目录 一. 前言 二. 什么是C++ 三. C++关键字初探 四. 命名空间 4.1 为什么要引入命名空间 4.2 命名空间的定义 4.3 命名空间使用 五. C++的输入输出 六. 缺省参数 6.1 缺省参数的概念 6.2 缺

目录
旧坑未填,新坑又起。今天我们又要开启一个新的系列:c++深入浅出。振奋人心的C++学习终于来了![]() 在本系列中,你能感受到C++相比C语言特有的魅力,尽管学习的过程中可能会充满坎坷,但风雨之后,仰望天空,即使没有彩虹,也会是睛空。学完C++后,你甚至可以在C++中用短短几行代码就搞定C语言几十上百行的代码,是不是很神奇,这还只是C++其中的一个强大之处哦。所以,不要恐惧,让我们一起怀着激动的心情打开C++的大门吧
在本系列中,你能感受到C++相比C语言特有的魅力,尽管学习的过程中可能会充满坎坷,但风雨之后,仰望天空,即使没有彩虹,也会是睛空。学完C++后,你甚至可以在C++中用短短几行代码就搞定C语言几十上百行的代码,是不是很神奇,这还只是C++其中的一个强大之处哦。所以,不要恐惧,让我们一起怀着激动的心情打开C++的大门吧![]()

C语言是结构化和模块化的语言,适合处理较小规模的程序。对于复杂的问题,规模较大的
程序,需要高度的抽象和建模时,C语言则不合适。为了解决软件危机, 20世纪80年代, 计算机
界提出了OOP(object oriented programming:面向对象)思想,支持面向对象的程序设计语言
应运而生。
1982年,Bjarne Stroustrup博士在C语言的基础上引入并扩充了面向对象的概念,发明了一
种新的程序语言。为了表达该语言与C语言的渊源关系,命名为C++。因此:C++是基于C语言而
产生的,它既可以进行C语言的过程化程序设计(C++兼容C语言),又可以进行以抽象数据类型为特点的基于对象的程序设计,还可以进行面向对象的程序设计。
在C语言的学习过程中,我们前前后后一共学到了32个关键字。而C++作为C语言的扩展,一共多达63个关键字,如下表所示:
注:这里稍微知道一下有这些关键字即可,后面学到具体应用时再进行细讲
在写C语言代码时,你是否写过类似这样的代码:
#include#includeint rand = 0;int main(){printf("%d", rand);return 0;} 当你Ctrl+F5兴冲冲的编译运行时,发现不解情的编译器报出了重定义的错误:

由于预处理阶段会将头文件进行展开,而在我们的stdlib.h头文件中存在着名为rand的随机数函数,而C语言是不允许在相同作用域下定义多个同名符号的,因此会报出重定义的错误。
#include#include int rand = 0; //前面已经将rand全局定义为函数,这里又定义为全局变量,顾重定义int main(){int rand = 0; //这里rand是局部变量,作用域不同,局部优先,因此不会报错rand(); //由于rand是局部优先,这里的rand是个局部变量,顾无法作为函数使用,报错printf("%d", rand);return 0;} 在上面的代码中,我们无论将rand定义成全局变量还是局部变量,都无法实现我们想要的效果,那怎么办呢?将rand变量的名字换一个呗,得不到就不要强求啦
但是在C++中,新增了命名空间来对标识符的名称进行本地化,以避免命名冲突或名字污染,上面的问题就被很好的解决了。
所以说,努力拓展提升自己,能力够了自然也就得到了
定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可。{}中的内容即为命名空间的成员。命名空间内的成员可以是变量,也可以是函数、类型,甚至可以是另一个命名空间。
namespace Dream //namespace关键字 + 命名空间名称{//命名空间内定义变量int a;int b = 10;//命名空间内定义函数int add(int x,int y){return x + y;}//命名空间内定义类型struct Stack{int* a;int top;int capacity;};//命名空间嵌套定义namespace other{int a;int b = 10;}}注意:一个命名空间定义了一个新的作用域,命名空间中的所有内容都局限于该命名空间中
此外, 如果我们在同一工程中定义了两个相同名称的命名空间(无论在哪个文件),编译器最终会合并到同一个命名空间中![]()
//test1.cppnamespace Dream{int a = 5;int b = 10;}//test2.cppnamespace Dream{int Add(int x, int y){return x + y;}}//上面两个同名命名空间编译器最终会进行合并,结果如下:namespace Dream{int a = 5;int b = 10;int Add(int x, int y){return x + y;}}那么,定义了命名空间后,我们要如何使用它呢?如果我们直接对命名空间的成员进行访问,编译器会报错:
#includenamespace Dream{int b = 10;}int main(){printf("%d", b); //报错,b只在Dream作用域内有效return 0;} 
我们一般有一下三种使用方法:
1、变量名前加命名空间名称及作用域限定符
namespace Dream{int b = 10;namespace other{int b = 5;}}int main(){printf("%d", Dream::b); //表示Dream命名空间内的b,即输出10 printf("%d", Dream::other::b); //表示Dream命名空间内的other命名空间内的b,即输出5return 0;}分析:两个变量b虽然名称相同,但被划分到了两个命名空间中,作用域不同,因此不会出现重定义的问题。并且,通过在前面加上对应的命名空间我们可以实现对这两个变量b的访问。
2、使用using将命名空间中某个成员展开
但是如果命名空间中的某个变量需要在程序中频繁的进行使用,每次都要在前面加上命名空间未免显得过于繁琐,因此C++还允许我们使用using关键字将命名空间中某个成员展开![]()
namespace Dream{int a = 5;int b = 10;}using Dream::a;//int a = 10; //由于上方将变量a展开,a的作用域相当于全局,这里如果再定义a会重定义int main(){a += 10; //引入了a,顾不需要再前面加上命名空间printf("%d\n", a);printf("%d", Dream::b); //而变量b没有展开,故需加上命名空间return 0;}3、使用using naespace 将整个命名空间展开
当然,如果你愿意的话,你也可以将整个命名空间展开,这样整个命名空间的东西都将暴露在全局。具体方式如下![]()
namespace Dream{int a = 5;int b = 10;}using namespace Dream; //展开后使用命名空间内的变量就无需再加前缀int main(){a += 10;printf("%d\n", a);printf("%d", b);return 0;}下面,我们再来看看许多C++程序中经常出现的写法就很清楚了:
#includeusing namespace std;int main(){return 0;}
- 第一条语句的作用是包含输入输出流,下面我们会进行说明,这里我们可以暂且将理解为C语言的#include
- 第二条语句是不是很熟悉啦,没错,就是用来展开命名空间std的。std的英文全拼是Standard,即标准的意思。C++标准程序库中的所有标识符都被定义在这个命名空间中。顾这里将整个命名空间引入是为了后续更方便的使用C++标准程序库的标识符,如函数、类型等等。
但是,虽然方便,但在实际工程中并不建议直接将整个命名空间展开。原因是在大规模工程中,定义的变量太多,可能会出现定义的变量名与std命名空间的标识符出现重复的情况,此时如果将std全部展开就会出现重定义的BUG。
故比起将命名空间全部展开,我们更推荐使用第一种或者第二种使用方式。
在学习C语言时,我们写的第一个代码就是hello world,那么在我们第一次接触C++时,是不是也应该使用C++对美好的世界打个招呼呢?我们来试试C++是怎么实现输入输出的吧!![]()
#includeusing namespace std; //展开std命名空间int main(){cout << "hello world!!!" << endl; //打印输出return 0;} 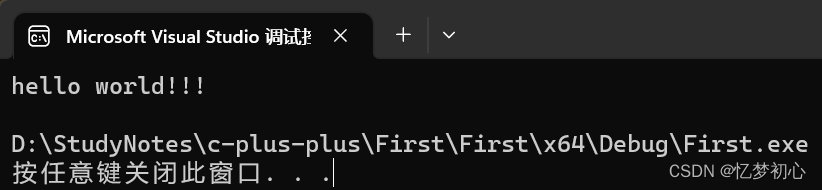
下面我们来分析分析上面的代码
1、使用cout标准输出对象(控制台)和cin标准输入对象(键盘)时,必须包含
头文件
以及按命名空间使用方法使用std。是的,iOStream也是一个头文件噢。2、cout和cin是全局的流对象,它们分别是ostream和istream类型的对象。而endl是特殊的C++符号,表示换行输出,他们都包含在包含在
头文件中。 3、<<是流插入运算符,>>是流提取运算符。它们是不是和我们C语言学到的左移和右移一模一样?是的,这实际上是一种运算符重载,我们后续会提到。
4、使用C++输入输出更方便,不需要像printf/scanf输入输出时那样需要手动控制格式,即%d、%f等等。C++的输入输出可以自动识别变量类型。
注意:早期标准库将所有功能在全局域中实现,声明在.h后缀的头文件中,使用时只需包含对应头文件即可,后来将其实现在std命名空间下,为了和C语言头文件区分,也为了正确使用命名空间,规定C++头文件不带.h,这就是为什么
也是头文件的原因。旧编译器(vc 6.0)中还支持 格式,后续编译器已不支持,因此推荐使用 +std的方式 。
缺省参数是声明或定义函数时为函数的参数指定一个缺省值(默认值)。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。具体形式如下:
#includeusing namespace std;void Func(int a = 0) //给定缺省值0{cout << a << endl;}int main(){Func(); // 没有传参时,使用参数的默认值Func(10); // 传参时,使用指定的实参return 0;} 缺省参数分为全缺省参数和半缺省参数
全缺省参数
即所以参数都带有缺省值![]()
void Func(int a = 10, int b = 20, int c = 30){ cout<<"a = "< 半缺省参数 即部分参数都带有缺省值
void Func(int a, int b = 10, int c = 20) //除了a其余参数都有缺省值{ cout<<"a = "< 注意事项 - 规定半缺省参数必须从右往左依次给出,不能间隔着给。示例如下:
//错误写法,必须从右往左不间断void Func(int a = 10, int b, int c) {};void Func(int a = 10, int b = 20, int c) {};void Func(int a = 10, int b, int c = 30) {};//正确写法void Func(int a, int b, int c = 30) {};void Func(int a, int b = 20, int c = 30) {};
-
缺省参数不能在函数声明和定义中同时出现。其目的是为了防止我们在声明和定义中给出了不同的缺省值,从而导致歧义。
//错误的写法//test.hvoid Func(int a = 10);// atest.cppvoid Func(int a = 20){}
-
缺省值必须是常量或者全局变量
-
C语言不支持带缺省参数的函数(编译器不支持)
七. 函数重载
7.1 函数重载的概念
函数重载:它是一种函数的特殊情况。C++允许在同一作用域中声明几个功能类似的同名函数,这
些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似、数据类型不同的问题。
假设我们要写一个Add函数实现两个整型以及两个浮点型的相加,在C语言中,我们应该这么写:
//C语言写法int iAdd(int x, int y){return x + y;}double dAdd(double x, double y){return x + y;}int main(){iAdd(1, 2);dAdd(1.0, 2.0);return 0;}
由于实参的类型不同,我们需要写两个Add函数分别实现整形和浮点型的相加,并且为了避免重定义,两个函数名必须不同,难道这不觉得很别扭吗
而C++引入了函数重载,我们就能很舒服的使用相同名称来定义这两个参数不同的函数:
//C++写法,两个Add函数构成函数重载int Add(int x, int y){return x + y;}double Add(double x, double y){return x + y;}int main(){Add(1, 2);Add(1.0, 2.0);return 0;}
7.2 函数重载的条件
C++构成函数重载的条件是形参列表必须不同。形参列表不同分为以下三种:
1、参数个数不同
#includeusing namespace std;//2、参数个数不同void Fun(int x){cout << "void Fun(int x)" << endl;}void Fun(){cout << "void Fun()" << endl;}int main(){Fun(1); //调用第一个Fun(); //调用第二个}
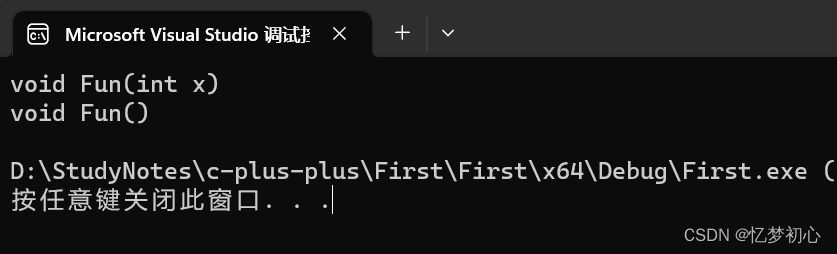
2、参数类型不同
#includeusing namespace std;//2、参数类型不同int Add(int x, int y){cout << "int Add(int x, int y)" << endl;return x + y;}double Add(double x, double y){cout << "double Add(double x, double y)" << endl;return x + y;}int main(){Add(1, 2); //调用第一个Add(1.0, 2.0); //调用第二个}
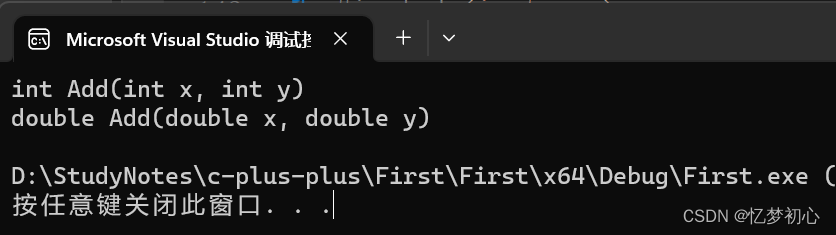
3、参数顺序不同
#includeusing namespace std;//3、参数顺序不同void Fun(int x , double y){cout << "void Fun(int x , double y)" << endl;}void Fun(double x, int y){cout << "void Fun(double x, int y)" << endl;}int main(){Fun(1,2.0); //调用第一个Fun(2.0,1); //调用第二个}
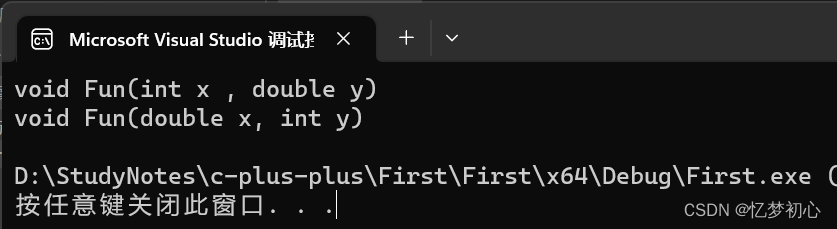
注意:是参数类型的顺序不同,而不是变量名顺序不同,即以下写法不构成函数重载:
//变量名顺序不同不构成函数重载,形参的名称只是标识,本质上还是同一个函数void Fun(int x , double y){};void Fun(int y , double x){};
4、缺省函数的重载
此外,带缺省参数的函数也可以构成函数重载,编译并不会报错,但使用上可能会出现一些很尴尬的问题,举例如下
#includeusing namespace std;//4、缺省函数的重载void Fun(int x, double y = 1.0){cout << "void Fun(int x , double y = 1.0 )" << endl;}void Fun(int x){cout << "void Fun(int x)" << endl;}int main(){Fun(1, 2.0); //这里会调用第一个函数没问题Fun(1); //此时既可以调用第一个函数,也可以调用第二个函数,存在歧义,会报错}
由于缺省函数的重载很容易引发歧义,顾我们一般不也会这么写
7.3 C++支持函数重载的原因
可能会有很多小伙伴会疑惑:为什么C++支持函数重载,而C语言不支持函数重载呢?、
在C/C++中,一个程序要运行起来,需要经历以下几个阶段:预处理、编译、汇编、链接
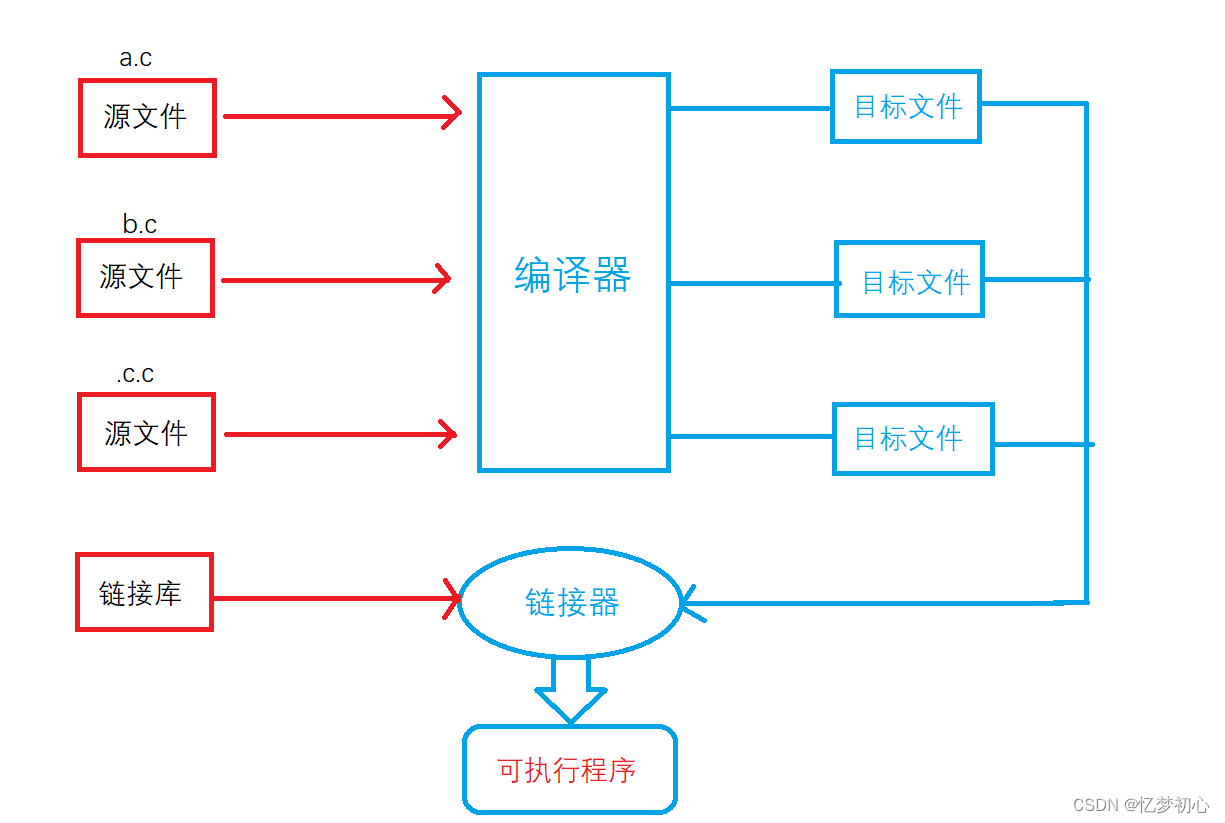

我们发现,每个.c文件都会生成属于自己的符号表。main.c文件中sum函数只是声明,故在符号表中并没有sum函数的地址。而sum.c文件中的sum函数是定义,故在符号表中存在着sum函数的地址。当链接器进行链接时,就会将两张符号表进行合并,此时符号表中既有main函数的地址,也有sum函数的地址,程序便可以正常运行。
但是,如果两个文件中的sum函数都是定义呢?如下: 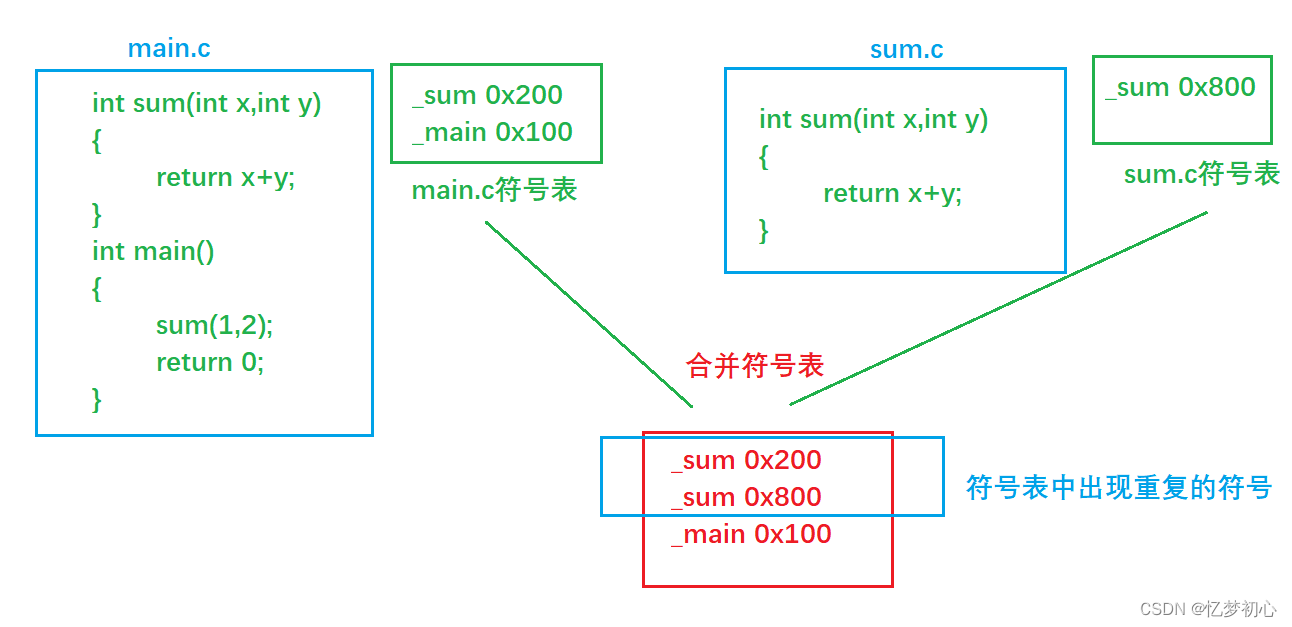
由于两个符号表中的sum函数都是有效地址,进行符号表合并后,符号表就会出现上面的相同符号不同地址的情况,会引发符号表的歧义,此时我们就不知道该去哪个地方找sum函数了,会报重定义的错误。
这就是为什么C语言不能定义同名函数的原因:重定义会引发符号表的歧义。
那就有人会想:C语言不行,那凭什么放到C++就可以呢,搞特殊?
首先要说明的是,上面的两个Add函数放到C++依然不构成函数重载,因为它们的类型相同。那C++为什么类型不同就允许同名函数的存在呢?这是因为C++引入了函数名修饰规则,函数在符号表中除了名称,还一并将参数类型代入修饰。
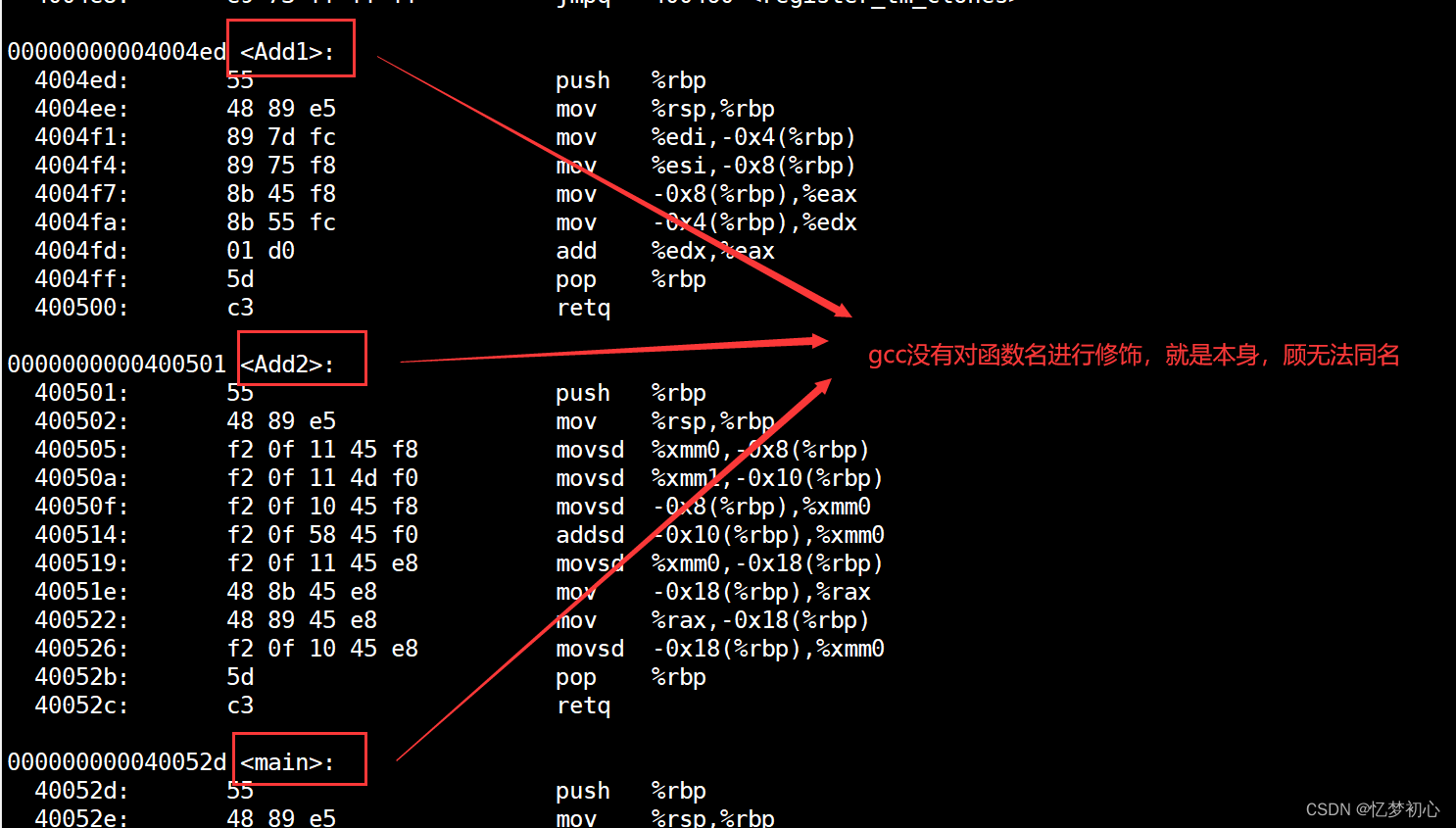
不同的编译器下的函数名修饰规则可能有所不同,由于VS的函数名修饰规则过于复杂,下面我们采用linux下的g++来进行演示
源代码清单
int Add(int x,int y){ return x + y;}double Add(double x,double y){ return x + y;}int main(){ return 0;}
采用gcc编译(C语言)
为了正确进行编译,将第一个Add函数改为Add1,第二个改为Add2。编译后查看汇编代码如下:

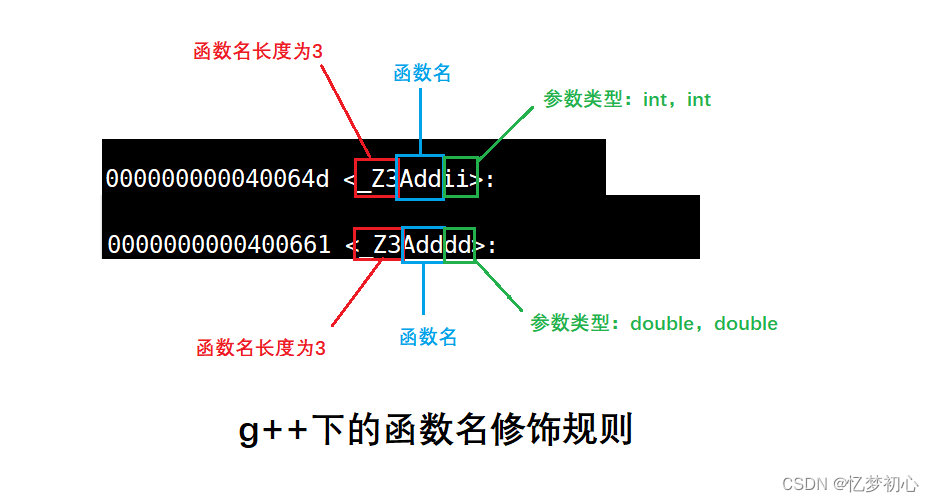
采用g++编译(C++)


Linux系统下的g++编译器将函数修饰后变成【_Z+函数长度+函数名+类型首字母】的形式,形参的个数、顺序以及类型不同都会使得修饰后的函数名不同
总结提炼
- 在linux下,采用GCc编译完成后,函数名字没有发生改变。
- 在linux下,采用g++编译完成后,函数名字的修饰发生改变,编译器将函数参数类型信息添加到修改后的名字中。
- C语言没办法支持重载是因为同名函数没办法区分。而C++是通过函数修饰规则来区分,只要参数不同,修饰出来的名字就不一样,顾支持重载。
- 如果两个函数仅仅是返回值不同是不构成重载的,因为调用时编译器没办法区分。
以上,就是本期的全部内容啦🌸
制作不易,能否点个赞再走呢🙏
来源地址:https://blog.csdn.net/m0_69909682/article/details/131893377
--结束END--
本文标题: 【C++深入浅出】初识C++上篇(关键字,命名空间,输入输出,缺省参数,函数重载)
本文链接: https://lsjlt.com/news/390756.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0