Document]) -> VectorStoreIndexWrapper: """Create a vectorstore index from documents.""" sub_docs = self.text_splitter.split_documents(documents) # 分割文档 vectorstore = self.vectorstore_cls.from_documents( sub_docs, self.embedding, **self.vectorstore_kwargs # 从文档创建向量存储 ) return VectorStoreIndexWrapper(vectorstore=vectorstore) # 返回向量存储的包装对象对于KG方案:这部分利用LLM抽取文件中的三元组,将其存储为KG供后续检索,可参考此代码文件:langchain/libs/langchain/langchain/indexes /graph.py
"""Graph Index Creator.""" # 定义"图索引创建器"的描述# 导入相关的模块和类型定义from typing import Optional, Type # 导入可选类型和类型的基础类型from langchain import BasePromptTemplate # 导入基础提示模板from langchain.chains.llm import LLMChain # 导入LLM链from langchain.graphs.networkx_graph import NetworkxEntityGraph, parse_triples # 导入Networkx实体图和解析三元组的功能from langchain.indexes.prompts.knowledge_triplet_extraction import ( # 从知识三元组提取模块导入对应的提示 KNOWLEDGE_TRIPLE_EXTRACTION_PROMPT,)from langchain.pydantic_v1 import BaseModel # 导入基础模型from langchain.schema.language_model import BaseLanguageModel # 导入基础语言模型的定义class GraphIndexCreator(BaseModel): # 定义图索引创建器类,继承自BaseModel """Functionality to create graph index.""" # 描述该类的功能为"创建图索引" llm: Optional[BaseLanguageModel] = None # 定义可选的语言模型属性,默认为None graph_type: Type[NetworkxEntityGraph] = NetworkxEntityGraph # 定义图的类型,默认为NetworkxEntityGraph def from_text( self, text: str, prompt: BasePromptTemplate = KNOWLEDGE_TRIPLE_EXTRACTION_PROMPT ) -> NetworkxEntityGraph: # 定义一个方法,从文本中创建图索引 """Create graph index from text.""" # 描述该方法的功能 if self.llm is None: # 如果语言模型为None,则抛出异常 raise ValueError("llm should not be None") graph = self.graph_type() # 创建一个新的图 chain = LLMChain(llm=self.llm, prompt=prompt) # 使用当前的语言模型和提示创建一个LLM链 output = chain.predict(text=text) # 使用LLM链对文本进行预测 knowledge = parse_triples(output) # 解析预测输出得到的三元组 for triple in knowledge: # 遍历所有的三元组 graph.add_triple(triple) # 将三元组添加到图中 return graph # 返回创建的图 async def afrom_text( # 定义一个异步版本的from_text方法 self, text: str, prompt: BasePromptTemplate = KNOWLEDGE_TRIPLE_EXTRACTION_PROMPT ) -> NetworkxEntityGraph: """Create graph index from text asynchronously.""" # 描述该异步方法的功能 if self.llm is None: # 如果语言模型为None,则抛出异常 raise ValueError("llm should not be None") graph = self.graph_type() # 创建一个新的图 chain = LLMChain(llm=self.llm, prompt=prompt) # 使用当前的语言模型和提示创建一个LLM链 output = await chain.apredict(text=text) # 异步使用LLM链对文本进行预测 knowledge = parse_triples(output) # 解析预测输出得到的三元组 for triple in knowledge: # 遍历所有的三元组 graph.add_triple(triple) # 将三元组添加到图中 return graph # 返回创建的图另外,为了索引,便不得不牵涉以下这些能力
如果基础层提供了最核心的能力,能力层则给这些能力安装上手、脚、脑,让其具有记忆和触发万物的能力,包括:Chains、Memory、Tool三部分
entities = get_entities(entity_string) # 获取实体列表。 context = "" # 初始化上下文。 all_triplets = [] # 初始化三元组列表。 for entity in entities: # 遍历每个实体 all_triplets.extend(self.graph.get_entity_knowledge(entity)) # 获取实体的所有知识并加入到三元组列表中。 context = "\n".join(all_triplets) # 用换行符连接所有的三元组作为上下文。 # 打印完整的上下文。 _run_manager.on_text("Full Context:", end="\n", verbose=self.verbose) _run_manager.on_text(context, color="green", end="\n", verbose=self.verbose) # 使用上下文和问题获取答案。 result = self.qa_chain( {"question": question, "context": context}, callbacks=_run_manager.get_child(), ) return {self.output_key: result[self.qa_chain.output_key]} # 返回答案# 定义基于向量数据库的问题回答类class VectorDBQAWithSourcesChain(BaseQAWithSourcesChain): """Question-answering with sources over a vector database.""" # 定义向量数据库的字段 vectorstore: VectorStore = Field(exclude=True) """Vector Database to connect to.""" # 定义返回结果的数量 k: int = 4 # 是否基于令牌限制来减少返回结果的数量 reduce_k_below_max_tokens: bool = False # 定义返回的文档基于令牌的最大限制 max_tokens_limit: int = 3375 # 定义额外的搜索参数 search_kwargs: Dict[str, Any] = Field(default_factory=dict) # 定义函数来根据最大令牌限制来减少文档 def _reduce_tokens_below_limit(self, docs: List[Document]) -> List[Document]: num_docs = len(docs) # 检查是否需要根据令牌减少文档数量 if self.reduce_k_below_max_tokens and isinstance( self.combine_documents_chain, StuffDocumentsChain ): tokens = [ self.combine_documents_chain.llm_chain.llm.get_num_tokens( doc.page_content ) for doc in docs ] token_count = sum(tokens[:num_docs]) # 减少文档数量直到满足令牌限制 while token_count > self.max_tokens_limit: num_docs -= 1 token_count -= tokens[num_docs] return docs[:num_docs] # 获取相关文档的函数 def _get_docs( self, inputs: Dict[str, Any], *, run_manager: CallbackManagerForChainRun ) -> List[Document]: question = inputs[self.question_key] # 从向量存储中搜索相似的文档 docs = self.vectorstore.similarity_search( question, k=self.k, **self.search_kwargs ) return self._reduce_tokens_below_limit(docs) 对Chains的执行过程中的输入、输出进行记忆并结构化存储,为下一步的交互提供上下文,这部分简单存储在Redis即可 根据交互历史构建知识图谱,根据关联信息给出准确结果,对应的代码文件为:memory/kg.py
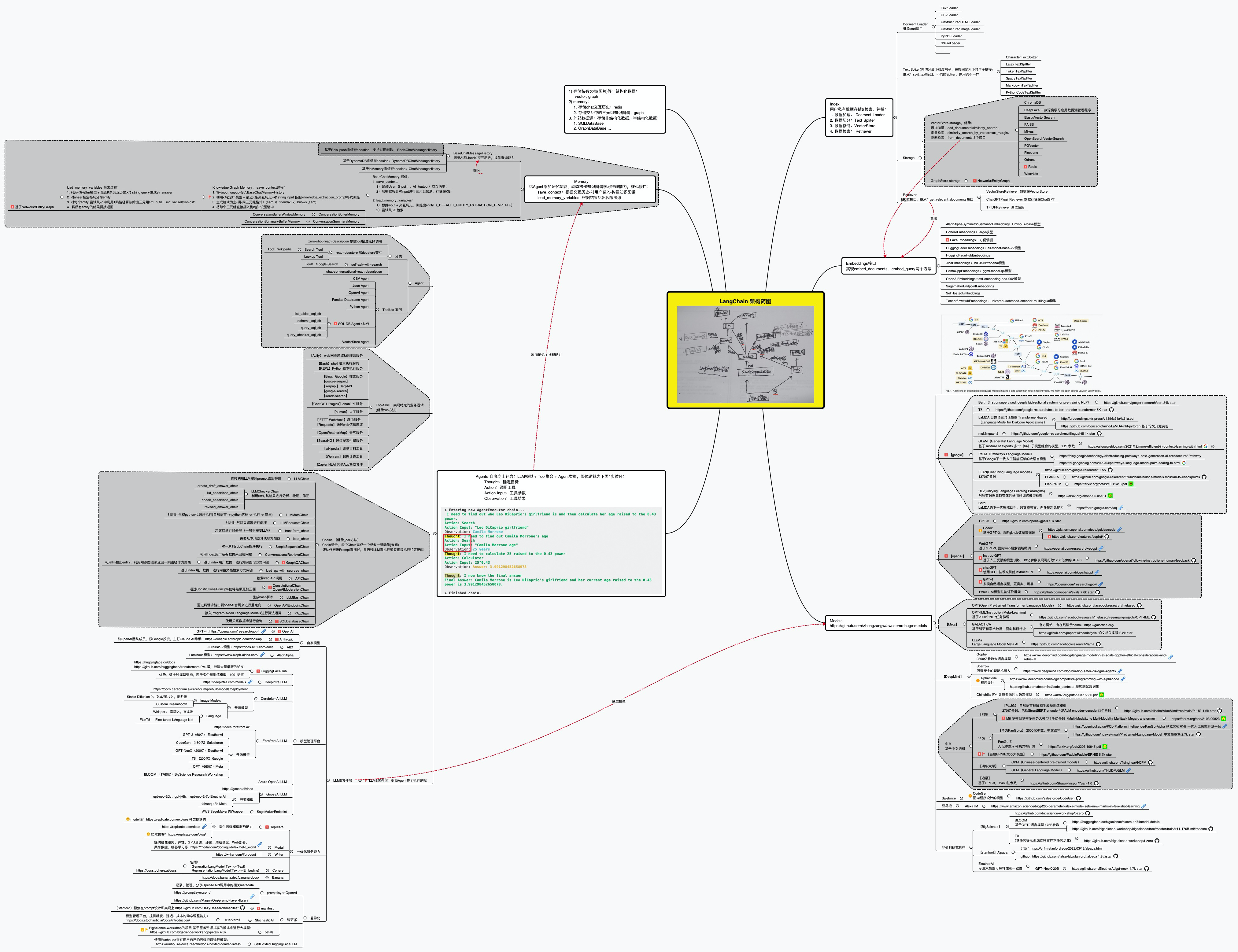
对Chains的执行过程中的输入、输出进行记忆并结构化存储,为下一步的交互提供上下文,这部分简单存储在Redis即可 根据交互历史构建知识图谱,根据关联信息给出准确结果,对应的代码文件为:memory/kg.py# pip install wikipediafrom langchain.agents import load_toolsfrom langchain.agents import initialize_agentfrom langchain.agents import AgentTypetools = load_tools(["wikipedia", "llm-math"], llm=llm)agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_React_DESCRIPTION, verbose=True)agent.run("奥巴马的生日是哪天? 到2023年他多少岁了?")最终langchain的整体技术架构可以如下图所示 (查看高清大图,此外,这里还有另一个架构图)

但看理论介绍,你可能没法理解langchain到底有什么用,为方便大家理解,特举几个langchain的应用示例
由于需要借助 Serpapi 来进行实现,而Serpapi 提供了 Google 搜索的API 接口
故先到 Serpapi 官网(https://serpapi.com/)上注册一个用户,并复制他给我们生成 API key,然后设置到环境变量里面去
import osos.environ["OPENAI_API_KEY"] = '你的api key'os.environ["SERPAPI_API_KEY"] = '你的api key'然后,开始编写代码
from langchain.agents import load_toolsfrom langchain.agents import initialize_agentfrom langchain.llms import OpenAIfrom langchain.agents import AgentType# 加载 OpenAI 模型llm = OpenAI(temperature=0,max_tokens=2048) # 加载 serpapi 工具tools = load_tools(["serpapi"])# 如果搜索完想再计算一下可以这么写# tools = load_tools(['serpapi', 'llm-math'], llm=llm)# 如果搜索完想再让他再用python的print做点简单的计算,可以这样写# tools=load_tools(["serpapi","Python_repl"])# 工具加载后都需要初始化,verbose 参数为 True,会打印全部的执行详情agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)# 运行 agentagent.run("What's the date today? What great events have taken place today in history?")众所周知,由于ChatGPT训练的数据只更新到 2021 年,因此它不知道互联网最新的知识(除非它调用搜索功能bing),而利用 “LangChain + ChatGPT的API” 则可以用不到 50 行的代码然后实现一个和既存文档的对话机器人
假设所有 2022 年更新的内容都存在于 2022.txt 这个文档中,那么通过如下的代码,就可以让 ChatGPT 来支持回答 2022 年的问题
其中原理也很简单:
#!/usr/bin/python# -*- coding: UTF-8 -*-import os# 导入os模块,用于操作系统相关的操作import jieba as jb # 导入结巴分词库from langchain.chains import ConversationalRetrievalChain # 导入用于创建对话检索链的类from langchain.chat_models import ChatOpenAI # 导入用于创建ChatOpenAI对象的类from langchain.document_loaders import DirectoryLoader # 导入用于加载文件的类from langchain.embeddings import OpenAIEmbeddings # 导入用于创建词向量嵌入的类from langchain.text_splitter import TokenTextSplitter # 导入用于分割文档的类from langchain.vectorstores import Chroma # 导入用于创建向量数据库的类# 初始化函数,用于处理输入的文档def init(): files = ['2022.txt'] # 需要处理的文件列表 for file in files: # 遍历每个文件 with open(f"./data/{file}", 'r', encoding='utf-8') as f: # 以读模式打开文件 data = f.read() # 读取文件内容 cut_data = " ".join([w for w in list(jb.cut(data))]) # 对读取的文件内容进行分词处理 cut_file = f"./data/cut/cut_{file}" # 定义处理后的文件路径和名称 with open(cut_file, 'w') as f: # 以写模式打开文件 f.write(cut_data) # 将处理后的内容写入文件# 新建一个函数用于加载文档def load_documents(directory): # 创建DirectoryLoader对象,用于加载指定文件夹内的所有.txt文件 loader = DirectoryLoader(directory, glob='***.txt", loader_cls=TextLoader)#读取文本文件documents = loader.load()# 使用text_splitter对文档进行分割split_text = text_splitter.split_documents(documents)try:for document in tqdm(split_text):# 获取向量并储存到pineconePinecone.from_documents([document], embeddings, index_name=pinecone_index)except Exception as e: print(f"Error: {e}") quit()两个文件,一个__init__.py (就一行代码:from .MyFAISS import MyFAISS),另一个MyFAISS.py,如下代码所示
# 从langchain.vectorstores库导入FAISSfrom langchain.vectorstores import FAISS# 从langchain.vectorstores.base库导入VectorStore from langchain.vectorstores.base import VectorStore# 从langchain.vectorstores.faiss库导入dependable_faiss_importfrom langchain.vectorstores.faiss import dependable_faiss_import from typing import Any, Callable, List, Dict # 导入类型检查库from langchain.docstore.base import Docstore # 从langchain.docstore.base库导入Docstore# 从langchain.docstore.document库导入Documentfrom langchain.docstore.document import Document import numpy as np # 导入numpy库,用于科学计算import copy # 导入copy库,用于数据复制import os # 导入os库,用于操作系统相关的操作from configs.model_config import * # 从configs.model_config库导入所有内容# 定义MyFAISS类,继承自FAISS和VectorStore两个父类class MyFAISS(FAISS, VectorStore):接下来,逐一实现以下函数
# 定义类的初始化函数 def __init__( self, embedding_function: Callable, index: Any, docstore: Docstore, index_to_docstore_id: Dict[int, str], normalize_L2: bool = False, ): # 调用父类FAISS的初始化函数 super().__init__(embedding_function=embedding_function, index=index, docstore=docstore, index_to_docstore_id=index_to_docstore_id, normalize_L2=normalize_L2) # 初始化分数阈值 self.score_threshold=VECTOR_SEARCH_SCORE_THRESHOLD # 初始化块大小 self.chunk_size = CHUNK_SIZE # 初始化块内容 self.chunk_conent = False # 定义函数seperate_list,将一个列表分解成多个子列表,每个子列表中的元素在原列表中是连续的 def seperate_list(self, ls: List[int]) -> List[List[int]]: # TODO: 增加是否属于同一文档的判断 lists = [] ls1 = [ls[0]] for i in range(1, len(ls)): if ls[i - 1] + 1 == ls[i]: ls1.append(ls[i]) else: lists.append(ls1) ls1 = [ls[i]] lists.append(ls1) return listssimilarity_search_with_score_by_vector 函数用于通过向量进行相似度搜索,返回与给定嵌入向量最相似的文本和对应的分数
# 定义函数similarity_search_with_score_by_vector,根据输入的向量,查找最接近的k个文本 def similarity_search_with_score_by_vector( self, embedding: List[float], k: int = 4 ) -> List[Document]: # 调用dependable_faiss_import函数,导入faiss库 faiss = dependable_faiss_import() # 将输入的列表转换为numpy数组,并设置数据类型为float32 vector = np.array([embedding], dtype=np.float32) # 如果需要进行L2归一化,则调用faiss.normalize_L2函数进行归一化 if self._normalize_L2: faiss.normalize_L2(vector) # 调用faiss库的search函数,查找与输入向量最接近的k个向量,并返回他们的分数和索引 scores, indices = self.index.search(vector, k) # 初始化一个空列表,用于存储找到的文本 docs = [] # 初始化一个空集合,用于存储文本的id id_set = set() # 获取文本库中文本的数量 store_len = len(self.index_to_docstore_id) # 初始化一个布尔变量,表示是否需要重新排列id列表 rearrange_id_list = False # 遍历找到的索引和分数 for j, i in enumerate(indices[0]): # 如果索引为-1,或者分数小于阈值,则跳过这个索引 if i == -1 or 0 < self.score_threshold < scores[0][j]: # This happens when not enough docs are returned. continue # 如果索引存在于index_to_docstore_id字典中,则获取对应的文本id if i in self.index_to_docstore_id: _id = self.index_to_docstore_id[i] # 如果索引不存在于index_to_docstore_id字典中,则跳过这个索引 else: continue # 从文本库中搜索对应id的文本 doc = self.docstore.search(_id) # 如果不需要拆分块内容,或者文档的元数据中没有context_expand字段,或者context_expand字段的值为false,则执行以下代码 if (not self.chunk_conent) or ("context_expand" in doc.metadata and not doc.metadata["context_expand"]): # 匹配出的文本如果不需要扩展上下文则执行如下代码 # 如果搜索到的文本不是Document类型,则抛出异常 if not isinstance(doc, Document): raise ValueError(f"Could not find document for id {_id}, got {doc}") # 在文本的元数据中添加score字段,其值为找到的分数 doc.metadata["score"] = int(scores[0][j]) # 将文本添加到docs列表中 docs.append(doc) continue # 将文本id添加到id_set集合中 id_set.add(i) # 获取文本的长度 docs_len = len(doc.page_content) # 遍历范围在1到i和store_len - i之间的数字k for k in range(1, max(i, store_len - i)): # 初始化一个布尔变量,表示是否需要跳出循环 break_flag = False # 如果文本的元数据中有context_expand_method字段,并且其值为"forward",则扩展范围设置为[i + k] if "context_expand_method" in doc.metadata and doc.metadata["context_expand_method"] == "forward": expand_range = [i + k] # 如果文本的元数据中有context_expand_method字段,并且其值为"backward",则扩展范围设置为[i - k] elif "context_expand_method" in doc.metadata and doc.metadata["context_expand_method"] == "backward": expand_range = [i - k] # 如果文本的元数据中没有context_expand_method字段,或者context_expand_method字段的值不是"forward"也不是"backward",则扩展范围设置为[i + k, i - k] else: expand_range = [i + k, i - k] # 遍历扩展范围 for l in expand_range: # 如果l不在id_set集合中,并且l在0到len(self.index_to_docstore_id)之间,则执行以下代码 if l not in id_set and 0 <= l < len(self.index_to_docstore_id): # 获取l对应的文本id _id0 = self.index_to_docstore_id[l] # 从文本库中搜索对应id的文本 doc0 = self.docstore.search(_id0) # 如果文本长度加上新文档的长度大于块大小,或者新文本的源不等于当前文本的源,则设置break_flag为true,跳出循环 if docs_len + len(doc0.page_content) > self.chunk_size or doc0.metadata["source"] != \ doc.metadata["source"]:break_flag = Truebreak # 如果新文本的源等于当前文本的源,则将新文本的长度添加到文本长度上,将l添加到id_set集合中,设置rearrange_id_list为true elif doc0.metadata["source"] == doc.metadata["source"]:docs_len += len(doc0.page_content)id_set.add(l)rearrange_id_list = True # 如果break_flag为true,则跳出循环 if break_flag: break # 如果不需要拆分块内容,或者不需要重新排列id列表,则返回docs列表 if (not self.chunk_conent) or (not rearrange_id_list): return docs # 如果id_set集合的长度为0,并且分数阈值大于0,则返回空列表 if len(id_set) == 0 and self.score_threshold > 0: return [] # 对id_set集合中的元素进行排序,并转换为列表 id_list = sorted(list(id_set)) # 调用seperate_list函数,将id_list分解成多个子列表 id_lists = self.seperate_list(id_list) # 遍历id_lists中的每一个id序列 for id_seq in id_lists: # 遍历id序列中的每一个id for id in id_seq: # 如果id等于id序列的第一个元素,则从文档库中搜索对应id的文本,并深度拷贝这个文本 if id == id_seq[0]: _id = self.index_to_docstore_id[id] # doc = self.docstore.search(_id) doc = copy.deepcopy(self.docstore.search(_id)) # 如果id不等于id序列的第一个元素,则从文本库中搜索对应id的文档,将新文本的内容添加到当前文本的内容后面 else: _id0 = self.index_to_docstore_id[id] doc0 = self.docstore.search(_id0) doc.page_content += " " + doc0.page_content # 如果搜索到的文本不是Document类型,则抛出异常 if not isinstance(doc, Document): raise ValueError(f"Could not find document for id {_id}, got {doc}") # 计算文本的分数,分数等于id序列中的每一个id在分数列表中对应的分数的最小值 doc_score = min([scores[0][id] for id in [indices[0].tolist().index(i) for i in id_seq if i in indices[0]]]) # 在文本的元数据中添加score字段,其值为文档的分数 doc.metadata["score"] = int(doc_score) # 将文本添加到docs列表中 docs.append(doc) # 返回docs列表 return docs #定义了一个名为 delete_doc 的方法,这个方法用于删除文本库中指定来源的文本 def delete_doc(self, source: str or List[str]): # 使用 try-except 结构捕获可能出现的异常 try: # 如果 source 是字符串类型 if isinstance(source, str): # 找出文本库中所有来源等于 source 的文本的id ids = [k for k, v in self.docstore._dict.items() if v.metadata["source"] == source] # 获取向量存储的路径 vs_path = os.path.join(os.path.split(os.path.split(source)[0])[0], "vector_store") # 如果 source 是列表类型 else: # 找出文本库中所有来源在 source 列表中的文本的id ids = [k for k, v in self.docstore._dict.items() if v.metadata["source"] in source] # 获取向量存储的路径 vs_path = os.path.join(os.path.split(os.path.split(source[0])[0])[0], "vector_store") # 如果没有找到要删除的文本,返回失败信息 if len(ids) == 0: return f"docs delete fail" # 如果找到了要删除的文本 else: # 遍历所有要删除的文本id for id in ids: # 获取该id在索引中的位置 index = list(self.index_to_docstore_id.keys())[list(self.index_to_docstore_id.values()).index(id)] # 从索引中删除该id self.index_to_docstore_id.pop(index) # 从文本库中删除该id对应的文本 self.docstore._dict.pop(id) # TODO: 从 self.index 中删除对应id,这是一个未完成的任务 # self.index.reset() # 保存当前状态到本地 self.save_local(vs_path) # 返回删除成功的信息 return f"docs delete success" # 捕获异常 except Exception as e: # 打印异常信息 print(e) # 返回删除失败的信息 return f"docs delete fail" # 定义了一个名为 update_doc 的方法,这个方法用于更新文档库中的文档 def update_doc(self, source, new_docs): # 使用 try-except 结构捕获可能出现的异常 try: # 删除旧的文档 delete_len = self.delete_doc(source) # 添加新的文档 ls = self.add_documents(new_docs) # 返回更新成功的信息 return f"docs update success" # 捕获异常 except Exception as e: # 打印异常信息 print(e) # 返回更新失败的信息 return f"docs update fail" # 定义了一个名为 list_docs 的方法,这个方法用于列出文档库中所有文档的来源 def list_docs(self): # 遍历文档库中的所有文档,取出每个文档的来源,转换为集合,再转换为列表,最后返回这个列表 return list(set(v.metadata["source"] for v in self.docstore._dict.values()))通过本文之前或本博客内之前的内容可知,由于大部分LLM都是基于过去互联网旧的预训练语料训练、推理而来,由此会引发两大问题
面对第二个问题,我们在上文已经展示了可以通过与langchain结合搭建本地知识库的办法解决,此外,还可以考虑让LLM与知识图谱结合
根据所存储信息的不同,现有的知识图谱可分为四大类:百科知识型知识图谱、常识型知识图谱、特定领域型知识图谱、多模态知识图谱

而下图总结了 LLM 和知识图谱各自的优缺点

而实际上,LLM与知识图谱可以互相促进、增强彼此
总之,在 LLM 与知识图谱协同的相关研究中,研究者将 LLM 和知识图谱的优点融合,让它们在知识表征和推理方面的能力得以互相促进
今年6月份,一篇论文《Unifying Large Language Models and Knowledge Graphs: A Roadmap》指出,用知识图谱增强 LLM具体的方式有几种
下表总结了用知识图谱增强 LLM 的典型方法

现有的 LLM 主要依靠在大规模语料库上执行自监督训练。尽管这些模型在下游任务上表现卓越,它们却缺少与现实世界相关的实际知识。在将知识图谱整合进 LLM 方面,之前的研究可以分为三类:



上文的方法可以有效地将知识与LLM中的文本表示进行融合。但是,真实世界的知识会变化,这些方法的局限是它们不允许更新已整合的知识,除非对模型重新训练。因此在推理时,它们可能无法很好地泛化用于未见过的知识(比如ChatGPT的预训练数据便截止到的2021年9月份,为解决这个知识更新的问题,它曾借助接入外部插件bing搜索去解决)
所以,相当多的研究致力于保持知识空间和文本空间的分离,并在推理时注入知识。这些方法主要关注的是问答QA任务,因为问答既需要模型捕获文本语义,还需要捕获最新的现实世界知识,比如


更多细节在我司的langchain实战课程上见
// 待更..
// 待更..
// 待更..
KnowLM是一个结合LLM能力的知识抽取项目,其基于llama 13b利用自己的数据+公开数据对模型做了pretrain,然后在pretrain model之上用指令语料做了lora微调,最终可以达到的效果如下图所示 (图源),当面对同一个输入input时,在分别给定4种不同指令任务instruction时,KnowLM可以分别得到对应的输出output

下图展示了训练的整个流程和数据集构造。整个训练过程分为两个阶段:

中文语料来自于百度百科、悟道和中文维基百科 英文数据集是从LLaMA原始的英文语料中进行采样,不同的是维基数据,原始论文中的英文维基数据的最新时间点是2022年8月,他们额外爬取了2022年9月到2023年2月,总共六个月的数据 而代码数据集,由于Pile数据集中的代码质量不高,他们去爬取了GitHub、LeetCode的代码数据,一部分用于预训练,另外一部分用于指令微调1024,而大多数的文档的长度都远远大于这个长度,因此需要对这些文档进行划分。设计了一个贪心算法来对文档进行切分,贪心的目标是在保证每个样本都是完整的句子、分割的段数尽可能少的前提下,尽可能保证每个样本的长度尽可能长mmap的方法对数据进行处理和加载,即将索引读入内存,需要的时候根据索引去硬盘查找| 参数 | 值 |
|---|---|
| micro batch size(单张卡的batch size大小) | 20 |
| gradient accumulation(梯度累积) | 3 |
| global batch size(一个step的、全局的batch size) | 20*3*24=1440 |
| 一个step耗时 | 260s |
NER、RE、EE)。需要注意的是,由于许多开源的数据集,比如alpaca数据集 CoT数据集 代码数据集都是英文的,因此为了获得对应的中文数据集,对这些英文数据集使用GPT4进行翻译CoT数据集 代码数据集使用第一种情况CoNLL ACE CASIS等开源的IE数据集,构造相应的英文指令数据集。中文部分,不仅使用了开源的数据集如DuEE、PEOPLE DAILY、DuIE等,还采用了他们自己构造的KG2Instruction,构造相应的中文指令数据集| 数据集类型 | 条数 |
|---|---|
| COT(中英文) | 202,333 |
| 通用数据集(中英文) | 105,216 |
| 代码数据集(中英文) | 44,688 |
| 英文指令抽取数据集 | 537,429 |
| 中文指令抽取数据集 | 486,768 |

附录
另外,这是:关于LLM与知识图谱的一席论文列表
https://github.com/csunny/DB-GPT
DB-GPT基于 FastChat 构建大模型运行环境,并提供 vicuna 作为基础的大语言模型。此外,通过LangChain提供私域知识库问答能力,且有统一的数据向量化存储与索引:提供一种统一的方式来存储和索引各种数据类型,同时支持插件模式,在设计上原生支持Auto-GPT插件,具备以下功能或能力
整个DB-GPT的架构,如下图所示(图源)

通过QLoRA(4-bit级别的量化+LoRA)的方法,用3090在DB-GPT上打造基于33B LLM的个人知识库
// 待更
更多课上见:七月LLM与langchain/知识图谱/数据库的实战 [解决问题、实用为王]
本文经历了三个阶段
来源地址:https://blog.csdn.net/v_JULY_v/article/details/131552592
--结束END--
本文标题: 从LangChain+LLM的本地知识库问答到LLM与知识图谱、数据库的结合
本文链接: https://lsjlt.com/news/406433.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

{kind=link}
{kind=link}
0