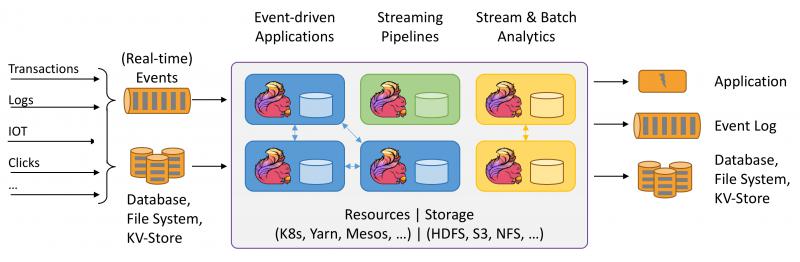
Apache flink Apache Flink 是一个兼顾高吞吐、低延迟、高性能的分布式处理框架。在实时计算崛起的今天,Flink正在飞速发展。由于性能的优势和兼顾批处理,流处理的特性,Flink可能正在颠覆整个大数据的生态

Apache Flink 是一个兼顾高吞吐、低延迟、高性能的分布式处理框架。在实时计算崛起的今天,Flink正在飞速发展。由于性能的优势和兼顾批处理,流处理的特性,Flink可能正在颠覆整个大数据的生态。
首先要想运行Flink,我们需要下载并解压Flink的二进制包,下载地址如下:https://flink.apache.org/downloads.html
我们可以选择Flink与Scala结合版本,这里我们选择最新的1.9版本Apache Flink 1.9.0 for Scala 2.12进行下载。
下载成功后,在windows系统中可以通过Windows的bat文件或者Cygwin来运行Flink。
请参考:Flink入门(三)——环境与部署
Flink的编程模型,Flink提供了不同的抽象级别以开发流式或者批处理应用,本文我们来介绍DataSet API ,Flink最常用的批处理编程模型。
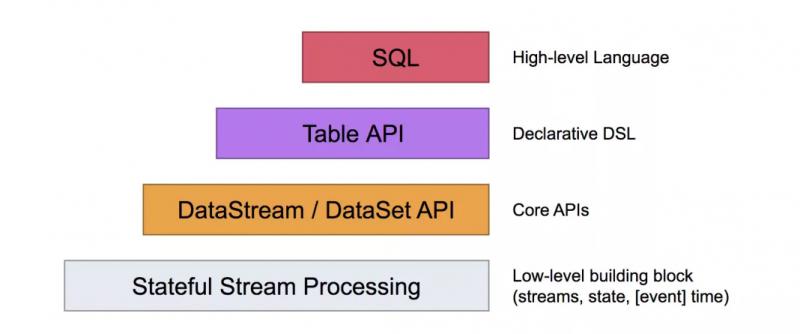
Flink中的DataSet程序是实现数据集转换的常规程序(例如,Filter,映射,连接,分组)。数据集最初是从某些来源创建的(例如,通过读取文件或从本地集合创建)。结果通过接收器返回,接收器可以例如将数据写入(分布式)文件或标准输出(例如命令行终端)。Flink程序可以在各种环境中运行,独立运行或嵌入其他程序中。执行可以在本地JVM中执行,也可以在许多计算机的集群上执行。
示例程序
以下程序是WordCount的完整工作示例。您可以复制并粘贴代码以在本地运行它。
Java
public class WordCountExample {
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet text = env.fromElements(
"Who's there?",
"I think I hear them. Stand, ho! Who's there?");
DataSet> wordCounts = text
.flatMap(new LineSplitter())
.groupBy(0)
.sum(1);
wordCounts.print();
}
public static class LineSplitter implements FlatMapFunction> {
@Override
public void flatMap(String line, Collector> out) {
for (String word : line.split(" ")) {
out.collect(new Tuple2(word, 1));
}
}
}
} Scala
import org.apache.flink.api.scala._
object WordCount {
def main(args: Array[String]) {
val env = ExecutionEnvironment.getExecutionEnvironment
val text = env.fromElements(
"Who's there?",
"I think I hear them. Stand, ho! Who's there?")
val counts = text.flatMap { _.toLowerCase.split("\W+") filter { _.nonEmpty } }
.map { (_, 1) }
.groupBy(0)
.sum(1)
counts.print()
}
}数据转换将一个或多个DataSet转换为新的DataSet。程序可以将多个转换组合到复杂的程序集中。
DataSet API 中最重要的就是这些算子,我们将数据接入后,通过这些算子对数据进行处理,得到我们想要的结果。
Java版算子如下:
| 转换 | 描述 |
|---|---|
| Map | 采用一个数据元并生成一个数据元。data.map(new MapFunction |
| FlatMap | 采用一个数据元并生成零个,一个或多个数据元。data.flatMap(new FlatMapFunction |
| MapPartition | 在单个函数调用中转换并行分区。该函数将分区作为Iterable流来获取,并且可以生成任意数量的结果值。每个分区中的数据元数量取决于并行度和先前的 算子操作。data.mapPartition(new MapPartitionFunction |
| Filter | 计算每个数据元的布尔函数,并保存函数返回true的数据元。 重要信息:系统假定该函数不会修改应用谓词的数据元。违反此假设可能会导致错误的结果。data.filter(new FilterFunction |
| Reduce | 通过将两个数据元重复组合成一个数据元,将一组数据元组合成一个数据元。Reduce可以应用于完整数据集或分组数据集。data.reduce(new ReduceFunction如果将reduce应用于分组数据集,则可以通过提供CombineHintto 来指定运行时执行reduce的组合阶段的方式 setCombineHint。在大多数情况下,基于散列的策略应该更快,特别是如果不同键的数量与输入数据元的数量相比较小(例如1/10)。 |
| ReduceGroup | 将一组数据元组合成一个或多个数据元。ReduceGroup可以应用于完整数据集或分组数据集。data.reduceGroup(new GroupReduceFunction |
| Aggregate | 将一组值聚合为单个值。聚合函数可以被认为是内置的reduce函数。聚合可以应用于完整数据集或分组数据集。Dataset您还可以使用简写语法进行最小,最大和总和聚合。Dataset |
| Distinct | 返回数据集的不同数据元。它相对于数据元的所有字段或字段子集从输入DataSet中删除重复条目。data.distinct();使用reduce函数实现Distinct。您可以通过提供CombineHintto 来指定运行时执行reduce的组合阶段的方式 setCombineHint。在大多数情况下,基于散列的策略应该更快,特别是如果不同键的数量与输入数据元的数量相比较小(例如1/10)。 |
| Join | 通过创建在其键上相等的所有数据元对来连接两个数据集。可选地使用JoinFunction将数据元对转换为单个数据元,或使用FlatJoinFunction将数据元对转换为任意多个(包括无)数据元。请参阅键部分以了解如何定义连接键。result = input1.join(input2) .where(0) // key of the first input (tuple field 0) .equalTo(1); // key of the second input (tuple field 1)您可以通过Join Hints指定运行时执行连接的方式。提示描述了通过分区或广播进行连接,以及它是使用基于排序还是基于散列的算法。有关可能的提示和示例的列表,请参阅“ 转换指南”。 如果未指定提示,系统将尝试估算输入大小,并根据这些估计选择最佳策略。// This executes a join by broadcasting the first data set // using a hash table for the broadcast data result = input1.join(input2, JoinHint.BROADCAST_HASH_FIRST) .where(0).equalTo(1);请注意,连接转换仅适用于等连接。其他连接类型需要使用OuterJoin或CoGroup表示。 |
| OuterJoin | 在两个数据集上执行左,右或全外连接。外连接类似于常规(内部)连接,并创建在其键上相等的所有数据元对。此外,如果在另一侧没有找到匹配的Keys,则保存“外部”侧(左侧,右侧或两者都满)的记录。匹配数据元对(或一个数据元和null另一个输入的值)被赋予JoinFunction以将数据元对转换为单个数据元,或者转换为FlatJoinFunction以将数据元对转换为任意多个(包括无)数据元。请参阅键部分以了解如何定义连接键。input1.leftOuterJoin(input2) // rightOuterJoin or fullOuterJoin for right or full outer joins .where(0) // key of the first input (tuple field 0) .equalTo(1) // key of the second input (tuple field 1) .with(new JoinFunction |
| CoGroup | reduce 算子操作的二维变体。将一个或多个字段上的每个输入分组,然后关联组。每对组调用转换函数。请参阅keys部分以了解如何定义coGroup键。data1.coGroup(data2) .where(0) .equalTo(1) .with(new CoGroupFunction |
| Cross | 构建两个输入的笛卡尔积(交叉乘积),创建所有数据元对。可选择使用CrossFunction将数据元对转换为单个数据元DataSet注:交叉是一个潜在的非常计算密集型 算子操作它甚至可以挑战大的计算集群!建议使用crossWithTiny()和crossWithHuge()来提示系统的DataSet大小。 |
| Union | 生成两个数据集的并集。DataSet |
| Rebalance | 均匀地Rebalance 数据集的并行分区以消除数据偏差。只有类似Map的转换可能会遵循Rebalance 转换。DataSet |
| Hash-Partition | 散列分区给定键上的数据集。键可以指定为位置键,表达键和键选择器函数。DataSet |
| Range-Partition | Range-Partition给定键上的数据集。键可以指定为位置键,表达键和键选择器函数。DataSet |
| Custom Partitioning | 手动指定数据分区。 注意:此方法仅适用于单个字段键。DataSet |
| Sort Partition | 本地按指定顺序对指定字段上的数据集的所有分区进行排序。可以将字段指定为元组位置或字段表达式。通过链接sortPartition()调用来完成对多个字段的排序。DataSet |
| First-n | 返回数据集的前n个(任意)数据元。First-n可以应用于常规数据集,分组数据集或分组排序数据集。分组键可以指定为键选择器函数或字段位置键。DataSet |
数据源创建初始数据集,例如来自文件或Java集合。创建数据集的一般机制是在InputFORMat后面抽象的 。Flink附带了几种内置格式,可以从通用文件格式创建数据集。他们中的许多人在ExecutionEnvironment上都有快捷方法。
基于文件的:
readTextFile(path)/ TextInputFormat- 按行读取文件并将其作为字符串返回。readTextFileWithValue(path)/ TextValueInputFormat- 按行读取文件并将它们作为StringValues返回。StringValues是可变字符串。readCsvFile(path)/ CsvInputFormat- 解析逗号(或其他字符)分隔字段的文件。返回元组或POJO的DataSet。支持基本java类型及其Value对应作为字段类型。readFileOfPrimitives(path, Class)/ PrimitiveInputFormat- 解析新行(或其他字符序列)分隔的原始数据类型(如String或)的文件Integer。readFileOfPrimitives(path, delimiter, Class)/ PrimitiveInputFormat- 解析新行(或其他字符序列)分隔的原始数据类型的文件,例如String或Integer使用给定的分隔符。readSequenceFile(Key, Value, path)/ SequenceFileInputFormat- 创建一个JobConf并从类型为SequenceFileInputFormat,Key class和Value类的指定路径中读取文件,并将它们作为Tuple2 基于集合:
fromCollection(Collection) - 从Java Java.util.Collection创建数据集。集合中的所有数据元必须属于同一类型。fromCollection(Iterator, Class) - 从迭代器创建数据集。该类指定迭代器返回的数据元的数据类型。fromElements(T ...) - 根据给定的对象序列创建数据集。所有对象必须属于同一类型。fromParallelCollection(SplittableIterator, Class) - 并行地从迭代器创建数据集。该类指定迭代器返回的数据元的数据类型。generateSequence(from, to) - 并行生成给定间隔中的数字序列。通用:
readFile(inputFormat, path)/ FileInputFormat- 接受文件输入格式。createInput(inputFormat)/ InputFormat- 接受通用输入格式。例子
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// read text file from local files system
DataSet localLines = env.readTextFile("file:///path/to/my/textfile");
// read text file from a hdfs running at nnHost:nnPort
DataSet hdfsLines = env.readTextFile("hdfs://nnHost:nnPort/path/to/my/textfile");
// read a CSV file with three fields
DataSet> csvInput = env.readCsvFile("hdfs:///the/CSV/file")
.types(Integer.class, String.class, Double.class);
// read a CSV file with five fields, taking only two of them
DataSet> csvInput = env.readCsvFile("hdfs:///the/CSV/file")
.includeFields("10010") // take the first and the fourth field
.types(String.class, Double.class);
// read a CSV file with three fields into a POJO (Person.class) with corresponding fields
DataSet> csvInput = env.readCsvFile("hdfs:///the/CSV/file")
.pojoType(Person.class, "name", "age", "zipcode");
// read a file from the specified path of type SequenceFileInputFormat
DataSet> tuples =
env.readSequenceFile(IntWritable.class, Text.class, "hdfs://nnHost:nnPort/path/to/file");
// creates a set from some given elements
DataSet value = env.fromElements("Foo", "bar", "foobar", "fubar");
// generate a number sequence
DataSet numbers = env.generateSequence(1, 10000000);
// Read data from a relational database using the JDBC input format
DataSet dbData =
env.createInput(
JDBCInputFormat.buildJDBCInputFormat()
.setDrivername("org.apache.derby.jdbc.EmbeddedDriver")
.setDBUrl("jdbc:derby:memory:persons")
.setQuery("select name, age from persons")
.setRowTypeInfo(new RowTypeInfo(BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.INT_TYPE_INFO))
.finish()
);
// Note: Flink's program compiler needs to infer the data types of the data items which are returned
// by an InputFormat. If this information cannot be automatically inferred, it is necessary to
// manually provide the type information as shown in the examples above. 通过创建输入文件和读取输出文件来完成分析程序的输入并检查其输出是很麻烦的。Flink具有特殊的数据源和接收器,由Java集合支持以简化测试。一旦程序经过测试,源和接收器可以很容易地被读取/写入外部数据存储(如HDFS)的源和接收器替换。
在开发中,我们经常直接使用接收器对数据源进行接收。
final ExecutionEnvironment env = ExecutionEnvironment.createLocalEnvironment();
// Create a DataSet from a list of elements
DataSet myInts = env.fromElements(1, 2, 3, 4, 5);
// Create a DataSet from any Java collection
List> data = ...
DataSet> myTuples = env.fromCollection(data);
// Create a DataSet from an Iterator
Iterator longit = ...
DataSet myLongs = env.fromCollection(longIt, Long.class); 除了常规的 算子操作输入之外,广播变量还允许您为 算子操作的所有并行实例提供数据集。这对于辅助数据集或与数据相关的参数化非常有用。然后,算子可以将数据集作为集合访问。
// 1. The DataSet to be broadcast
DataSet toBroadcast = env.fromElements(1, 2, 3);
DataSet data = env.fromElements("a", "b");
data.map(new RichMapFunction() {
@Override
public void open(Configuration parameters) throws Exception {
// 3. Access the broadcast DataSet as a Collection
Collection broadcastSet = getRuntimeContext().getBroadcastVariable("broadcastSetName");
}
@Override
public String map(String value) throws Exception {
...
}
}).withBroadcastSet(toBroadcast, "broadcastSetName"); // 2. Broadcast the DataSet Flink提供了一个分布式缓存,类似于Apache Hadoop,可以在本地访问用户函数的并行实例。此函数可用于共享包含静态外部数据的文件,如字典或机器学习的回归模型。
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// reGISter a file from HDFS
env.registerCachedFile("hdfs:///path/to/your/file", "hdfsFile")
// register a local executable file (script, executable, ...)
env.registerCachedFile("file:///path/to/exec/file", "localExecFile", true)
// define your program and execute
...
DataSet input = ...
DataSet result = input.map(new MyMapper());
...
env.execute(); 以上就是DataSet API 的使用,其实和spark非常的相似,我们将数据接入后,可以利用各种算子对数据进行处理。
Flink Demo代码
Flink系列文章:
Flink入门(一)——Apache Flink介绍
Flink入门(二)——Flink架构介绍
Flink入门(三)——环境与部署
Flink入门(四)——编程模型
更多实时计算,Flink,kafka等相关技术博文,欢迎关注实时流式计算

--结束END--
本文标题: Flink入门(五)——DataSet Api编程指南
本文链接: https://lsjlt.com/news/3654.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0