起因:最近在工作中接到了一个大文件上传下载的需求,要求将文件上传到share盘中,下载的时候根据前端传的不同条件对单个或多个文件进行打包并设置目录下载。 一开始我想着就还是用老办法直接file.transferTo(newFile)就算是大
起因:最近在工作中接到了一个大文件上传下载的需求,要求将文件上传到share盘中,下载的时候根据前端传的不同条件对单个或多个文件进行打包并设置目录下载。
一开始我想着就还是用老办法直接file.transferTo(newFile)就算是大文件,我只要慢慢等总会传上去的。
(原谅我的无知。。)后来尝试之后发现真的是异想天开了,如果直接用普通的上传方式基本上就会遇到以下4个问题:
所以我只能寻求切片上传的帮助了。
前端根据代码中设置好的分片大小将上传的文件切成若干个小文件,分多次请求依次上传,后端再将文件碎片拼接为一个完整的文件,即使某个碎片上传失败,也不会影响其它文件碎片,只需要重新上传失败的部分就可以了。而且多个请求一起发送文件,提高了传输速度的上限。
(前端切片的核心是利用 Blob.prototype.slice 方法,和数组的 slice 方法相似,文件的 slice 方法可以返回原文件的某个切片)
接下来就是上代码!
前端代码
DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta Http-equiv="X-UA-Compatible" content="IE=edge" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <script src="https://cdn.jsdelivr.net/npm/Vue@2.6/dist/vue.min.js">script> <link rel="stylesheet" href="https://unpkg.com/element-ui/lib/theme-chalk/index.CSS"> <script src="https://unpkg.com/element-ui/lib/index.js">script> <title>分片上传测试title>head><body> <div id="app"> <template> <div> <input type="file" @change="handleFileChange" /> <el-button @click="handleUpload">上传el-button> div> template> div>body>html><script> // 切片大小 // the chunk size const SIZE = 50 * 1024 * 1024; var app = new Vue({ el: '#app', data: { container: { file: null }, data: [], fileListLong: '', fileSize:'' }, methods: { handleFileChange(e) { const [file] = e.target.files; if (!file) return; this.fileSize = file.size; Object.assign(this.$data, this.$options.data()); this.container.file = file; }, async handleUpload() { }, // 生成文件切片 createFileChunk(file, size = SIZE) { const fileChunkList = []; let cur = 0; while (cur < file.size) { fileChunkList.push({ file: file.slice(cur, cur + size) }); cur += size; } return fileChunkList; }, // 上传切片 async uploadChunks() { const requestList = this.data .map(({ chunk, hash }) => { const fORMData = new FormData(); formData.append("file", chunk); formData.append("hash", hash); formData.append("filename", this.container.file.name); return { formData }; }) .map(({ formData }) => this.request({url: "http://localhost:8080/file/upload",data: formData }) ); // 并发请求 await Promise.all(requestList); console.log(requestList.size); this.fileListLong = requestList.length; // 合并切片 await this.mergeRequest(); }, async mergeRequest() { await this.request({ url: "http://localhost:8080/file/merge", headers: { "content-type": "application/JSON" }, data: JSON.stringify({ fileSize: this.fileSize, fileNum: this.fileListLong, filename: this.container.file.name }) }); }, async handleUpload() { if (!this.container.file) return; const fileChunkList = this.createFileChunk(this.container.file); this.data = fileChunkList.map(({ file }, index) => ({ chunk: file, // 文件名 + 数组下标 hash: this.container.file.name + "-" + index })); await this.uploadChunks(); }, request({ url, method = "post", data, headers = {}, requestList }) { return new Promise(resolve => { const xhr = new XMLHttpRequest(); xhr.open(method, url); Object.keys(headers).forEach(key => xhr.setRequestHeader(key, headers[key]) ); xhr.send(data); xhr.onload = e => { resolve({data: e.target.response }); }; }); } } });script>考虑到方便和通用性,这里没有用第三方的请求库,而是用原生 XMLHttpRequest 做一层简单的封装来发请求
当点击上传按钮时,会调用 createFileChunk 将文件切片,切片数量通过文件大小控制,这里设置 50MB,也就是说一个 100 MB 的文件会被分成 2 个 50MB 的切片
createFileChunk 内使用 while 循环和 slice 方法将切片放入 fileChunkList 数组中返回
在生成文件切片时,需要给每个切片一个标识作为 hash,这里暂时使用文件名 + 下标,这样后端可以知道当前切片是第几个切片,用于之后的合并切片
随后调用 uploadChunks 上传所有的文件切片,将文件切片,切片 hash,以及文件名放入 formData中,再调用上一步的 request 函数返回一个 proimise,最后调用 Promise.all 并发上传所有的切片
后端代码
实体类
@Datapublic class FileUploadReq implements Serializable { private static final long serialVersionUID = 4248002065970982984L; //切片的文件 private MultipartFile file; //切片的文件名称 private String hash; //原文件名称 private String filename;}@Datapublic class FileMergeReq implements Serializable { private static final long serialVersionUID = 3667667671957596931L;//文件名 private String filename;//切片数量 private int fileNum;//文件大小 private String fileSize;}@Slf4j@CrossOrigin@RestController@RequestMapping("/file")public class FileController { final String folderPath = System.getProperty("user.dir") + "/src/main/resources/static/file"; @RequestMapping(value = "upload", method = RequestMethod.POST) public Object upload(FileUploadReq fileUploadEntity) { File temporaryFolder = new File(folderPath); File temporaryFile = new File(folderPath + "/" + fileUploadEntity.getHash()); //如果文件夹不存在则创建 if (!temporaryFolder.exists()) { temporaryFolder.mkdirs(); } //如果文件存在则删除 if (temporaryFile.exists()) { temporaryFile.delete(); } MultipartFile file = fileUploadEntity.getFile(); try { file.transferTo(temporaryFile); } catch (IOException e) { log.error(e.getMessage()); e.printStackTrace(); } return "success"; } @RequestMapping(value = "/merge", method = RequestMethod.POST) public Object merge(@RequestBody FileMergeReq fileMergeEntity) { String finalFilename = fileMergeEntity.getFilename(); File folder = new File(folderPath); //获取暂存切片文件的文件夹中的所有文件 File[] files = folder.listFiles(); //合并的文件 File finalFile = new File(folderPath + "/" + finalFilename); String finalFileMainName = finalFilename.split("\\.")[0]; InputStream inputStream = null; OutputStream outputStream = null; try { outputStream = new FileOutputStream(finalFile, true); List<File> list = new ArrayList<>(); for (File file : files) { String filename = FileNameUtil.mainName(file); //判断是否是所需要的切片文件 if (StringUtils.equals(filename, finalFileMainName)) { list.add(file); } } //如果服务器上的切片数量和前端给的数量不匹配 if (fileMergeEntity.getFileNum() != list.size()) { return "文件缺失,请重新上传"; } //根据切片文件的下标进行排序 List<File> fileListCollect = list.parallelStream().sorted(((file1, file2) -> { String filename1 = FileNameUtil.extName(file1); String filename2 = FileNameUtil.extName(file2); return filename1.compareTo(filename2); })).collect(Collectors.toList()); //根据排序的顺序依次将文件合并到新的文件中 for (File file : fileListCollect) { inputStream = new FileInputStream(file); int temp = 0; byte[] byt = new byte[2 * 1024 * 1024]; while ((temp = inputStream.read(byt)) != -1) { outputStream.write(byt, 0, temp); } outputStream.flush(); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); }finally { try { if (inputStream != null){ inputStream.close(); } } catch (IOException e) { e.printStackTrace(); } try { if (outputStream != null){ outputStream.close(); } } catch (IOException e) { e.printStackTrace(); } } // 产生的文件大小和前端一开始上传的文件不一致 if (finalFile.length() != Long.parseLong(fileMergeEntity.getFileSize())) { return "上传文件大小不一致"; } return "上传成功"; }}为了图方便我就直接return 字符串了 嘿嘿(当然我在这个demo里面写了方法统一结果的封装,所以输出的时候还是restful风格的结果,详细内容可以看我之前的文章《spring使用aop完成统一结果封装》)
当前端调用upload接口的时候,后端就会将前端传过来的文件放到一个临时文件夹中
当调用merge接口的时候,后端就会认为分片文件已经全部上传完毕就会进行文件合并的工作
后端主要是根据前端返回的hash值来判断分片文件的顺序
其实分片上传听起来好像很麻烦,其实只要把思路捋清楚了其实是不难的,是一个比较简单的需求。
当然这个只是一个比较简单一个demo,只是实现的一个较为简单的分片上传功能,像断点上传,上传暂停这些功能暂时还没来得及写到demo里面,之后有时间了会新开一个文章写这些额外的内容。
大文件上传中断:假如我们有一个5G的文件,上传过程中突然中断我们该怎么办?上文件上传响应时间长:假如我们有个10G的文件,单次上传时间长,用户体验长,该怎么办?大文件上传重复上传:某些大文件,我们已经上传过了,我们不想再一次上传,该怎么办?如下图,我们会将一个大文件进行切片,然后调用文件上传接口,将分片base64数据、源文件名称、分片大小、分片个数、索引号传到服务器上。
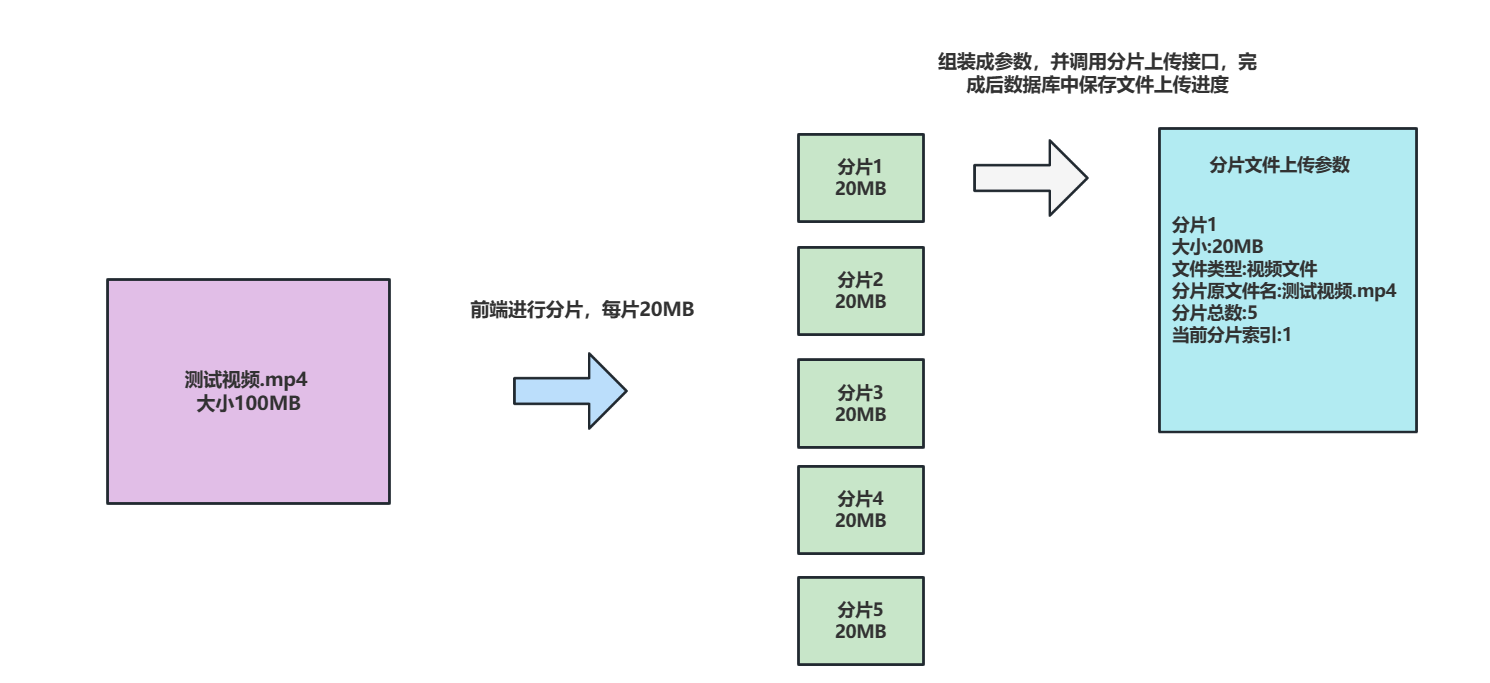
为了保存分片上传进度,笔者创建了下面这样一张表,这张表记录了上传的文件以及文件分片上传的进度。
当我们上传的分片是第一个分片时,我们就会插入一条数据,记录文件名、分片索引号等信息。
后续上传成功的分片则都是更新信息shard_index这个字段。
DROP TABLE IF EXISTS `file`;CREATE TABLE `file` ( `id` char(8) NOT NULL DEFAULT '' COMMENT 'id', `path` varchar(100) NOT NULL COMMENT '相对路径', `name` varchar(100) DEFAULT NULL COMMENT '文件名', `suffix` varchar(10) DEFAULT NULL COMMENT '后缀', `size` int(11) DEFAULT NULL COMMENT '大小|字节B', `use` char(1) DEFAULT NULL COMMENT '用途|枚举[FileUseEnum]:COURSE("C", "讲师"), TEACHER("T", "课程")', `created_at` datetime(3) DEFAULT NULL COMMENT '创建时间', `updated_at` datetime(3) DEFAULT NULL COMMENT '修改时间', `shard_index` int(11) DEFAULT NULL COMMENT '已上传分片', `shard_size` int(11) DEFAULT NULL COMMENT '分片大小|B', `shard_total` int(11) DEFAULT NULL COMMENT '分片总数', `key` varchar(32) DEFAULT NULL COMMENT '文件标识', PRIMARY KEY (`id`), UNIQUE KEY `path_unique` (`path`), UNIQUE KEY `key_unique` (`key`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='文件';注意,以下参数都是必传参数:
name:文件名称(包含文件后缀)。shard:文件base64值。size:文件总大小。shardTotal:文件总分片数。shardSize:每个分片最大值,注意这里笔者说的分片最大值,原因很简单,如果我们文件分片大小。为10M,很可能最后一个分片大小不足10M,所以这个参数传的就是切割分片后的最大值。suffix:文件后缀,视频后缀为mp4,图片则为jpg等。base64值,并转为MultipartFile。MultipartFile写到这个路径中。在进行分片上传逻辑编写前,我们必须配置一下本地存储路径和映射地址,如下所示,笔者将file.path设置为本地文件存储路径。将file.domain设置为file.path对外的映射地址。
file.path=F:/video/file.domain=http://127.0.0.1:9000/file/f/为了做到这一点,笔者创建了一个springMVCConfig 配置,这样以来,我们在浏览器中键入http://127.0.0.1:9000/file/f/1.jpg就相当于访问文件服务器的F:/video/1.jpg
@Configurationpublic class SpringmvcConfig implements WEBMvcConfigurer { @Value("${file.path}") private String FILE_PATH; @Override public void addResourceHandlers(ResourceHandlerReGIStry registry) { registry.addResourceHandler("/f public void save(FileDto fileDto) { File file = CopyUtil.copy(fileDto, File.class); File fileDb = selectByKey(fileDto.geTKEy()); if (fileDb == null) { this.insert(file); } else { fileDb.setShardIndex(fileDto.getShardIndex()); this.update(fileDb); } }如果当前上传的分片为最后一个分片,则进行文件合并
//判断当前分片索引是否等于分片总数,如果等于分片总数则执行文件合并 if (fileDto.getShardIndex().equals(fileDto.getShardTotal())) { fileDto.setPath(fileFullPath); //文件合并 merge(fileDto); }组装结果并返回
ResponseDto responseDto = new ResponseDto(); FileDto result = new FileDto(); //设置文件映射地址给前端 result.setPath(FILE_DOMAIN + "/" + relaPath); responseDto.setContent(result); logger.info("文件分片上传结束,请求结果:{}", JSON.toJSONString(responseDto)); return responseDto;文件合并逻辑,这里就比较简单了,创建输入流和输出流,以追加的形式将每个分片都写到输出文件中。
private void merge(FileDto fileDto) { logger.info("文件分片合并开始,请求参数:{}", JSON.toJSONString(fileDto)); String path = fileDto.getPath(); try (OutputStream outputStream = new FileOutputStream(path, true)) { for (Integer i = 1; i <= fileDto.getShardTotal(); i++) { try (FileInputStream inputStream = new FileInputStream(path + "." + i);) { byte[] bytes = new byte[10 * 1024 * 1024]; int len; while ((len = inputStream.read(bytes)) != -1) { outputStream.write(bytes, 0, len); } } } } catch (Exception e) { logger.error("文件合并失败,失败原因:{}", e.getMessage(), e); } //删除所有分片 for (Integer i = 1; i <= fileDto.getShardTotal(); i++) { File file = new File(path + "." + i); file.delete(); } }完整代码
@RequestMapping("/upload") public ResponseDto uploadShard(@RequestBody FileDto fileDto) throws Exception { logger.info("文件分片上传请求开始,请求参数: {}", JSON.toJSONString(fileDto)); //1. 参数非空检查 checkParams(fileDto); //将base64转MultipartFile MultipartFile multipartFile = Base64ToMultipartFile.base64ToMultipart(fileDto.getShard()); //获取本地文件夹地址,拼接传入的参数use,得到一个本地文件夹路径,并判断是否存在,若不存在则直接创建 String localDirPath = FILE_PATH + FileUseEnum.getByCode(fileDto.getUse()); logger.info("本地文件夹地址:{}", localDirPath); File dirFile = new File(localDirPath); //如果目标文件夹不存在,则直接创建一个 if (!dirFile.exists() && !dirFile.mkdirs()) { logger.error("文件夹创建失败,待创建路径:{}", localDirPath); throw new Exception("文件夹创建失败,创建路径:" + localDirPath); } //本地文件全路径 String fileFullPath = localDirPath + File.separator + fileDto.getKey() + "." + fileDto.getSuffix(); //创建文件分片全路径,将multipartFile写入到这个路径中 String fileShardFullPath = fileFullPath + "." + fileDto.getShardIndex(); multipartFile.transferTo(new File(fileShardFullPath)); //更新文件表信息,无上传过这个文件则插入一条,反之直接更新索引值 String relaPath = FileUseEnum.getByCode(fileDto.getUse()) + "/" + fileDto.getKey() + "." + fileDto.getSuffix(); fileDto.setPath(relaPath); fileService.save(fileDto); //判断当前分片索引是否等于分片总数,如果等于分片总数则执行文件合并 if (fileDto.getShardIndex().equals(fileDto.getShardTotal())) { fileDto.setPath(fileFullPath); //文件合并 merge(fileDto); } ResponseDto responseDto = new ResponseDto(); FileDto result = new FileDto(); //设置文件映射地址给前端 result.setPath(FILE_DOMAIN + "/" + relaPath); responseDto.setContent(result); logger.info("文件分片上传结束,请求结果:{}", JSON.toJSONString(responseDto)); return responseDto; } private void merge(FileDto fileDto) { logger.info("文件分片合并开始,请求参数:{}", JSON.toJSONString(fileDto)); String path = fileDto.getPath(); try (OutputStream outputStream = new FileOutputStream(path, true)) { for (Integer i = 1; i <= fileDto.getShardTotal(); i++) { try (FileInputStream inputStream = new FileInputStream(path + "." + i);) { byte[] bytes = new byte[10 * 1024 * 1024]; int len; while ((len = inputStream.read(bytes)) != -1) { outputStream.write(bytes, 0, len); } } } } catch (Exception e) { logger.error("文件合并失败,失败原因:{}", e.getMessage(), e); } //删除所有分片 for (Integer i = 1; i <= fileDto.getShardTotal(); i++) { File file = new File(path + "." + i); file.delete(); } }因为是大文件,我们很可能文件传一半就因为各种原因导致中断,我们的实现思路是和前端约定好为系统的文件都生成一个key,后端用这个key到数据库中查询是否存在上传记录。
如果有结果则结果返回给前端。
然后前端进行如下操作:
索引值+1完成断点续传。 @GetMapping("/check/{key}") public ResponseDto check(@PathVariable String key) { logger.info("文件上传进度检查接口请求开始,请求参数:{}", key); if (StringUtils.isEmpty(key)) { throw new BusinessException(BusinessExceptionCode.ILLEGAL_ARGUMENT_EXCEPTION); } FileDto fileDto = fileService.findByKey(key); ResponseDto responseDto = new ResponseDto(); //如果不为空,则返回映射地址以及文件上传进度 if (fileDto != null) { //将文件映射地址告知前端 fileDto.setPath(FILE_DOMAIN + "/" + fileDto.getPath()); responseDto.setContent(fileDto); } return responseDto; }前端文件分片计算代码逻辑(ps:笔者基于Vue写的)
getFileShard (shardIndex, shardSize) { let _this = this; let file = _this.$refs.file.files[0]; let start = (shardIndex - 1) * shardSize;//当前分片起始位置 let end = Math.min(file.size, start + shardSize); //当前分片结束位置 let fileShard = file.slice(start, end); //从文件中截取当前的分片数据 return fileShard; },调用极速妙传和断点续传的逻辑
check (param) { let _this = this; _this.$ajax.get(process.env.VUE_APP_SERVER + '/file/admin/check/' + param.key).then((response)=>{ let resp = response.data; if (resp.success) { let obj = resp.content; //如果不存在则从第一个分片开始上传 if (!obj) {param.shardIndex = 1;console.log("没有找到文件记录,从分片1开始上传");_this.upload(param); } else if (obj.shardIndex === obj.shardTotal) {// 已上传分片 = 分片总数,说明已全部上传完,不需要再上传Toast.success("文件极速秒传成功!");_this.afterUpload(resp);$("#" + _this.inputId + "-input").val(""); } else {param.shardIndex = obj.shardIndex + 1;console.log("找到文件记录,从分片" + param.shardIndex + "开始上传");_this.upload(param); } } else { Toast.warning("文件上传失败"); $("#" + _this.inputId + "-input").val(""); } }) }, upload (param) { let _this = this; let shardIndex = param.shardIndex; let shardTotal = param.shardTotal; let shardSize = param.shardSize; let fileShard = _this.getFileShard(shardIndex, shardSize); // 将图片转为base64进行传输 let fileReader = new FileReader(); Progress.show(parseInt((shardIndex - 1) * 100 / shardTotal)); fileReader.onload = function (e) { let base64 = e.target.result; // console.log("base64:", base64); param.shard = base64; _this.$ajax.post(process.env.VUE_APP_SERVER + '/file/admin/upload', param).then((response) => { let resp = response.data; console.log("上传文件成功:", resp); Progress.show(parseInt(shardIndex * 100 / shardTotal)); if (shardIndex < shardTotal) {// 上传下一个分片param.shardIndex = param.shardIndex + 1;_this.upload(param); } else {Progress.hide();_this.afterUpload(resp);$("#" + _this.inputId + "-input").val(""); } }); }; fileReader.readAsDataURL(fileShard); },答: 这个是Spring框架自带的一个类,便于用户更好操作网络传输的文件,这个类为我们提供了很多便捷操作的api。
getName():获取文件名getOriginalFilename():返回客户端系统中原始文件名。getContentType():获取文件内容类型。isEmpty():判断文件是否为空。getSize():获取文件大小,以字节为单位。getBytes():获取文件的字节数组。getInputStream():获取文件输入流。transferTo(File dest):将目标文件传输到目标文件中。transferTo(Path dest) :将目标文件传输到目标地址中。以笔者为例,笔者为了将前端传入的base64字符串转为MultipartFile,于是继承了MultipartFile编写了一个工具类
这个类首先声明两个成员属性,imGContent记录文件内容,header记录base64文件标识。
private final byte[] imgContent; private final String header;获取文件名以及获取文件类型等相关方法的重写
@Override public String getName() { // TODO - implementation depends on your requirements return System.currentTimeMillis() + Math.random() + "." + header.split("/")[1]; } @Override public String getOriginalFilename() { // TODO - implementation depends on your requirements return System.currentTimeMillis() + (int) Math.random() * 10000 + "." + header.split("/")[1]; }@Override public String getContentType() { // TODO - implementation depends on your requirements return header.split(":")[1]; }重点:base64转MultipartFile 逻辑,如下所示,将base64封号后面的内容转为数组b ,然后将这个数据赋给imgContent,文件描述信息赋给header。
public static MultipartFile base64ToMultipart(String base64) { try { String[] baseStrs = base64.split(","); BASE64Decoder decoder = new BASE64Decoder(); byte[] b = null; b = decoder.decodeBuffer(baseStrs[1]); for(int i = 0; i < b.length; ++i) { if (b[i] < 0) { b[i] += 256; } }//将文件内容赋值给imgContent,文件描述信息baseStrs[0]赋给header return new Base64ToMultipartFile(b, baseStrs[0]); } catch (IOException e) { e.printStackTrace(); return null; } } public Base64ToMultipartFile(byte[] imgContent, String header) { this.imgContent = imgContent; this.header = header.split(";")[0]; }答: base64是为了在网络传输中避免中文乱码、媒体文件二进制传输数据不可打印等情况诞生的一种编码技术。它的编码过程也很简单,就是将每个字符串的二进制编码值全部合在一起,每6位算一个字符,再配合base64编码表得出最终结果。
base64编码表
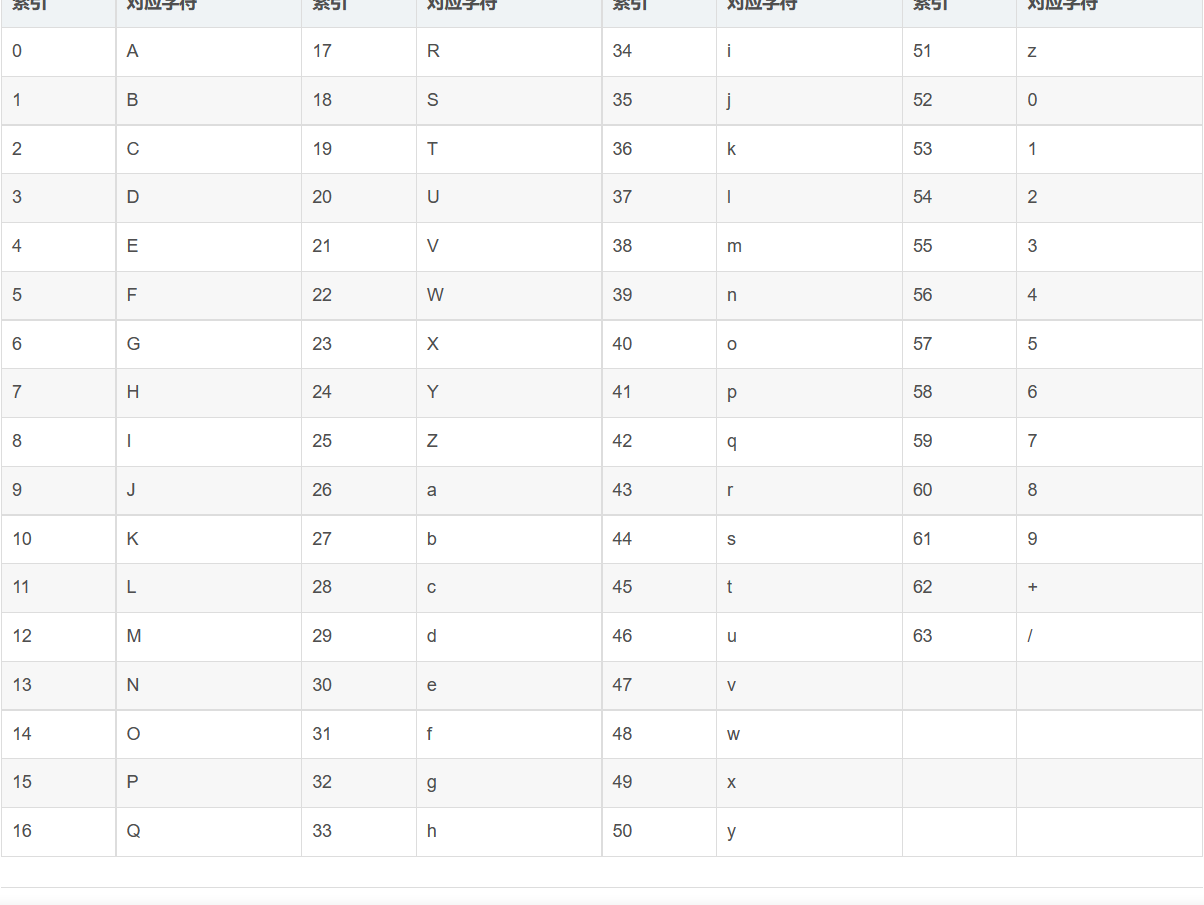
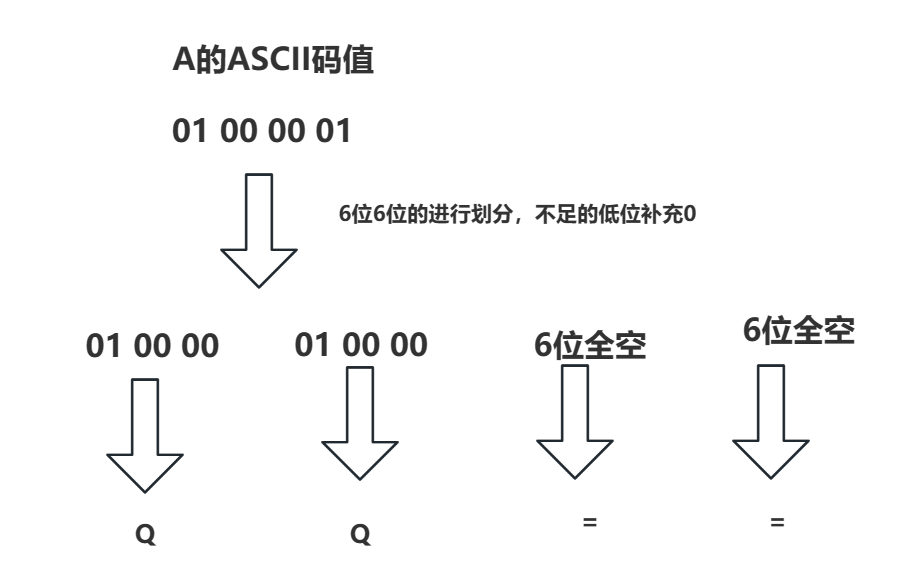
我们就以字符串A为例子,它的ASCII码值为65,那么二进制数值就为:1000001,按照base64的规则,将字符串中24位为一组(不足24位则算做空位)。所以A的二进制值为01 00 00 01 00 00 后12位全空,每6位算出一个十进制的值,根据base64编码表得出最终的值,01 00 00 得到一个Q,01 00 00又得到一个Q,后面全空的6位算一个=,最终结果为QQ==。
为了让读者加深对base64编码的理解,我们再以字符串Man为例,我们得出它的ASCII码值为77 97 110
它的计算过程如下图所示

对此我们可以用Java代码来验证一下
public static void main(String[] args) { String man = "Man"; String a = "A"; BASE64Encoder encoder = new BASE64Encoder(); System.out.println("Man base64结果为:" + encoder.encode(man.getBytes())); System.out.println("A base64结果为:" + encoder.encode(a.getBytes())); }输出结果
Man base64结果为:TWFuA base64结果为:QQ==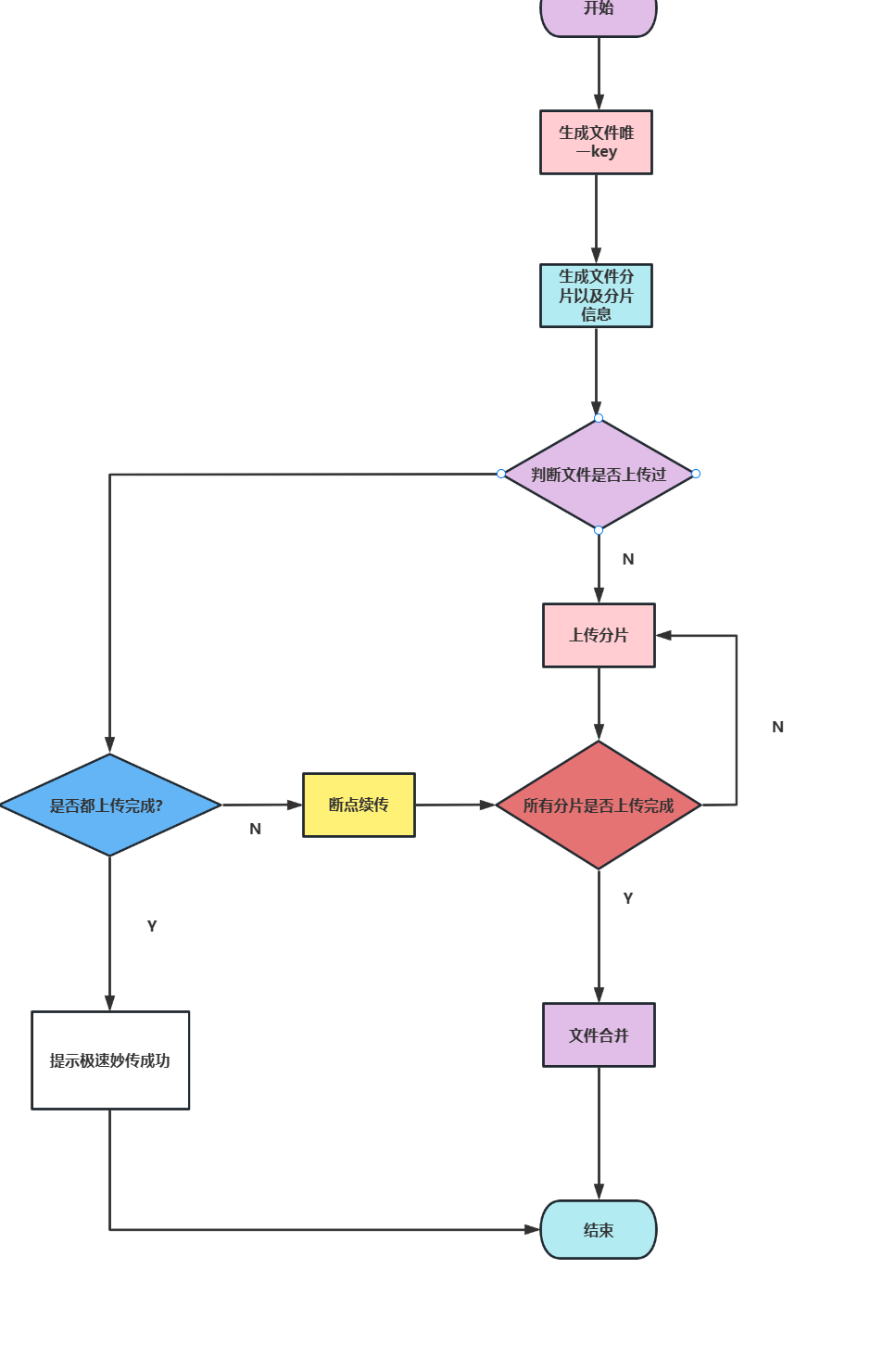
答: 有的,某些场景下我们的项目会使用Amazon S3,相比自建文件服务器,减少了很多运维压力,而且Amazon S3也为我们提供了multipart upload API,最大支持上传5TB的文件。
为了保证扩展,我们也留了一个策略类实现Amazon S3的文件上传。
答: 我们某个系统需要调用另一个服务的rpc接口进行文件上传,由于某些文件属于大文件,所以经常出现文件上传途中导致文件超时等问题,对此我们采用了文件分片上传的方案解决问题超时问题。
buffer缓冲区。Async注解。可以的,并发的逻辑交给前端实现,但是后端的表结构可能需要修改,还记得我们之前有一张专门记录文件分片上传进度的数据表嘛,建表sql如下所示:
DROP TABLE IF EXISTS `file`;CREATE TABLE `file` ( `id` char(8) NOT NULL DEFAULT '' COMMENT 'id', `path` varchar(100) NOT NULL COMMENT '相对路径', `name` varchar(100) DEFAULT NULL COMMENT '文件名', `suffix` varchar(10) DEFAULT NULL COMMENT '后缀', `size` int(11) DEFAULT NULL COMMENT '大小|字节B', `use` char(1) DEFAULT NULL COMMENT '用途|枚举[FileUseEnum]:COURSE("C", "讲师"), TEACHER("T", "课程")', `created_at` datetime(3) DEFAULT NULL COMMENT '创建时间', `updated_at` datetime(3) DEFAULT NULL COMMENT '修改时间', `shard_index` int(11) DEFAULT NULL COMMENT '已上传分片', `shard_size` int(11) DEFAULT NULL COMMENT '分片大小|B', `shard_total` int(11) DEFAULT NULL COMMENT '分片总数', `key` varchar(32) DEFAULT NULL COMMENT '文件标识', PRIMARY KEY (`id`), UNIQUE KEY `path_unique` (`path`), UNIQUE KEY `key_unique` (`key`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='文件';如果需要并发shard_index就不能代表当前已上传的分片数了,取而代之的是我们必须为这个文件上传完成的每一个分片进行日志记录。所以我们可以建立下面这样一张表。
可以看到我们用file表的id和这张表进行关联,每一个分片上传完成后就将分片索引号插入到这张表中。
DROP TABLE IF EXISTS `file_shard`;CREATE TABLE `file_shard` ( `id` char(8) NOT NULL DEFAULT '' COMMENT 'id', `shard_index` int(11) DEFAULT NULL COMMENT '分片索引' PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='文件分片';同步的我们合并的逻辑也得修改。
//从file_shard获取已上传完成的分片数List<Integer> indexList=fileShradServive.selectById(fileDto.getId()) //如果分片表的数据数和file表的total一样则可以合并 if (indexList.size().equals(fileDto.getShardTotal())) { fileDto.setPath(fileFullPath); //文件合并 merge(fileDto); }断点续传同理,需要遍历file_shard表的分片索引,for循环看看缺哪个分片就把哪个分片返回给前端
List<Integer> indexList=fileShradServive.selectById(fileDto.getId())//记录未上传的分片List<Integer> unfinishUploadShardList=new ArrayList<>();//分片索引排序 Collections.sort(indexList); //记录未上传的分片 List<Integer> unfinishUploadShardList = new ArrayList<>(); for (int i = 0; i < indexList.size(); i++) { if (!indexList.contains(i)) { unfinishUploadShardList.add(i); } }来源地址:https://blog.csdn.net/qq_43842093/article/details/129233462
--结束END--
本文标题: Java实现文件分片上传
本文链接: https://lsjlt.com/news/374619.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-04-01
2024-04-03
2024-04-03
2024-01-21
2024-01-21
2024-01-21
2024-01-21
2023-12-23
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0