文章目录 前言0 摘要1 Introduction and Motivating Work2 Approach2.0 模型整体结构2.1 数据集2.2 选择一种高效的预训练方法2.3 模型选择
多模态模型:CLIP
论文标题:Learning Transferable Visual Models From Natural Language Supervision
论文网址:https://arxiv.org/abs/2103.00020
源码网址:https://github.com/OpenAI/CLIP
备注:本文内容顺序与原论文并不完全一致,是对于该论文的精读与总结,如需更多细节请参考原论文。
CLIP 的方法很简单,但效果却意外的好。CLIP 的迁移能力是非常强的,预训练好的模型能够在任意一个视觉分类的数据集上取得不错的效果,而且最重要的是它是 zero-shot 的,即完全没有在这些数据集上做训练就能得到这么高的性能。作者做了很多实验,在30多个数据集上做了测试,涵盖的面也很广,包括 OCR、视频动作检测、坐标定位、多种类型的细分类任务。CLIP 在不使用 ImageNet 训练集的情况下,也就是不使用 ImageNet 中128万张图片中的任意一张进行训练的情况下,直接 zero-shot 推理,就能获得和之前有监督训练好的 ResNet50 取得同样的效果。
CLIP 最大的贡献就是打破了之前固定种类标签的范式,无论是在收集数据集时,还是在训练模型时,都不需要像 ImageNet 那样做 1000 个类,直接搜集图片和文本的配对就行,然后去预测相似性。在收集数据、训练、推理时都更方便了,甚至可以 zero-shot 去做各种各样的分类任务。
CLIP 打破了之前固定种类标签的方法彻底解除了视觉模型的固有训练过程,引发了一大批后续工作。作者做了大量实验,在许多数据集上 CLIP 的效果都很好,泛化能力也很强,甚至在一些领域比人类的 zero-shot 性能还好。CLIP 用一个模型就能解决大部分的分类任务,而且是 zero-shot 的方式,更何况只要利用好 CLIP 训练好的模型,再在其他领域里稍微适配一下,就能也很好的完成其他领域的任务。CLIP 的灵活性和高效性令人瞩目。
SOTA计算机视觉系统被训练来预测一组固定的预定对象类别。 这种受限的监督形式限制了它们的通用性和适用性,因为需要额外的标记数据来指定任何其他视觉概念。直接从有关图像的原始文本中学习是一个很有希望的替代方案,它利用了更广泛的监督来源。
作者证明了用一个非常简单的预训练任务就可以非常高效的且可扩展的去学习一些最好的图像表征,其中这个任务就是给定一些图片和一些句子,模型需要去判断哪一个句子(标题)与哪一个图像是配对的。使用的数据集是从网上收集的4亿个 图像-文本 对儿,有了这么大的数据集之后就可以选择一种自监督的训练方式去预训练一个大模型出来了(CLIP 使用的是对比学习,对比学习有的文章称为自监督,有的文章称为无监督)。
预训练之后,自然语言就被用来去引导视觉模型去做物体的分类(CLIP 用的是 prompt,下文有讲),分类也不局限于已经学过的视觉概念(即类别),也可以扩展到新的视觉概念,从而使预训练好的模型能够直接在下游任务上做 zero-shot 推理。
为了证明模型的有效性,作者在30多个不同的计算机视觉任务和数据集上做了测试,包含了诸如 OCR、视频动作检测、坐标定位和许多类型的细粒度目标分类等任务。 CLIP 对于大多数任务都是非常好的,在不需要任何数据集的专门训练的情况下,能与完全用有监督方式训练出来的模型取得同样效果,甚至还会更高。 例如,CLIP 在不使用 ImageNet 那128万个训练集的情况下,就跟一个有监督训练好的 ResNet50 打成平手。
在过去的几年里,直接从原始文本中去预训练模型,在 NLP 领域中产生了革命性的成功(如BERT,GPT,T5 等)。无论是使用自回归预测的方式,还是使用掩码”完形填空“的方式,都是一种自监督的训练方式,所以它们的目标函数都是与下游任务无关的,只是想通过预训练得到一个比较好的、泛化能力强的特征,随着计算资源的增多、模型的变大、数据变得更多,模型的能力也会得到稳健的提升。这种其实都是 “text-to-text”(文字进文字出),并不是再做分类任务,它的这种模型架构也是与下游任务无关的。所以直接用在这种下游任务上时,就不需要专门去研究一个针对那个任务或数据集的输出头和一些特殊处理。像 GPT-3 这样的模型现在在许多任务中具有竞争力,在大多数任务上,它几乎不需要特定领域的训练数据就可以和之前精心设计过的那些网络取得差不多的结果。
这些结果表明,在这种 “text-to-text” 利用自监督的方法去训练整个模型的框架下,大规模的没有标注的数据 要比 那些手工标注的、质量非常高的数据集反而要更有效。然而,在 CV 等其它领域,一般的做法还是在 ImageNet 这种数据集上去训练一个模型,这样会使训练好的模型有诸多限制。那么 NLP 里的这套框架是否能用在 CV 里呢?从先前的工作看起来是可以的。
本文主要是与 Learning Visual N-Grams from Web Data (2017年)的工作比较相似,他们都做了 zero-shot 的迁移学习,但当时 TransfORMer 还未提出,也没有大规模的且质量较好的数据集,因此17年的这篇论文的效果并不是很好。有了 Transformer、对比学习、”完形填空“ 等强大的自监督训练方式后,最近也有一些工作尝试把图片和文本结合起来,去学得更好的特征,如 VirTex,ICMLM,ConVIRT,这些工作与 CLIP 很相似,但也有所区别,VirTex使用自回归的预测方式做模型的预训练;ICMLM使用 ”完形填空“ 的方法做预训练;ConVIRT 与 CLIP 很相似,但只在医学影像上做了实验。这三种方法都没有在模型或数据集上使用很大的规模。
模型方面,作者在视觉方面尝试了8个模型,从 ResNet 到 ViT,其中最小的模型和最大的模型的计算量相差了大概100倍。作者发现迁移学习的效果跟模型的大小基本上成正相关。
为了证明 CLIP 的泛化性能,作者测试了30多个数据集,在这些数据集上,CLIP 一般都能和之前精心设计的那些有监督训练好的模型取得同样的效果,甚至更好。作者为了进一步验证 CLIP 学到的模型特征的有效性,暂时先不做 zero-shot,而是去做 linear-probe,即预训练模型训练好之后就把参数冻住,整个 backbone 就不变了,只是从模型里面去抽特征,然后训练最后一层的分类头去做分类任务,在这种情况下,CLIP 也比之前在 ImageNet 训练出来的最好的模型效果要好,而且计算也更加高效。zero-shot CLIP 模型也更加的稳健,当 CLIP 的模型效果与有监督训练好的模型在 ImageNet 上的性能效果持平时,CLIP 的泛化性能也更好。
CLIP 方法的核心就是利用自然语言的监督信号来训练一个比较好的视觉模型。
为什么要用自然语言的监督信号来训练视觉模型?
总之,用自然语言的监督信号来训练视觉模型是非常有潜力的。
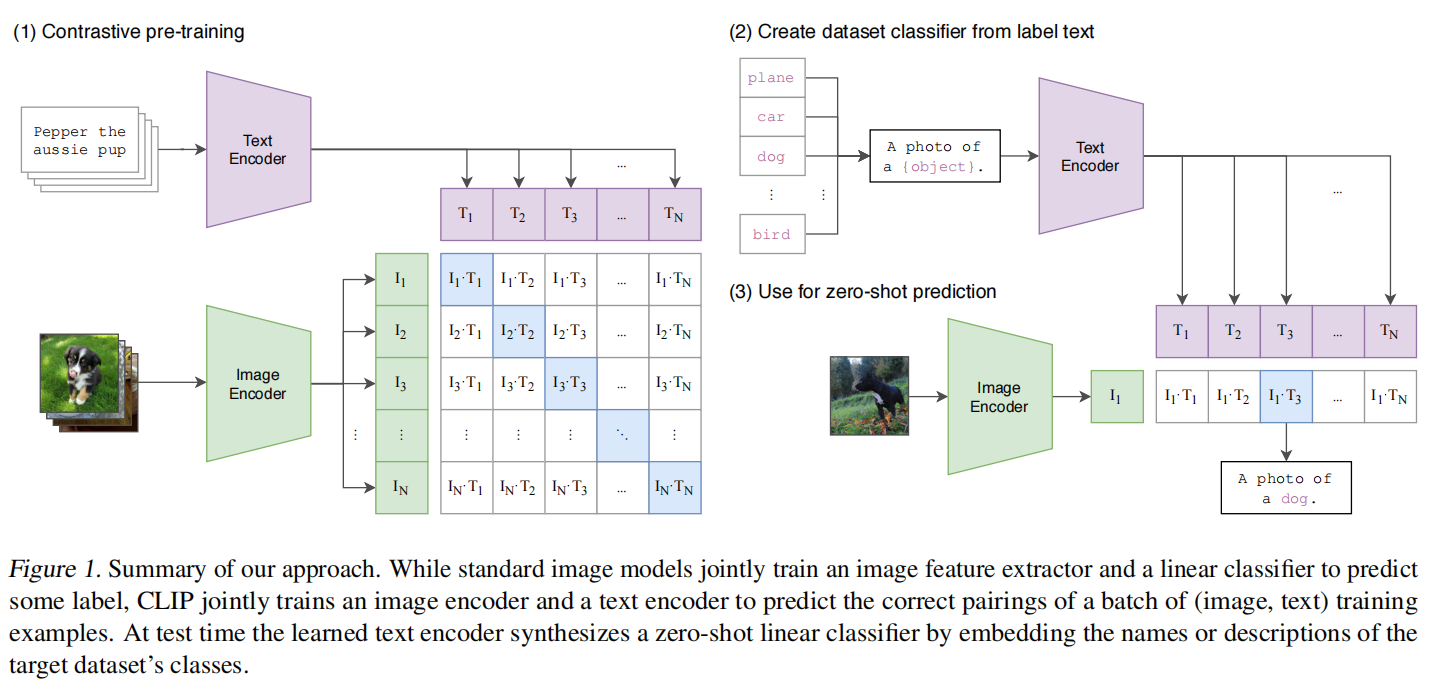
(1) Contrastive pre-training
模型的输入是若干个 图像-文本 对儿(如图最上面的数据中图像是一个小狗,文本是 ”Pepper the aussie pup”)。
图像部分:图像通过一个 Image Encoder 得到一些特征,这个 encoder 既可以是 ResNet,也可以是 Vision Transformer。假设每个 training batch 都有 N 个 图像-文本 对儿,那么就会得到 N 个图像的特征(如图 I 1 , I 2 , … , I N I_1,I_2,…,I_N I1,I2,…,IN)。

文本部分:文本通过一个 Text Encoder 得到一些文本的特征。同样假设每个 training batch 都有 N 个 图像-文本 对儿,那么就会得到N 个文本的特征(如图 T 1 , T 2 , … , T N T_1,T_2,…,T_N T1,T2,…,TN)。
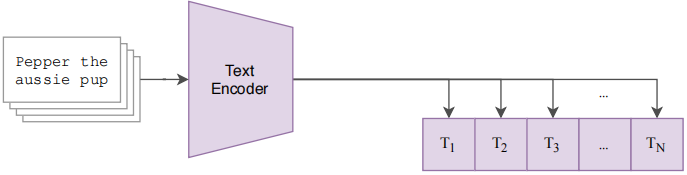
CLIP 就是在以上这些特征上去做对比学习,对比学习非常灵活,只需要正样本和负样本的定义,其它都是正常套路。这里配对的 图像-文本 对儿就是正样本(即下图中对角线(蓝色)部分, I1 ⋅ T1 , I2 ⋅ T 2 , … , IN ⋅ TN I_1·T_1,I_2·T2,…, I_N·T_N I1⋅T1,I2⋅T2,…,IN⋅TN),配对的图像和文本所描述的是同一个东西,那么矩阵中剩下的所有不是对角线上的元素(图中白色部分)就是负样本了。因此,有 N N N 个正样本, N2 − N N^2-N N2−N 个负样本。有了正、负样本后,模型就可以通过对比学习的方式去训练,不需要任何手工的标注。对于这种无监督的预训练方式,如对比学习,是需要大量数据的,OpenAI专门去收集了这么一个数据集,其中有4亿个 图像-文本 对儿,且数据清理的比较好,质量比较高,这也是CLIP如此强大的主要原因之一。

(2) Create dataset classifier from label text
CLIP 经过预训练后只能得到视觉上和文本上的特征,并没有在任何分类的任务上去做继续的训练或微调,所以它没有分类头,那么 CLIP 是如何做推理的呢?

作者提出 prompt template:以 ImageNet 为例,CLIP 先把 ImageNet 这1000个类(如图中"plane", “car”, “dog”, …, “brid”)变成一个句子,也就是将这些类别去替代 “A photo of a {object}” 中的 “{object}” ,以 “plane” 类为例,它就变成"A photo of a plane",那么 ImageNet 里的1000个类别就都在这里生成了1000个句子,然后通过先前预训练好的 Text Encoder 就会得到1000个文本的特征。
其实如果直接用单词(“plane”, “car”, “dog”, …, “brid”)直接去抽取文本特征也是可以的,但是因为在模型预训练时,与图像对应的都是句子,如果在推理的时候,把所有的文本都变成了单词,那这样就跟训练时看到的文本不太一样了,所以效果就会有所下降。此外,在推理时如何将单词变成句子也是有讲究的,作者也提出了 prompt engineering 和 prompt ensemble,而且不需要重新训练模型。
(3) Use for zero-shot prediction

在推理时,无论来了任何一张图片,只要把这张图片扔给 Image Encoder,得到图像特征(绿色框, I1 I_1 I1)后,就拿这个图片特征去跟所有的文本特征(紫色框, T1 , T2 , … , TN T_1,T_2,…,T_N T1,T2,…,TN)去做 cosine similarity(余弦相似度)计算相似度( I1 ⋅ T1 , I1 ⋅ T 2 , I1 ⋅ T 3 , … , I1 ⋅ TN I_1·T_1,I_1·T2, I_1·T3,…, I_1·T_N I1⋅T1,I1⋅T2,I1⋅T3,…,I1⋅TN),来看这张图片与哪个文本最相似,就把这个文本特征所对应的句子挑出来,从而完成这个分类任务。
在实际应用中,这个类别的标签也是可以改的,不必非得是 ImageNet 中的1000个类,可以换成任何的单词;这个图片也不需要是 ImageNet 的图片,也可以是任何的图片,依旧可以通过算相似度来判断这图中含有哪些物体。即使这个类别标签是没有经过训练的,只要图片中有某个物体也是有很大概率判断出来的,这就是 zero-shot。但如果像之前的那些方法,严格按照1000个类去训练分类头,那么模型就只能判断出这1000个类,这1000个类之外的所有内容都将判断不出来。
CLIP 彻底摆脱了 cateGorical label 的限制,无论在训练时,还是在推理时,都不需要有这么一个提前定好的标签列表,任意给出一张图片,都可以通过给模型不同的文本句子,从而知道这张图片里有没有我想要的物体。

CLIP 把视觉的语义和文字的语义联系到了一起,学到的特征语义性非常强,迁移的效果也非常好。如图左侧部分是在 ImageNet 上训练好的 ResNet101,右侧是 CLIP 训练出的 ViT-L,在 ImageNet 上 ResNet 和 CLIP 效果相同,但在 ImageNetV2、ImageNet-R、ObjectNet、ImageNet Sketch、ImageNet-A上,ResNet 的性能明显就不行了,迁移的效果惨目忍睹,但对于 CLIP 来说,它的效果始终都非常好。这也说明了 CLIP 因为和自然语言处理的结合,导致 CLIP 学出来的视觉特征和我们用语言所描述的某个物体产生了强烈的联系。
现有工作主要使用了三个数据集,MS-COCO、Visual Genome 和 YFCC100M。 虽然 MS-COCO 和 Visual Genome 的标注,但是数据量太少了,每个都有大约10万张训练照片。 相比之下,其他计算机视觉系统是在多达35亿张 Instagram 图片上训练的。 拥有1亿张照片的 YFCC100M 是一个可能的替代方案,但标注质量比较差,每个图像配对的文本信息都是自动生成的,许多图片使用自动生成的文件名,如 20160716113957.jpg 作为 “标题” 或包含相机曝光设置的 “说明”(反正就是和图片的信息是不匹配的)。 如果对 YFCC100M 进行清洗,只保留带有自然语言标题或英文描述的图像,数据集缩小了6倍,大概只有1500万张照片, 这个规模就与与ImageNet的大小大致相同。 CLIP 使用的数据集是 OpenAI 新收集的一个数据集,称为 WIT(WEBImageText)。
首先作者尝试了一个跟 VirTex 的工作非常相似的方法,即图像这边使用卷积神经网络,然后文本方面用 Transformer,都是从头开始训练的,任务就是给定一张图片,要去预测这张图片所对应的文本,即caption。

Figure 2. CLIP is much more efficient at zero-shot transfer than our image caption baseline. Although highly expressive, we found that transformer-based language models are relatively weak at zero-shot ImageNet classification. Here, we see that it learns 3x slower than a baseline which predicts a bag-of-Words(BoW) encoding of the text. Swapping the prediction objective for the contrastive objective of CLIP further improves efficiency another 4x.
如图 Figure 2,蓝线部分就是基于 Transformer 做预测型任务(如 GPT)的训练效率;橘黄色线是使用 BOW 的方式做预测任务,也就是说不需要逐字逐句地去预测文本,文本已经被全局化地抽成了一些特征,约束也就放宽了,可以看到约束放宽以后训练效率提高了三倍;如果进一步放宽约束,即不在去预测单词,只是判断图片和文本是否匹配(图中绿线),这个效率又进一步提高了4倍。

如图 Figure 3,是对应 Figure 1 模型总体结构的伪代码:
因为使用的数据集太大了,模型不太会有过拟合(over-fitting)的问题,所以他们的实现就比之前的工作要简单很多。同时也因为数据集很大,也不需要做太多的数据增强,作者唯一使用的数据增强就是随机裁剪。
在训练 CLIP 时,Image Encoder 和 Text Encoder 都不需要提前进行预训练的。最后做投射时,并没有用非线性的投射层(non-linear projection),而是使用线性的投射层(linear projection)。对于以往的对比学习(如SimCLR,MOCO)用非线性的投射层会比用线性的投射层带来将近10个点的性能提升,但作者说在多模态的预训练过程中线性与非线性差别不大,他们认为非线性的投射层应该只是用来适配纯图片的单模态学习。
因为 CLIP 模型太大了,数据集也太大了,训练起来太耗时,所以不太好做调参的工作,所以在算对比学习的目标函数时,将 temperature 设置为可学习的 log-parametized 乘法标量(以往的对比学习中 temperature 是个非常重要的超参数,稍微调整就会使最后的性能发生很大的改变),temperature 在模型训练时被优化了,而不需要当成一个超参数再去调参。
在视觉方面,模型既可以选择 ResNet,也可以是 ViT,文本上基本就是 Transformer,模型的选择都是很常规的,只有很小的改动,但这些改动都是为了训练的更高效、性能更好。
在视觉方面,作者一共训练了 8 个模型,5 个 ResNets 和 3 个 Vision Transformers:
对于所有的模型,都训练 32 epochs,且使用 Adam优化器。对于所有超参数,作者简单的做了一些 Grid Search,Random Search 和手动调整,为了调参快一些,都是基于其中最小的 ResNet50 去做的且只训练 1 epoch,对于更大的模型作者就没有进行调参了。
训练时作者使用的 batch size 为 32768,很显然模型训练是在很多机器上起做分布式训练。同时也用到了混精度训练,不仅能加速训练,而且能省内存。此外作者也做了很多其他省内存的工作。
对于最大的 ResNet 来说,即上文中的RN50x64, 在 592 个 V100 的GPU上训练了18天;而对于最大的 ViT 来说,在 256 个 V100 GPU 上训练只花了 12 天。证实了训练一个 ViT 是要比训练一个 ResNet 更高效的。因为 ViT-L/14 的效果最好,作者又拿与训练好的 ViT-L/14 再在数据集上 fine-tune 了 1 epoch,而且用了更大的图片(336×336),这种在更大尺寸上 fine-tune 从而获得性能提升的思路来自于 Fixing the train-test resolution discrepancy,最后这个模型就称为 ViT-L/14@336px。如无特殊指明,本文中所有 “CLIP” 结果都使用了我们发现效果最好的这个模型(ViT-L/14@336px)。

Visual N-grams 首次以上述方式研究了 zero-shot 向现有图像分类数据集的迁移。如 Table1 所示,作者做了与之前最相似的工作 Visual N-grams 的对比,Visual N-grams 在 ImageNet 的效果只有 11.5% 的准确率,而 CLIP 能达到 76.2%,CLIP 在完全没有用任何一张那128万张训练图片的情况下,直接 zero-shot 迁移就与原始的 ResNet50 打成平手。
prompt 主要是在做 fine-tune 或做推理时的一种方法,而不是在预训练阶段,所以不需要那么多的计算资源,并且效果也很好。prompt 指的是 提示,即文本的引导作用。
为什么需要做 Prompt Engineering and Prompt Ensembling?
基于以上两种问题作者提出了 prompt template(提示模板),“A photo of a { label }”。首先所有的标签都变成了一个句子,就不容易出现 distribution gap。而且 label 也一般都是名词,也能减少歧义性的问题。使用 prompt template 后准确率提升了 1.3%。
Prompt Engineering 不只给出这么一个提示模板,作者发现如果提前知道一些信息,这样对 zero-shot 的推理是很有帮助的。假如现在做的事 Oxford-IIIT Pet 这个数据集,这里面的类别一定是宠物,那么提示模板可以变为 “A photo of a { label }, a type of pet.”,把解空间缩小了很多,很容易得到正确的答案。当对于 OCR(文字识别)数据集来说,如果在想找的文本上添加双引号,那么模型也是更容易找到答案。
Prompt Ensembling:使用多个提示模版,做多次推理,最后再把结果结合起来,一般都会取得更好的结果。在源码 CLIP/notebooks/Prompt_Engineering_for_ImageNet.ipynb 文件中,这里提供了 80 种提示模板,以便适用于不同的图片。

Figure 5.
作者在 27 个数据集上衡量了 CLIP 做 zero-shot 迁移的效果,如图 Figure 5,比较的双方分别是 做 zero-shot 的 CLIP 和 在 ResNet50 上做 linear probe(linear probe:把预训练好的模型中的参数冻结,只从里面去提取特征,然后只训练最后一层即 FC 分类头层)。这个 ResNet 是在 ImageNet 有监督训练好的模型,从中去抽特征,然后在下游任务中去添加新的分类头,在新的分类头上做 linear probe 的微调。

Figure 5. Zero-shot CLIP is competitive with a fully supervised baseline. Across a 27 dataset eval suite, a zero-shot CLIP classifier outperforms a fully supervised linear classifier fitted on ResNet-50 features on 16 datasets, including ImageNet.
图中绿色部分就是 CLIP 优于 ResNet50 的,蓝色部分就是劣于 ResNet50 的。zero-shot CLIP 在 16 个数据集上都取得不错的效果,这种普通的对物体进行分类的数据集来说 CLIP 的表现都比较好。但一些难的数据集,如 DTD(对纹理进行分类),CLEVRCounts(对图片中物体计数),对于 CLIP 就很难,而且很抽象,先前训练时也没有这种相关标签,所以 CLIP 在这些数据集上表现得不好。对于这种特别难的任务如果只做 zero-shot 不太合理,更适合去做 few-shot 的迁移,对于这种需要特定领域知识的任务(如肿瘤分类等)即是对于人类来说没有先验知识也是很难得。
Figure 6.
作者对 zero-shot CLIP,few-shot CLIP 和之前 few-shot 的一些方法(预训练好冻结参数,然后做 linear probe,在下游任务数据集上进行训练)做了一些比较。这里 CLIP 的 few-shot 是将 Image Encoder 的参数冻结,然后做 linear probe。

Figure 6. Zero-shot CLIP outperforms few-shot linear probes. Zero-shot CLIP matches the average performance of a 4-shot linear classifier trained on the same feature space and nearly matches the best results of a 16-shot linear classifier across publicly available models. For both BiT-M and SimCLRv2, the best performing model is highlighted. Light gray lines are other models in the eval suite. The 20 datasets with at least 16 examples per class were used in this analysis.
Figure 6 横坐标是数据集中每一个类别里用了多少训练样本,0 的话就是 zero-shot 了,其他方法因为没有和自然语言的结合无法做 zero-shot,最低也得从 one-shot 开始。
纵坐标是平均准确度,是在 20 个数据集上取的平均(来源于 Figure 5 中的27 个数据集,其中有 7 个数据集的部分类别训练样本不足 16 个,无法满足横坐标要求,因此舍弃了)。
BiT(Big Transfer)主要为迁移学习量身定做,是 few-shot 迁移学习表现最好的工作之一。而 zero-shot CLIP 直接就和最好的 BiT 持平。如图紫色曲线,当每个类别仅仅用1、2、4个训练样本时还不如 zero-shot 的效果,这也证明了用文本来引导多模态学习是多么的强大。随着训练样本的增多, few-shot CLIP 的效果是最好的,不仅超越了之前的方法,也超越了 zero-shot CLIP。
这里作者讨论了下游任务用全部数据,CLIP 的效果会如何。特征学习一般都是先预训练一个模型,然后在下游任务上用全部的数据做微调。这里在下游任务上用全部数据就可以和之前的特征学习方法做公平对比了。
衡量模型的性能最常见的两种方式就是通过 linear probe 或 fine-tune 后衡量其在各种数据集上的性能。linear probe 就是把预训练好的模型参数冻结,然后在上面训练一个分类头;fine-tune 就是把整个网络参数都放开,直接去做 end-to-end 的学习。fine-tune 一般是更灵活的,而且在下游数据集比较大时,fine-tune往往比 linear probe 的效果要好很多。
但本文作者选用了 linear probe,因为 CLIP 的工作就是用来研究这种跟数据集无关的预训练方式,如果下游数据集足够大,整个网络都放开再在数据集上做 fine-tune 的话,就无法分别预训练的模型到底好不好了(有可能预训练的模型并不好,但是在 fine-tune 的过程中经过不断的优化,导致最后的效果也很好)。而 linear probe 这种用线性分类头的方式,就不太灵活,整个网络大部分都是冻住的,只有最后一层 FC 层是可以训练的,可学习的空间比较小,如果预训练的模型不太好的话,即使在下游任务上训练很久,也很难优化到特别好的结果,所以更能反映出预训练模型的好坏。此外,作者选用 linear probe 的另一个原因就是不怎么需要调参,CLIP 调参的话太耗费资源了,如果做 fine-tune 就有太多可做的调参和设计方案了。
Figure 10.

Figure 10. Linear probe performance of CLIP models in comparison with state-of-the-art computer vision models, including EfficientNet, MoCo, Instagram-pretrained ResNeXt models, BiT, ViT, SimCLRv2, BYOL, and the original ResNet models. (Left) Scores are averaged over 12 datasets studied by Kornblith et al. (2019). (Right) Scores are averaged over 27 datasets that contain a wider variety of distributions. Dotted lines indicate models fine-tuned or evaluated on images at a higher-resolution than pre-training. See Table 10 for individual scores and Figure 20 for plots for each dataset.
如 Figure 10 右图所示,是在先前提到的那 27 个数据集进行比较,CLIP(实心、空心红色五角星)比所有的其他模型都要好,不光是上文中讲过的 zero-shot 和 few-shot,现在用全部的数据去做训练时 CLIP 依然比其他模型强得多。
如 Figure 10 左图所示,之前有工作提出了这 12 个数据集的集合,很多人都是在这些数据集上做的比较,CLIP-ViT 的效果是很好的,但是 CLIP-ResNet 就要比别的方法差了。但是这 12 个数据集的集合和 ImageNet 的关系很大,如果模型之前在 ImageNet 做过有监督的预训练,那么效果肯定是更好的,因此 CLIP-ResNet 并没有那么好也是可以理解的。
Figure 11.

Figure 11. CLIP’s features outperform the features of the best ImageNet model on a wide variety of datasets. Fitting a linear classifier on CLIP’s features outperforms using the Noisy Student EfficientNet-L2 on 21 out of 27 datasets.
随后作者又将 CLIP 与 之前在 ImageNet 上表现最好的模型 EfficientNet L2 NS(最大的 EfficientNet 并使用为标签的方式训练)进行对比。在 27 个数据集中,CLIP 在其中 21 个数据集都超过了 EfficientNet,而且很多数据集都是大比分超过,少部分数据集也仅仅是比 EfficientNet 稍低一点点。
Figure 13.
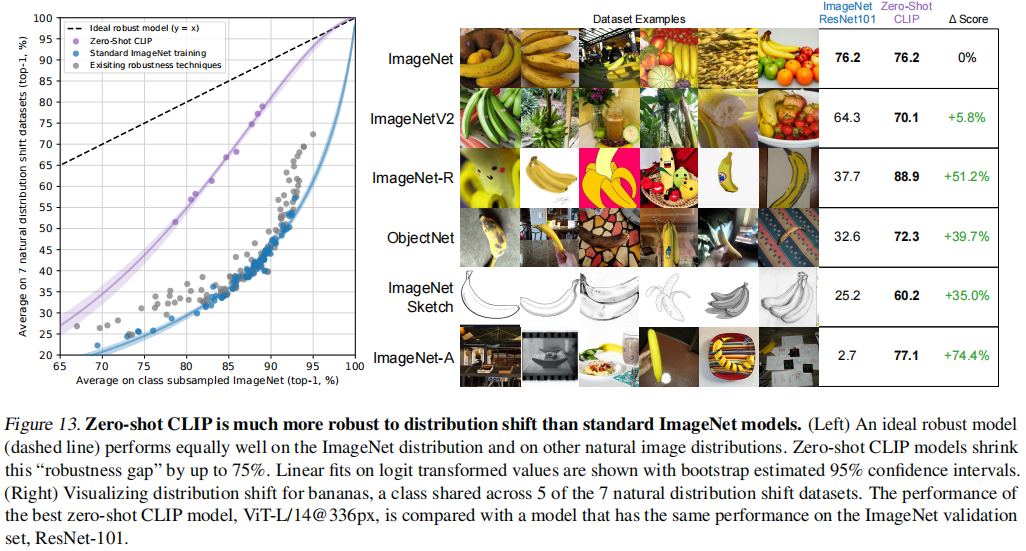
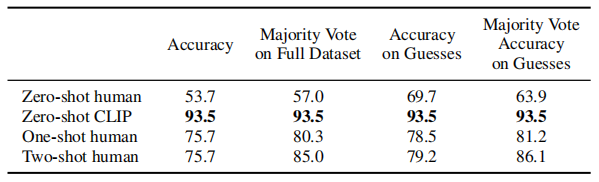
Table 2. Comparison of human performance on Oxford IIT Pets. As in Parkhi et al. (2012), the metric is average per-class classification accuracy. Most of the gain in performance when going from the human zero shot case to the human one shot case is on images that participants were highly uncertain on. “Guesses” refers to restricting the dataset to where participants selected an answer other than “I don’t know”, the “majority vote” is taking the most frequent (exclusive of ties) answer per image.
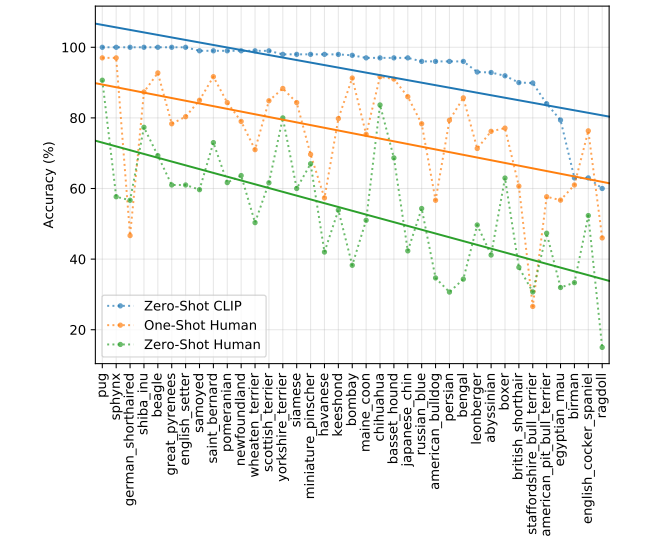
Figure 16. The hardest problems for CLIP also tend to be the hardest problems for humans. Here we rank image categories by difficulty for CLIP as measured as probability of the correct label.
为了分析是否是因为本文使用的数据集与其他的数据集之间有重叠而导致模型的性能比较好,作者在这部分做了一些去重的实验,最后的结论还是 CLIP 本身的泛化性能比较好。
(1) CLIP 在很多数据集上平均来看都能和普通的 baseline 模型(即在 ImageNet 训练的 ResNet50)打成平手,但是在大多数数据集上,ResNet50 并不是 SOTA,与最好的模型比还是有所差距的,CLIP 很强,但又不是特别强。实验表明,如果加大数据集,也加大模型的话,CLIP 的性能还能继续提高,但如果想把各个数据集上的 SOTA 的差距弥补上的话,作者预估还需要在现在训练 CLIP 的计算量的基础上的 1000 倍,这个硬件条件很难满足。如果想要 CLIP 在各个数据集上都达到 SOTA 的效果,必须要有新的方法在计算和数据的效率上有进一步的提高。
(2) zero-shot CLIP 在某些数据集上表现也并不好,在一些细分类任务上,CLIP 的性能低于 ResNet50。同时 CLIP 也无法处理抽象的概念,也无法做一些更难的任务(如统计某个物体的个数)。作者认为还有很多很多任务,CLIP 的 zero-shot 表现接近于瞎猜。
(3) CLIP 虽然泛化能力强,在许多自然图像上还是很稳健的,但是如果在做推理时,这个数据与训练的数据差别非常大,即 out-of-distribution,那么 CLIP 的泛化能力也很差。比如,CLIP 在 MNIST 的手写数字上只达到88%的准确率,一个简单的逻辑回归的 baseline 都能超过 zero-shot CLIP。 语义检索和近重复最近邻检索都验证了在我们的预训练数据集中几乎没有与MNIST数字相似的图像。 这表明CLIP在解决深度学习模型的脆弱泛化这一潜在问题上做得很少。 相反,CLIP 试图回避这个问题,并希望通过在如此庞大和多样的数据集上进行训练,使所有数据都能有效地分布在分布中。
(4) 虽然 CLIP 可以做 zero-shot 的分类任务,但它还是在你给定的这些类别中去做选择。这是一个很大的限制,与一个真正灵活的方法,如 image captioning,直接生成图像的标题,这样的话一切都是模型在处理。 不幸的是,作者发现 image captioning 的 baseline 的计算效率比 CLIP 低得多。一个值得尝试的简单想法是将对比目标函数和生成目标函数联合训练,希望将 CLIP 的高效性和 caption 模型的灵活性结合起来。
(5) CLIP 对数据的利用还不是很高效,如果能够减少数据用量是极好的。将CLIP与自监督(Data-Efficient Image Recognition with Contrastive Predictive Coding;Big Self-Supervised Models are Strong Semi-Supervised Learners)和自训练(Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Network;Self-training with Noisy Student improves ImageNet classification)方法相结合是一个有希望的方向,因为它们证明了比标准监督学习更能提高数据效率。
(6) 在研发 CLIP 的过程中为了做公平的比较,并得到一些回馈,往往是在整个测试的数据集上做测试,尝试了很多变体,调整了很多超参,才定下了这套网络结构和超参数。而在研发中,每次都是用 ImageNet 做指导,这已经无形之中带入了偏见,且不是真正的 zero-shot 的情况,此外也是不断用那 27 个数据集做测试。创建一个新的任务基准,明确用于评估广泛的 zero-shot 迁移能力,而不是重复使用现有的有监督的数据集,将有助于解决这些问题。
(7) 因为数据集都是从网上爬的,这些图片-文本对儿基本是没有经过清洗的,所以最后训练出的 CLIP 就很可能带有社会上的偏见,比如性别、肤色、宗教等等。
(8) 虽然我们一直强调,通过自然语言引导图像分类器是一种灵活和通用的接口,但它有自己的局限性。 许多复杂的任务和视觉概念可能很难仅仅通过文本来指导,即使用语言也无法描述。不可否认,实际的训练示例是有用的,但 CLIP 并没有直接优化 few-shot 的性能。 在作者的工作中,我们回到在CLIP特征上拟合线性分类器。 当从 zero-shot 转换到设置 few-shot 时,当 one-shot、two-shot、four-shot 时反而不如 zero-shot,不提供训练样本时反而比提供少量训练样本时查了,这与人类的表现明显不同,人类的表现显示了从 zero-shot 到 one-shot 大幅增加。今后需要开展工作,让 CLIP 既在 zero-shot 表现很好,也能在 few-shot 表现很好。
作者的研究动机就是在 NLP 领域利用大规模数据去预训练模型,而且用这种跟下游任务无关的训练方式,NLP 那边取得了非常革命性的成功,比如 GPT-3。作者希望把 NLP 中的这种成功应用到其他领域,如视觉领域。作者发现在视觉中用了这一套思路之后确实效果也不错,并讨论了这一研究路线的社会影响力。在预训练时 CLIP 使用了对比学习,利用文本的提示去做 zero-shot 迁移学习。在大规模数据集和大模型的双向加持下,CLIP 的性能可以与特定任务的有监督训练出来的模型竞争,同时也有很大的改进空间。
来源地址:https://blog.csdn.net/Friedrichor/article/details/127272167
--结束END--
本文标题: 【论文&模型讲解】CLIP(Learning Transferable Visual Models From Natural Language Supervision)
本文链接: https://lsjlt.com/news/397727.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0