Python 官方文档:入门教程 => 点击学习
专栏导读 专栏订阅地址:https://blog.csdn.net/qq_35831906/category_12375510.html 1 数据库基础知识介绍 1.1 什么是数据库? 数据库是一个结构化存储

专栏订阅地址:https://blog.csdn.net/qq_35831906/category_12375510.html


数据库是一个结构化存储和组织数据的集合,它可以被有效地访问、管理和更新。数据库的目的是为了提供一种可靠的方式来存储和管理大量的数据,以便用户和应用程序可以方便地进行数据操作、查询和分析。
数据库管理系统(Database Management System,简称DBMS)是一个软件系统,它允许用户创建、访问和管理数据库。DBMS负责处理数据库的各种操作,如数据的存储、检索、更新和删除,同时也提供了一种安全的方式来管理数据的访问权限和完整性。DBMS还可以提供查询语言,允许用户使用特定的语法查询数据库中的数据。
一些常见的DBMS包括:
- Mysql
- postgresql
- oracle Database
- Microsoft SQL Server
- sqlite
关系型数据库(Relational Database)是一种以表格形式组织数据的数据库。它使用结构化查询语言(Structured Query Language,SQL)来管理和查询数据。关系型数据库中的数据以行和列的形式存储,每个表格(也称为关系)都具有固定的列和数据类型。
优点:
- 数据之间的关系明确,容易理解。
- 支持复杂的查询,例如多表连接。
- 具备数据一致性和完整性。
缺点:
- 不够适用于存储大量非结构化数据,如文本、图像等。
- 在大规模的数据集上可能性能较低。
常见的关系型数据库包括mysql、PostgreSQL、Oracle等。
非关系型数据库(NoSQL Database)是一类不使用传统关系型表格结构来存储数据的数据库。它们适用于需要处理大规模非结构化数据或需要更高的可扩展性和灵活性的场景。
非关系型数据库分为多个子类,包括:
优点:
缺点:
- 数据模型和查询语言通常比较特定,学习和使用成本较高。
- 不同类型的非关系型数据库之间差异较大,选择合适的数据库需要根据具体情况。
总结: 数据库是用于存储和管理数据的结构化集合,数据库管理系统(DBMS)是用于操作和管理数据库的软件系统。关系型数据库和非关系型数据库是两种不同类型的数据库模型,各自适用于不同的数据存储和处理需求。
Python中有多个数据库操作库可供选择,用于连接、操作和管理各种类型的数据库。以下是一些常见的Python数据库操作库的概述:
SQLite3是一个嵌入式关系型数据库引擎,无需独立的服务器即可使用。它是Python标准库的一部分,适用于小型项目和原型开发。
主要特点:
- 轻量级,无需额外配置。
- 存储在单个文件中,适用于单用户和小规模应用。
- 支持事务和多用户访问。
MySQL Connector/Python是官方提供的用于连接MySQL数据库的库。它提供了高性能的连接和数据操作功能。
主要特点:
- 官方支持,提供广泛的功能和兼容性。
- 支持连接池、事务管理和批量操作。
- 适用于中小型应用和大规模项目。
Psycopg2是用于连接和操作PostgreSQL数据库的库。它提供了高度的性能和灵活性。
主要特点:
- 支持高级的PostgreSQL功能,如数据类型、查询优化等。
- 提供连接池、事务管理和异步查询支持。
- 适用于复杂的数据处理和大规模应用。
SQLAlchemy是一个全功能的SQL工具包和对象关系映射(ORM)库,它允许你通过Python对象来操作数据库,抽象了底层的数据库细节。
主要特点:
- 支持多种数据库后端,包括SQLite、MySQL、PostgreSQL等。
- 提供ORM支持,允许使用Python对象来表示数据库表和关系。
- 支持灵活的查询、连接池和事务管理。
Peewee是一个简单、小巧的Python ORM库,适用于小型和中小型项目。
主要特点:
- 简洁易用,学习曲线较低。
- 支持SQLite、MySQL、PostgreSQL等多种数据库。
- 提供数据模型定义、查询、事务管理等功能。
除了ORM功能,SQLAlchemy还提供了"SQLAlchemy Core",这是一组用于执行SQL语句和管理数据库连接的工具。
主要特点:
- 提供底层的SQL表达和查询语言。
- 支持连接池、事务管理等。
- 适用于需要更精细控制数据库操作的场景。
这只是一些常见的Python数据库操作库的概述。选择适合你项目需求的库取决于项目的规模、性能要求和开发人员的熟悉程度。无论选择哪个库,了解其文档和示例是掌握数据库操作的关键。
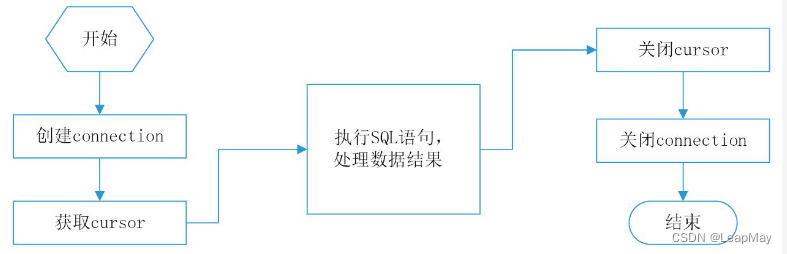
Python操作数据库的通用流程通常包括以下步骤:
导入数据库库:首先,你需要导入适用于所选数据库的库。不同的数据库类型需要不同的库,如SQLite、MySQL、PostgreSQL等。
建立数据库连接:使用库提供的方法建立与数据库的连接。这通常需要提供数据库的地址、用户名、密码和数据库名等信息。
创建游标对象:通过数据库连接,创建一个游标对象,它将用于执行SQL语句和处理查询结果。
执行SQL语句:使用游标对象执行各种SQL操作,如SELECT、INSERT、UPDATE、DELETE等。你可以在这里使用SQL查询语句,也可以使用库提供的方法进行数据操作。
处理查询结果:如果执行了SELECT查询,你可以使用游标对象来获取查询结果。结果通常以元组、列表、字典或自定义对象的形式返回。
提交事务(可选):如果进行了修改操作(INSERT、UPDATE、DELETE等),需要提交事务以保存更改。对于大多数库,修改操作默认是在事务中进行的,但你可以手动提交或回滚事务。
关闭游标和连接:在完成数据库操作后,务必关闭游标和连接,以释放资源并确保安全关闭连接。
下面是一个通用的Python数据库操作流程,以SQLite3库示例:
import sqlite3# 1. 导入数据库库# 2. 建立数据库连接conn = sqlite3.connect('mydatabase.db')# 3. 创建游标对象cursor = conn.cursor()# 4. 执行SQL语句cursor.execute("SELECT * FROM users")# 5. 处理查询结果rows = cursor.fetchall()for row in rows: print(row)# 6. 提交事务(如果有修改操作)conn.commit()# 7. 关闭游标和连接cursor.close()conn.close()这个通用流程在不同的数据库库中基本保持一致,只是具体的方法和用法可能会有些不同。在实际应用中,你可以根据选择的数据库库和项目需求,对流程进行适当的调整
SQLite3是一个嵌入式的轻量级关系型数据库引擎,适用于小型项目或原型开发。它是Python标准库的一部分,无需额外安装。
示例:
import sqlite3# 连接到SQLite数据库conn = sqlite3.connect('mydatabase.db')cursor = conn.cursor()# 创建表cursor.execute('''CREATE TABLE users (id INTEGER PRIMARY KEY, name TEXT)''')# 插入数据cursor.execute("INSERT INTO users (name) VALUES ('Alice')")conn.commit()# 查询数据cursor.execute("SELECT * FROM users")rows = cursor.fetchall()for row in rows: print(row)# 关闭连接conn.close()MySQL Connector/Python是官方提供的用于连接MySQL数据库的库。
import mysql.connector# 连接到MySQL数据库conn = mysql.connector.connect( host="localhost", user="username", passWord="password", database="mydatabase")cursor = conn.cursor()# 执行SQL语句cursor.execute("SELECT * FROM users")rows = cursor.fetchall()for row in rows: print(row)# 关闭连接conn.close()Psycopg2是用于连接和操作PostgreSQL数据库的库。
示例:
import psycopg2# 连接到PostgreSQL数据库conn = psycopg2.connect( host="localhost", user="username", password="password", database="mydatabase")cursor = conn.cursor()# 执行SQL语句cursor.execute("SELECT * FROM employees")rows = cursor.fetchall()for row in rows: print(row)# 关闭连接conn.close()SQLAlchemy是一个SQL工具包和对象关系映射(ORM)库,提供了更高层次的抽象来处理数据库操作。它支持多种数据库后端。
示例:
from sqlalchemy import create_engine, Column, Integer, Stringfrom sqlalchemy.orm import sessionmakerfrom sqlalchemy.ext.declarative import declarative_base# 创建数据库连接引擎engine = create_engine('sqlite:///mydatabase.db', echo=True)Base = declarative_base()# 定义数据模型class User(Base): __tablename__ = 'users' id = Column(Integer, primary_key=True) name = Column(String)# 创建数据表Base.metadata.create_all(engine)# 创建会话Session = sessionmaker(bind=engine)session = Session()# 插入数据user = User(name='Alice')session.add(user)session.commit()# 查询数据users = session.query(User).all()for user in users: print(user.id, user.name)# 关闭会话session.close()下节介绍数据库连接配置。
来源地址:https://blog.csdn.net/qq_35831906/article/details/132182538
--结束END--
本文标题: 【100天精通python】Day30:使用python操作数据库_数据库基础入门
本文链接: https://lsjlt.com/news/387571.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0