Python 官方文档:入门教程 => 点击学习
本文目录 一、引言 二、成果演示——口述式数据可视化 三、远原理述 四、实现过程 (一)环境配置 (二)申请Openai账号 (一)调用ChatGPT api (二)设计AI身份,全自动处理数据

一、引言
二、成果演示——口述式数据可视化
三、远原理述
四、实现过程
(一)环境配置
(二)申请Openai账号
(一)调用ChatGPT api
(二)设计AI身份,全自动处理数据
五、再谈此次探索
六、总结
OpenAI 公司开发的 ChatGPT 已经火了一年多了,这期间各种 AI 产品以及创意层出不穷,问答的、画画的、写论文的……总之啥都有。很多程序员在日常工作中也会使用 ChatGPT 来编写代码解决问题,笔者也是其中之一,在使用过程中,笔者逐渐萌生出一些奇妙的想法。
AI 虽然强大,但种种原因限制了它与计算机文件的交互,所以在数据处理中,AI 只能是一个“军师”角色,有谋却无勇,不能直接帮我们处理数据。既然如此,我们能不能使用 python 对 ChatGPT 做一个“浅加工”,调用 OpenAI 提供的 API,再辅以艺术性提问,让AI 根据我们的指令直接处理电脑中的数据,或者做一些数据可视化的工作呢?一番探索后,笔者得到了振奋人心的成果,接下来就把成果、原理和过程分享给大家。
本文中所有 Python 代码均在集成开发环境 Visual Studio Code (vscode) 中使用交互式开发环境 Jupyter Notebook 中编写。
首先,我在 Jupyter Notebook 中开发出我的 AI 程序,随后我将一个 excel 数据表存放到与程序同一级的文件夹中。放进来的 Excel 表名为“中国历年数字经济核心产业大类被授权实用新型专利申请数.xlsx”,使用 WPS 打开后如下图所示。

接下来我先后给出以下几条指令。
第一条指令:使用 pandas 读取当前目录下名为“中国历年数字经济核心产业大类被授权实用新型专利申请数.xlsx”的文件,变量命名为 data。ChatGPT 收到指令后就照做了,这一步还没有得到什么成果。
第二条指令:使用变量 data 中的数据,以“申请年份”为横轴,分别以“01数字产品制造业被授权实用新型专利数”、 “02数字产品服务业被授权实用新型专利数”、 “03数字技术应用业被授权实用新型专利数”和“04数字要素驱动业被授权实用新型专利数”为纵轴,绘制四条折线图。于是 ChatGPT 按照指令,给出了下面这个折线图以及绘制者个折线图用到的 Python 代码。

第三条指令:将四个图例分别修改成“数字产品制造业”、“数字产品服务业”、“数字产品应用业”和“数字要素驱动业”。ChatGPT 照做,并直接给出了改进后的成果。

第四条指令:在折线图右边添加一个纵轴,内容是data中的“被授权实用新型专利数”字段,横轴不变,在折线图中添加一幅柱状图。最后 ChatGPT 依然不动声色地完成任务并给出结果。

从以上成果来看,我们的 “进化版” ChatGPT 已经能够根据我们的命令完成数据处理任务。最重要的是,AI 给出的不是建议或者代码,而是处理的结果。如果仅仅使用 ChatGPT,目前来说这一定是不可能做到的,但它和 Python 结合起来却让人感到惊喜。
这个看上去很了不起的程序,背后原理却算不上复杂,相当于是给霍金先生换上了一副像施瓦辛格那样健硕的躯体(打趣一下,绝对无意冒犯)。
如果 ChatGPT 是那个聪明绝顶的脑袋,那么 Python 就是那副强大的躯体。AI 虽然强大,但是没有直接操作我们计算机本地文件的权限;Python 语言也很强大,但没办法根据文字指令为我们解决个性化的问题。于是我们就使用 Python 去调用 OpenAI 提供的 ChatGPT API 接口,再由我们去提出实际的需求,ChatGPT 返回处理的 Python 代码之后,我们想办法让 Python 自动地在本地计算机中去运行 ChatGPT 给出的代码,由于代码是在我们自己的电脑中运行的,结果自然也可以得到保留。也就是说实际的处理工作都是 Python 去完成的,ChatGPT 自始至终都没有接触到我们的数据,因此并不存在数据安全问题,这一点超级重要!
一套操作之后就有了文章开头那样的成果。不过原理说起来简单,真正实现的过程中,也遇到了不少问题,下面是其中几个关键点:
ChatGPT 的答案中一般同时含有描述性文字和代码,如何精准运行代码而忽略描述性文字?
ChatGPT 返回的结果是字符串,怎么把字符串直接当做代码运行呢,运行后又如何保留代码中的变量?
如何实现连续对话?
以上问题的答案,都可以在下文中找到。
先在我们的电脑中安装好 Python 环境以及开发环境,然后在终端中使用以下命令安装调用 ChatGPT 的第三方库。
pip install openai与 OpenAI API 进行交互之前,我们需要有与其进行通信时的身份验证凭证,以确保我们的请求被正确处理。这就需要你在 OpenAI 的网站上创建一个帐号,并在账户设置中生成一个 API 密钥(网上教程很多,可以参考)。
在免费可直接调用的 ChatGPT 模型中,gpt-3.5-turbo是最优选择,接下来我们就调用这个模型来解决问题。在调用之前,我们先导入相关第三方库并配置好参数。
# 导入 OpenAI 库import openai# 配置申请好的 API 秘钥,新注册账户都会一定数量的免费额度openai.api_key = '***********************'指定 API 密钥并确定想要调用的模型后,就可以通过函数openai.ChatCompletion.create()来创建 Chat 并获取模型的响应了。在使用之前,我们先了解一下该函数的两个必需参数:model和messages。
| 参数 | 用法 |
|---|---|
| model | 用于指定使用的模型,可以根据函数openai.Model.list()获取的所有可用模型列表自行选择 |
| messages | 指定历史聊天中涵盖的信息,以列表传递。列表中的元素为字典,每个字典中包含role 和content两个键。role代表历史消息中发送消息者扮演的身份,可以选择 "system"、"user" 或者 "assistant",其中 "system" 用于向模型提供一般的指导或提示,"user" 表示用户的输入,"assistant" 表示模型的回复;content代表身份对应的具体信息内容。 |
messages中的内容可以理解为定义上文语境,一般以 "system" 的身份开启对话,"user" 身份代表用户向模型传递信息,"assistant" 身份代表模型对用户提问的回答。
下面我们使用函数openai.ChatCompletion.create()举一个简单的调用此 API 的例子,代码如下:
response = openai.ChatCompletion.create( model = "gpt-3.5-turbo", messages = [ {"role": "system", "content": "你是一个得力的助手。"}, {"role": "user", "content": "你好!"}, {"role": "assistant", "content": "你好,有什么可以帮到你?"}, {"role": "user", "content": "帮我制定一份有关放假时间的通知。"} # 提出问题 ])response上面的例子中,我们调用了 OpenAI 的gpt-3.5-turbo模型,参数messages中第一行提示了模型助手的身份;第二行是用户传递给模型的消息,内容为“你好!”;第三行是模型的回复信息,内容为“你好,有什么可以帮到你?”;第四行为用户继续传递给模型的消息,内容为“帮我制定一份有关放假时间的通知。”
随后模型将返回响应信息,并将响应结果储存在变量response中,响应结果的内容如下:
JSON: { "id": "chatcmpl-7jMo2oVD9xw1uGZ7QPDm0JTPQSDdy", "object": "chat.completion", "created": 1691046782, "model": "gpt-3.5-turbo-0613", "choices": [ { "index": 0, "message": { "role": "assistant", # 篇幅原因此处省略,下文介绍 "content": "\u5f53\u7136\u53ef\u4ee5…………\u544a\u8bc9\u6211\u3002" }, "finish_reason": "stop" } ], "usage": { "prompt_tokens": 62, "completion_tokens": 470, "total_tokens": 532 }} 我们来看一下返回结果中包含的重要内容:
id:请求 ID。
object:返回对象的类型。
created:请求时间。
model:产生响应使用的模型全称。
choices:completion 对象列表,默认只有一个回答,或者使用参数 n 来规定回答数量。其中:
index:choices 列表中 completion 对象的索引
message:模型给出的响应信息,同时包括 role 和 content
finish_reason:模型停止生成文本的原因,包括 "stop" 和 "length"
usage:查看消耗的 token。其中:
prompt_tokens:用户传递信息所消耗的 token
completion_tokens:生成模型的响应文本消耗的 token
total_tokens:一共消耗的 token
在上面的代码中可以看到,返回的响应信息中的模型给出的回答是 Unicode 的形式,当我们需要查看输出的结果时,可以使用如下方式:

在这个例子中我们只使用了函数openai.ChatCompletion.create()的两个必要参数,除此之外,该函数还有许多其他的可选参数,我们可以根据自己的要求来调节这些参数,从而规定 ChatGPT 给出的答案范围,下面列举四个可选参数:
| 参数 | 作用 |
|---|---|
| temperature | 取值介于 0 到 2,默认为 1;用于控制输出结果的随机性,temperature 取值越大,随机性越高。 |
| top_p | 默认为 1,用于控制生成的候选词的数量,以提高回复的多样性。是 temperature 的替代方法,top_p 取值越小,多样性越大。 |
| n | choices 中 completion 对象的数量,默认为 1。 |
| max_tokens | 默认为 inf,用于控制模型生产 completion 的最大 token。 |
需要注意一点,参数 temperature 和 top_p 不要同时修改,更改其中一个即可。
前面说到,我们要运行 ChatGPT 返回的代码,但是又要从它的回答中找出可运行的代码,剔除其他提示/解释性文字。这样做难度太高了,主要是不确定性太高,毕竟 ChatGPT 的回答不可预测。所以在调用 ChatGPT 的时候,我们就应该明确给出指示,让 ChatGPT 只返回可运行的 Python 代码,以及其他注意事项,这个指示可以根据上一步中提到的 “system” 角色来提出。这样一来,前面提出的第一个问题就解决了。
根据上一步的描述,可以获取 ChatGPT 的回答,但是这个回答是一个字符串,而我们的目的是使用我们自己电脑上的 Python 去运行给出的代码,Python 中的内置函数 exec() 恰好具备这个能力!也就是说代码运行的问题得以解决。
# exec() 使用示范exec('print(1+1)') # 2虽然代码可以运行了,但是代码运行后又迎来了新的问题,由于代码是使用 exec() 函数运行的,运行后代码中的变量全部无法直接访问。实际上,当函数 exec() 在指定命名空间中运行字符串类型的代码时,运行过程中的中间变量就可以保留在空间中,运行后我们再从命名空间中取出需要的变量即可。这样第二个问题也得到了解决。
最后,连续对话的问题就比较容易了,我们将上一步 ChatGPT 返回的回答添加到与 ChatGPT 的对话记录中即可。具体实现方法可以查看上一步(通过参数 message 实现)。在添加一些其他小功能后,得到了最终的程序。
import openai# 指定 OpenAI API 的密钥openai.api_key = '***********************'# 规定 ChatGPT 的身份以及给出答案的范围Describe = "你的身份是一个精通Python,能使用pandas等工具进行数据处理的专家,可以帮我解决问题,\ 你将会根据我描述的情景和问题给出相应的数据处理代码,并且给出的答案中仅包含代码,\ 不需要额外的解释说明。你的代码不需要使用markdown格式输出,只要把代码以字符串的\ 形式给出即可。注意你给出答案的连续性,如果你之前给出的代码中包含import语句,\ 那么不需要重复给出相同的import语句。"# 定义和储存历史消息BaseMessage = [{"role":"system", "content":Describe}]# 定义变量 result,用于储存 ChatGPT 返回的代码result = ''# 定义命名空间,用于储存结果Space = {}# 定义调用 ChatGPT 的函数def Chat_Code(Order, Model="gpt-3.5-turbo"): ''' Order:告诉 ChatGPT 如何处理数据的命令 Model:使用的语言模型,默认使用 gpt-3.5-turbo ''' global Space global BaseMessage global result # 以 "user" 的身份向 ChatGPT 提问,内容为输入的 Order ## 不满意回答时可以撤回上一步的历史消息 if Order == "撤回上一步历史消息": BaseMessage = BaseMessage[:-2] ## 退出时清空命名空间并重置历史消息 elif Order == "exit": Space = {} BaseMessage = [{"role":"system", "content":Describe}] result = "" ## 正常提问 else: Message = {"role":"user", "content":Order} ## 将提问内容加入历史消息,实现连续对话功能 BaseMessage.append(Message) # 使用函数 openai.ChatCompletion.create() 得到 ChatGPT 返回的响应信息 response = openai.ChatCompletion.create( model = Model, messages = BaseMessage ) # 提取响应中的的代码,存入变量 result result = response['choices'][0]['message']['content'] # 将 ChatGPT 给出的代码存入历史消息中,更新历史对话 add = {"role":"assistant", "content":result} BaseMessage.append(add) print(result) # 查看 ChatGPT 给出的解决代码 ## 指定在创建的命名空间中执行代码,并将结果存储在该空间中 exec(result, globals(), Space)上文中数据可视化的对话过程和实际的返回结果如下。
第一条指令:
Chat_Code(Order = "将当前目录下名为“中国历年数字经济核心产业大类被授权实用新型专利申请数.xlsx”的文件以dataframe数据类型导入,并命名为data。")结果如下:

第二条指令:
Chat_Code(Order = "使用data中的数据,以“申请年份”为横轴,分别以\ “01数字产品制造业被授权实用新型专利数”、\ “02数字产品服务业被授权实用新型专利数”、\ “03数字技术应用业被授权实用新型专利数”和\ “04数字要素驱动业被授权实用新型专利数”为纵轴,绘制四条折线图。")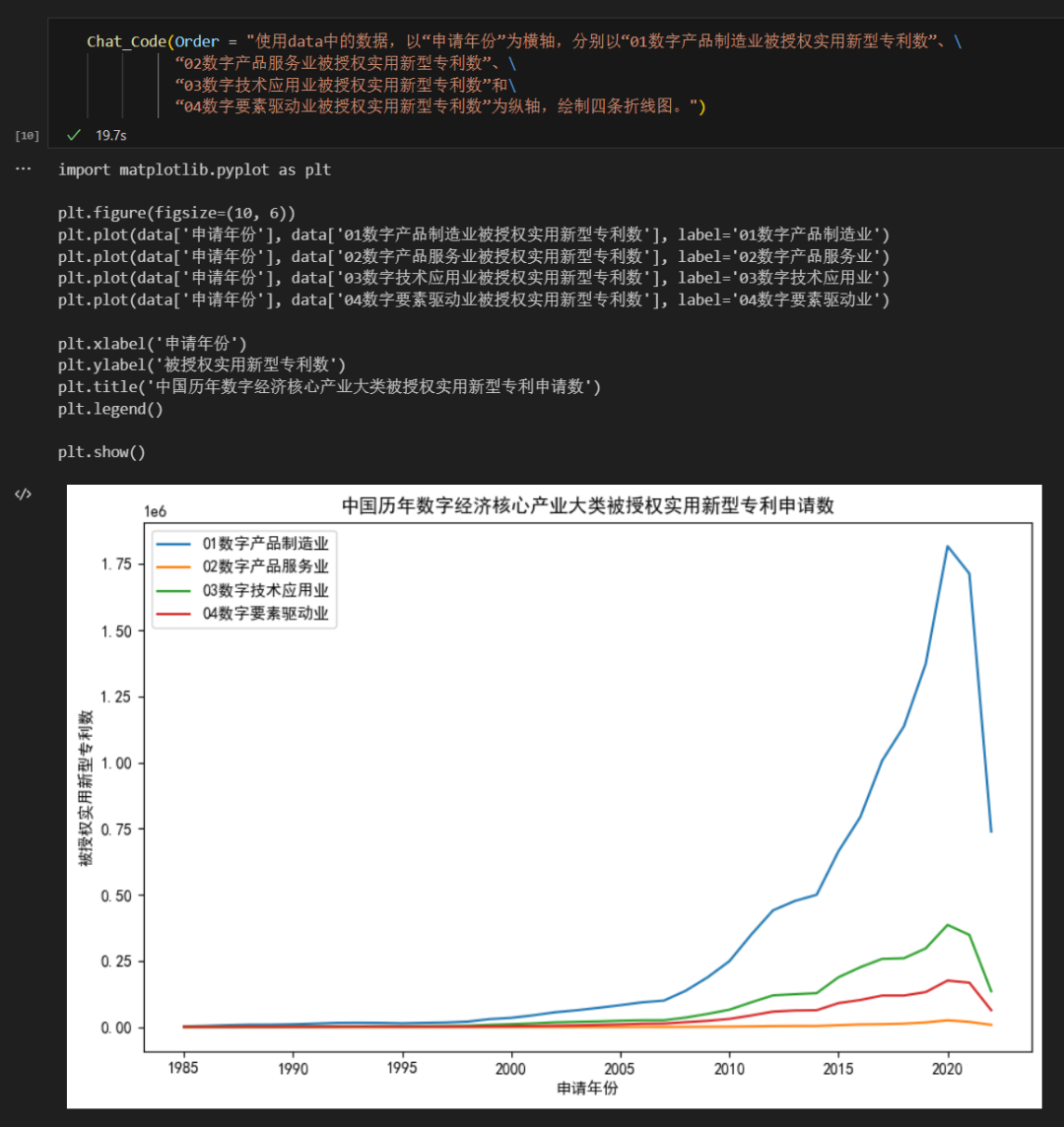
第三条指令:
Chat_Code(Order = "将四个图例分别修改成“数字产品制造业”、\ “数字产品服务业”、\ “数字产品应用业”和\ “数字要素驱动业”。")
第四条指令:
Chat_Code(Order = "在折线图右边添加一个纵轴,\ 内容是data中的“被授权实用新型专利数”字段,\ 横轴不变,在折线图中添加一幅柱状图。")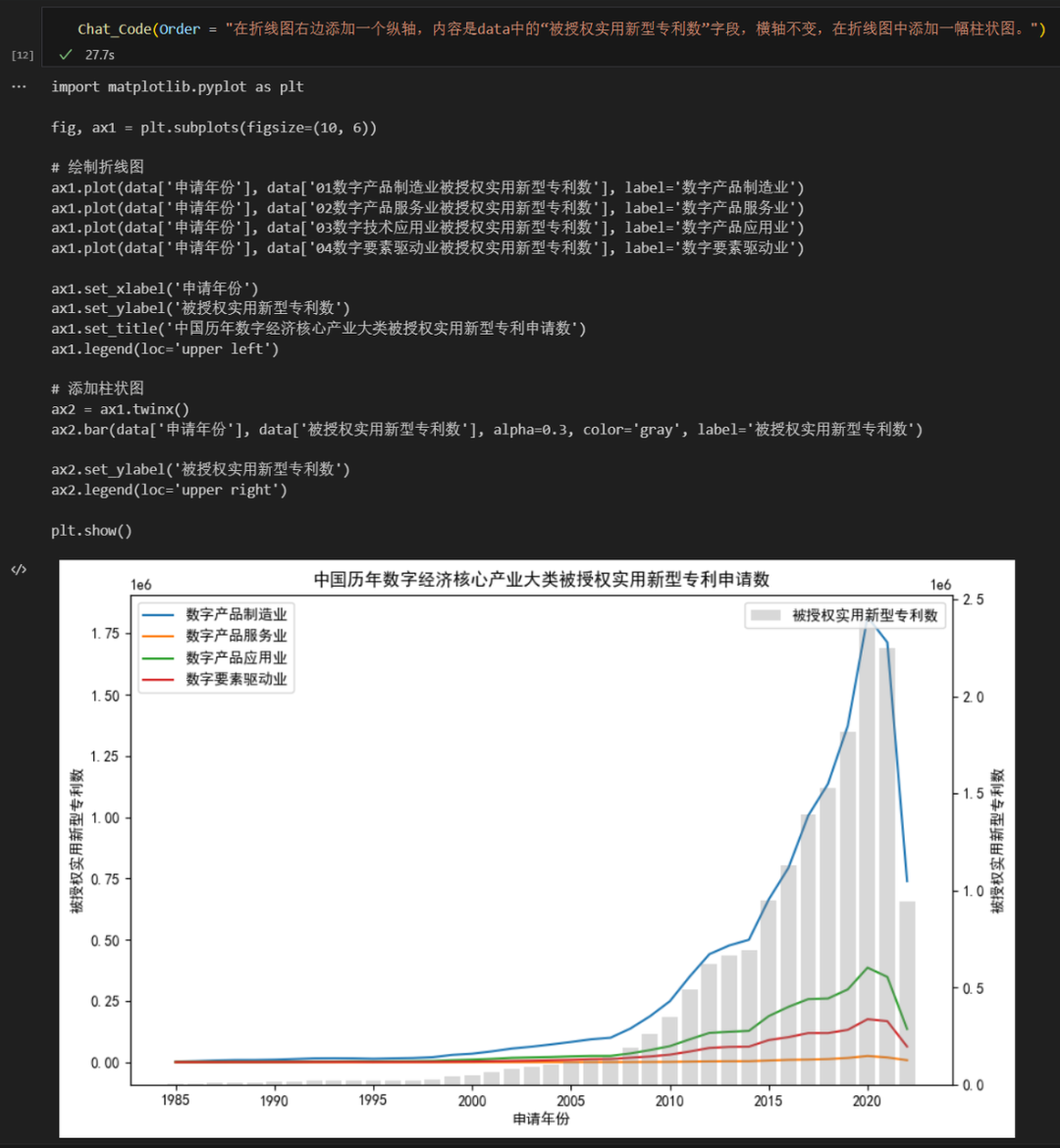
从上文内容中,Python 与 ChatGPT 的结合确实能够让我们的数据处理工作变得简单方便很多。如果延伸一下,我们是不是也可以用它去做一些更复杂,更有意义的事情呢?我们认为,这一定是可行的,不过随着问题难度的增加,影响因素也会更多,最后的成功率也会降低。从这次探索,我们也积累了一些运用 ChatGPT 自动化处理数据的经验,下面分享给大家。
AI 的角色十分重要,正如上文中写到的那样,我们用了几百个字来给 AI 一个初始角色,并限制它的答复格式,所以设计 AI 角色时,需要尽可能详细地描述。
提问或者设计 AI 身份时,语言不要出现歧义。例如在最初设计 AI 角色时,我们只要求 AI 仅返回可运行的代码,但 AI 的回复结果中依然包含一些解释性文字。仔细想一下,这句话(提出的要求)其实是存在歧义的,AI 可能误以为只要不给出不可运行的代码就可以了,与解释性文字无关。
AI 只听从绝对命令,我们不能指望 AI 去实现我们没有说出来的事情。例如上文第四条命令中,我们要求 AI 在折线图的右侧也加一个纵轴,这里笔者内心就默认了新添加的纵轴和原来的左侧纵轴上的刻度是一致的,只有这样才会更加严谨。但是实际上 AI 并没有这样做,给出的结果中两个纵轴的刻度完全没有关系,这也导致图中的柱状图虽然美观,却不严谨。这个问题的根本原因就是我们没有主动提出这个要求,那么 AI 会不会这样做就要看它的心情了。所以为了使 AI 的回答更加严谨,我们在提问时需要尽可能给出准确、细致的要求,越具体越好,比如新添加的柱形图的刻度与左侧的坐标轴刻度保持一致等等。
如果需要让 AI 帮你处理数据,那么一定要描述你的数据,例如有哪些字段,其中存储什么数据,否则 AI 给出的代码可能无法运行。
AI 给出的代码不可能完全正确。影响因素有很多,例如不同版本的 Python 语法不同、不同版本的第三方库语法不同、某个功能已经删除但是 AI 不知道……所以我们不能一味地相信它给出的代码,最好对其回答的正确性有个初步的判断,如果发现了问题,可以进一步向 AI 提出更改的要求。
……
AI 是一个聪明的脑袋,Python 是一副矫健的身体,两者只需要简单地结合一下,就能够发挥出强大的威力,为我们的数据处理带来了许多便利。
来源地址:https://blog.csdn.net/Rocky006/article/details/132604094
--结束END--
本文标题: Python 实战之ChatGPT + Python 实现全自动数据处理/可视化详解
本文链接: https://lsjlt.com/news/398251.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0