一、为啥要分库分表 在大型互联网系统中,大部分都会选择Mysql作为业务数据存储。一般来说,mysql单表行数超过500万行或者单表容量超过2GB,查询效率就会随着数据量的增长而下降。这个时候,就需要对表进行拆分。 那么应该怎么拆分呢? 通
在大型互联网系统中,大部分都会选择Mysql作为业务数据存储。一般来说,mysql单表行数超过500万行或者单表容量超过2GB,查询效率就会随着数据量的增长而下降。这个时候,就需要对表进行拆分。
那么应该怎么拆分呢?
通常有两种拆分方法,垂直拆分和水平拆分。
先说垂直拆分,这个比较简单,我们可以把原先的一张表根据业务属性拆分成多张表。比如用户表user有很多字段,我们可以新建一张用户属性表user_profile,把一些不常用的字段都拆分到user_profile表里,再用user_id作为外键将两张表关联起来就可以了。
再说水平拆分,水平拆分针对的不是表,而是数据。比如订单表,数据量一般都会非常大。我们可以创建多个数据库实例,每个实例上创建多张订单表,把订单数据相对均匀的分散存储到这些表里。查询的时候,根据分表策略可直接定位到数据在哪个表里,可以大大提高查询效率。
下面讲到的都是如何水平拆分。
分库分表已经有一些成熟的解决方案,本文是用ShardingSphere-JDBC框架来实现的。
ShardingSphere-JDBC定义为轻量级Java框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
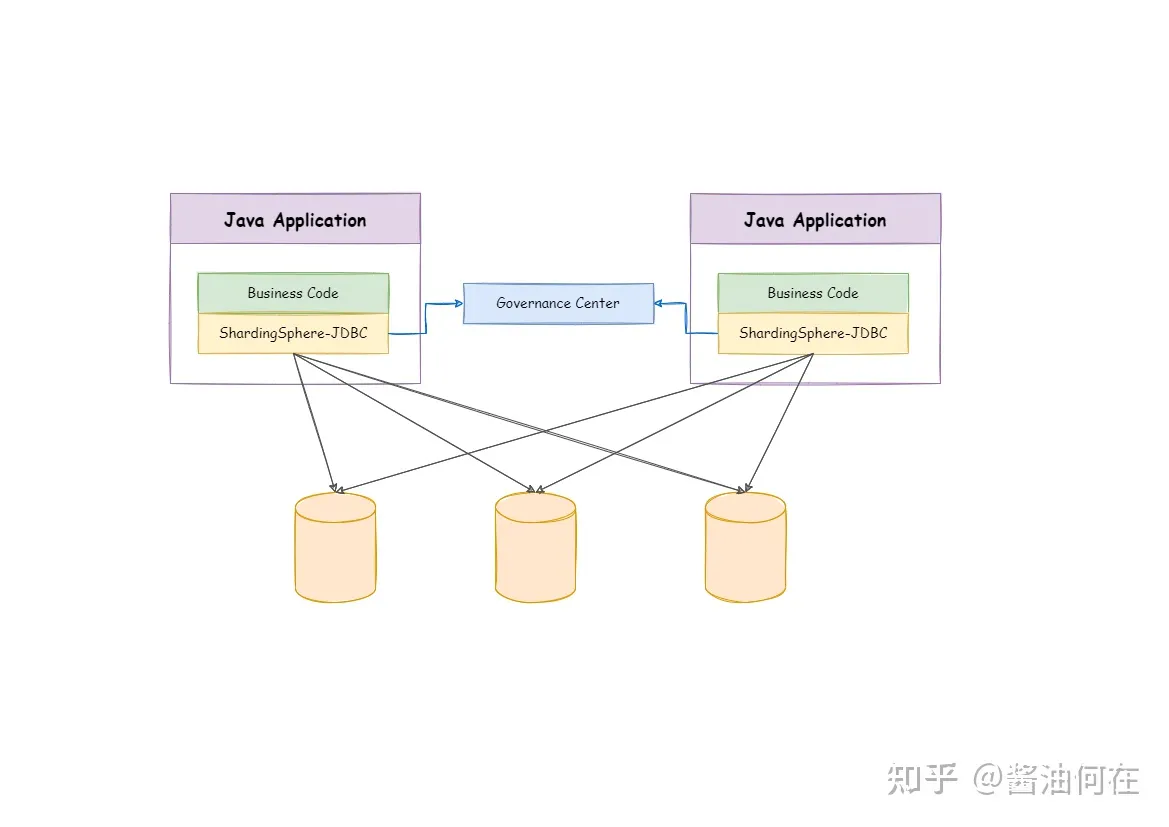
更多详细内容可直接参考:ShardingSphere官方文档
ShardingSphere-JDBC分库和分表配置类似,下面介绍下分表怎么实现。
(1)先建分表
先在mysql数据库建10张用户表:tb_user_0到9,建表语句如下,改下表名,执行10遍即可:
CREATE TABLE `tb_user_0` ( `id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键', `name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '姓名', `sex` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '性别', PRIMARY KEY (`id`) USING BTREE) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;(2)POM依赖
使用Spring Boot + mybatis-plus + shardingsphere-jdbc来实现,pom主要引入的包配置如下:
com.baomidou mybatis-plus-boot-starter 3.3.1 mysql mysql-connector-java runtime org.apache.shardingsphere shardingsphere-jdbc-core-spring-boot-starter 5.0.0 (3)实体类和Mapper代码
注意,实体类和Mapper只有一个就行,注意这里的tableName注解一定要和后面配置分表策略的逻辑名一致,不然无法匹配路由策略。
@TableName(value = "tb_user")public class User implements Serializable { private static final long serialVersionUID = 1L; @TableId(value = "id", type = IdType.AUTO) private Long id; @TableField(value = "name") private String name; @TableField(value = "sex") private String sex; public Long getId() { return id; } public void setId(Long id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getSex() { return sex; } public void setSex(String sex) { this.sex = sex; } @Override public String toString() { return "User{" + "id=" + id + ", name=" + name + ", sex=" + sex + "}"; }}public interface UserMapper extends BaseMapper {} (4)配置数据源和分表规则
我们引入的包是shardingsphere-jdbc-core-spring-boot-starter,直接在application.yml里配置数据源和分表规则就行。
spring: shardingsphere: datasource: # 数据源名称,有几个数据源就写几个,如果是分表,就会写多个 names: db0 # 为每个数据源单独配置,注意这里要跟上面写的名称一致 db0: # 数据库连接池实现类型,这里使用的是Hikari type: com.zaxxer.hikari.HikariDataSource # 数据库驱动类,连接地址,用户名,密码等 driver-class-name: com.mysql.cj.jdbc.Driver jdbc-url: jdbc:mysql://localhost:3306/sharding?useUnicode=true&characterEncoding=utf8&useSSL=false username: root password: 123456 rules: sharding: tables: # 分表的表名,程序中对这张表的操作,都会采用下面的路由方案 tb_user: # 这里是实际的数据节点信息,要把库名和表名都写全,这里也支持使用表达式,比如下面这张$->{0..9} actual-data-nodes: db0.tb_user_$->{0..9} # 配置分表策略 table-strategy: # 这里选择的标准策略,也可以配置复杂策略,或者也可以用代码来实现 standard: # 分片字段,这里是用用户id作为分片字段 sharding-column: id # 这里是我们自定义的分片算法名称,后面会有实现方案 sharding-algorithm-name: user-inline # 主键生成策略 key-generate-strategy: # 生成主键算法的名称 key-generator-name: snowflake # 主键字段 column: id # 自定义的主键算法 key-generators: snowflake: # 使用雪花算法生成主键 type: SNOWFLAKE # 自定义的分表算法 sharding-algorithms: user-inline: #使用inline类型实现 type: inline props: #分片表达式,用id对10取模,然后分散到10个表中 algorithm-expression: tb_user_$->{id % 10} props: # 打印日志,方便我们观察执行的sql语句 sql-show: true(5)写单测
先测试插入语句,如下插入100条数据:
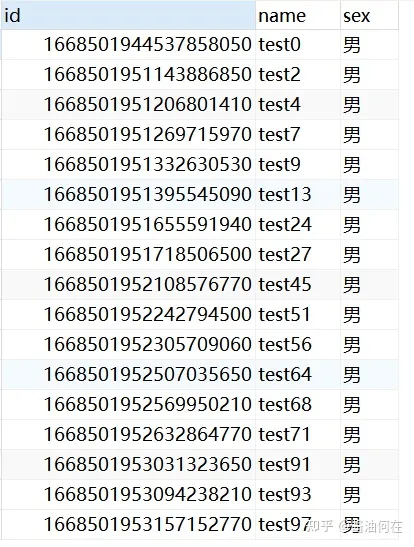
@Autowired private UserMapper userMapper; @Test public void insertTest() { for (int i=0; i<100; i++) { User user = new User(); user.setName("test" + i); user.setSex("男"); userMapper.insert(user); } }执行之后,发现每张表都有数据插入,但是分布并不均匀,这是由雪花算法特性导致的。下图是tb_user_0表的数据:
再测试下查询语句,先测试用id查询:
@Test public void selectByIdTest() { userMapper.selectById(1668501944537858050L); }查询sql语句如下图,从图中可以看出,根据id查询的时候,会自动走分表路由策略,查询id为1668501944537858050L的数据,会自动去tb_user_table_0中查找。

再测试一下根据name字段查询:
@Test public void selectByNameTest() { QueryWrapper qy = new QueryWrapper<>(); qy.eq("name","test1"); userMapper.selectList(qy); } 查询sql语句如下图,从图中可以看出,如果不是根据分表字段来查询的话,会自动uNIOn所有分表查询,这样反而效率会更低。
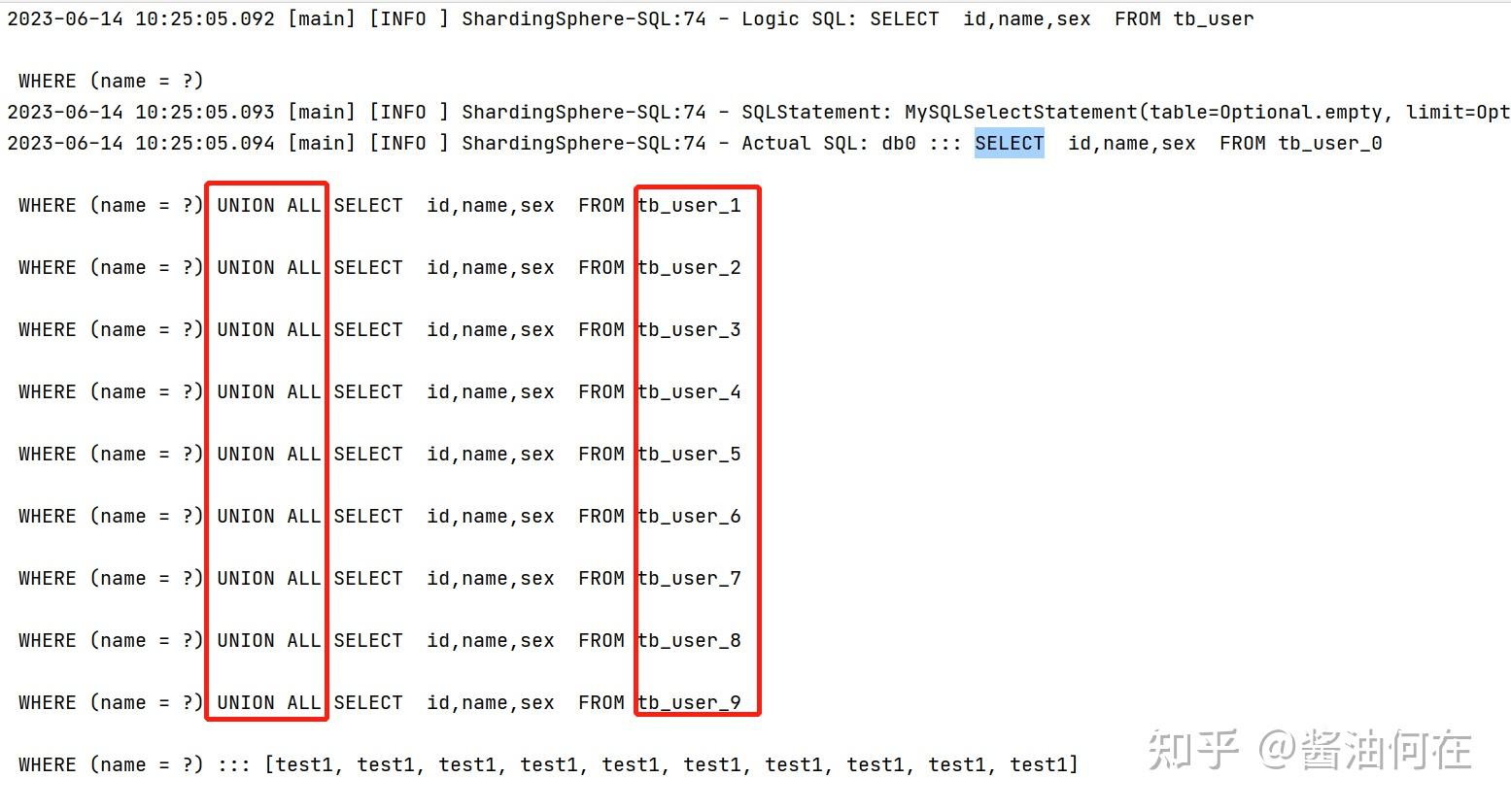
所以,分库分表时一定要选择合适的字段,并且查询的时候尽量要在查询条件里先指定分库分表的字段,这样可以直接定位到表中,提高查询效率。
ShardingSphere-JDBC可支持多种分片算法,比如标准分片,复合分片等,每种分片算法有多种类型,如行表达式INLINE,时间范围分片INTERVAL等,上面的例子我们就是用的标准分片行表达式做的。对于一些需要自定义的分片算法,我们可以通过自定义分片算法类来实现。
比如我们还是要实现取模算法,可以自定义一个UserShardingAlGorithm类来实现StandardShardingAlgorithm接口,实现doSharding接口来自定义分片算法,代码如下:
//分片字段数据类型是什么,这里泛型就写什么public class UserShardingAlgorithm implements StandardShardingAlgorithm { //精确分片算法实现,collection是实际表,也就是配置文件里的actual-data-nodes内容 //preciseShardingValue对象包括逻辑表名,分表算法的字段和字段值 @Override public String doSharding(Collection collection, PreciseShardingValue preciseShardingValue) { //对分片字段也就是用户id取模 String suffix = String.valueOf(preciseShardingValue.getValue() % 10); //遍历表名,找到符合要求的表,返回即可 for (String tableName : collection) { if (tableName.endsWith(suffix)) { return tableName; } } throw new UnsupportedOperationException(); } //范围分片,我们暂不支持 @Override public Collection doSharding(Collection collection, RangeShardingValue rangeShardingValue) { throw new UnsupportedOperationException(); } //初始化信息接口 @Override public void init() { } //分片算法类型 @Override public String getType() { return "USER_SHARDING"; }} 在配置文件里,我们只需要改一下分片算法部分的配置即可,之前的配置是这样的:
sharding-algorithms: user-inline: type: inline props: algorithm-expression: tb_user_$->{id % 10}分片类型改成class_based,也就是自定义类分片算法,配置如下:
sharding-algorithms: user-inline: type: class_based # 自定义类分片算法类型 props: strategy: standard # 自定义算法类的路径 algorithmClassName: com.GitHub.learn.sharding.algorithm.UserShardingAlgorithm还是再跑一下上面selectById单测,如下图,可以顺利去tb_user_0中查询数据,证明我们自定义的分片算法生效了:

ShardingSphere-JDBC提供了两种内置的分布式主键生成器,uuid和雪花算法。
uuid:采用UUID.randomUUID()的方式产生分布式主键。
雪花算法:
雪花算法是由 Twitter 公布的分布式主键生成算法,它能够保证不同进程主键的不重复性,以及相同进程主键的有序性。
(1)实现原理
在同一个进程中,它首先是通过时间位保证不重复,如果时间相同则是通过序列位保证。 同时由于时间位是单调递增的,且各个服务器如果大体做了时间同步,那么生成的主键在分布式环境可以认为是总体有序的,这就保证了对索引字段的插入的高效性。 例如 MySQL 的 Innodb 存储引擎的主键。
使用雪花算法生成的主键,二进制表示形式包含 4 部分,从高位到低位分表为:1bit 符号位、41bit 时间戳位、10bit 工作进程位以及 12bit 序列号位。
预留的符号位,恒为零。
41 位的时间戳可以容纳的毫秒数是 2 的 41 次幂,一年所使用的毫秒数是:365 * 24 * 60 * 60 * 1000。 通过计算可知:
Math.pow(2,41)/(365*24*60*60*1000L);结果约等于 69.73 年。 Apache ShardingSphere 的雪花算法的时间纪元从 2016年11月1日 零点开始,可以使用到 2086 年,相信能满足绝大部分系统的要求。
该标志在 Java 进程内是唯一的,如果是分布式应用部署应保证每个工作进程的 id 是不同的。 该值默认为 0,可通过属性设置。
该序列是用来在同一个毫秒内生成不同的 ID。如果在这个毫秒内生成的数量超过 4096 (2 的 12 次幂),那么生成器会等待到下个毫秒继续生成。
雪花算法主键的详细结构见下图。

(2)配置信息
在ShardingSphere-JDBC中,雪花算法提供了三个属性。
worker-id:工作机器唯一标识
max-vibration-offset:最大抖动上限值,范围[0, 4096)。注:若使用此算法生成值作分片值,建议配置此属性。此算法在不同毫秒内所生成的 key 取模 2^n (2^n一般为分库或分表数) 之后结果总为 0 或 1。为防止上述分片问题,建议将此属性值配置为 (2^n)-1。如果有10个分表,可将此值设置为9,这样数据分布会更均匀一下。
max-tolerate-time-difference-milliseconds:最大容忍时钟回退时间,单位:毫秒,默认10毫秒
(3)多节点worker-id配置
服务器可能是有多个节点的,此时如果worker-id用同一个配置,有可能会产生重复的id,因此每个节点的worker-id最好是不同的。我们可以用ip地址的一部分来作为节点的worker-id,worker-id是十位,我们直接取ip地址的后10位即可,一般都是不会重复的。比如机器的IP为192.168.1.108,二进制表示:11000000 10101000 00000001 01101100,截取最后10位 01 01101100,转为十进制364,设置workerId为364。
实现方式如下:
首先是配置文件,要加入work-id属性配置:
key-generators: user-id-generator: type: SNOWFLAKE props: max-vibration-offset: 9 worker-id: ${workerId}然后,加一个配置类,在static代码块中获取ip地址,取后十位,作为worker-id。
@Configurationpublic class WorkerIdConfig { private static final Logger LOGGER = LoggerFactory.getLogger(WorkerIdConfig.class); static { try { InetAddress address = InetAddress.getLocalHost(); // IP地址byte[]数组形式,这个byte数组的长度是4,数组0~3下标对应的值分别是192,168,1,108 byte[] ipAddressByteArray = address.getAddress(); // workerId取ip地址后十位 long workerId = ((ipAddressByteArray[ipAddressByteArray.length - 2] & 0x03) << 8) + (ipAddressByteArray[ipAddressByteArray.length - 1] & 0xFF); LOGGER.info("当前机器 workerId: {}", workerId); System.setProperty("workerId", String.valueOf(workerId)); } catch (Exception e) { LOGGER.error("worker id failed:{}", e.getMessage(), e); } }}来源地址:https://blog.csdn.net/Kevin_zhai/article/details/131416610
--结束END--
本文标题: Java如何实现分库分表
本文链接: https://lsjlt.com/news/384567.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-04-01
2024-04-03
2024-04-03
2024-01-21
2024-01-21
2024-01-21
2024-01-21
2023-12-23
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0