视图概述:– 从视图中创建、修改和检索数据– 在视图上的数据操纵语言(DML)操作– 删除视图数据库对象Object 对象Description 描述Table 表基本的数据存储集合,由行和列组
视图概述:
– 从视图中创建、修改和检索数据
– 在视图上的数据操纵语言(DML)操作
– 删除视图
数据库对象
| Object 对象 | Description 描述 |
| Table 表 | 基本的数据存储集合,由行和列组成。 |
| View 视图 | 从一张表或多张表中抽出的逻辑上相关的数据集合 |
| Sequence 序列 | 生成规律的数值 |
| Index 索引 | 提高查询性能 |
| Synonym 同义词 | 给对象起的别名 |
什么是视图?我的理解就是从一张表或多张表创建一个自定义的关联虚拟表
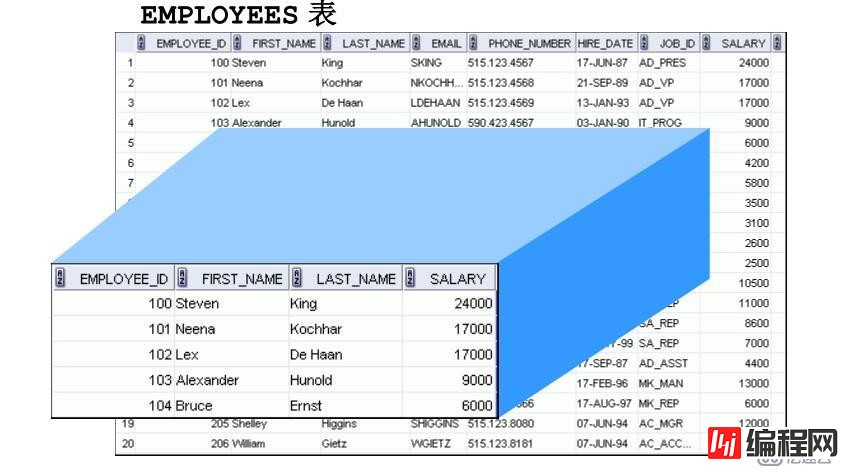
视图有如下几个优点:
限制数据访问
简化查询
数据独立性
避免重复访问相同的数据
简单视图和复杂视图
| 特点 | 简单视图 | 复杂视图 |
| 表的数量 | One | One or more |
| 包含函数 | No | Yes |
| 包含分组数据 | No | Yes |
| 通过视图做 DML 操作 | Yes | Not alway |
创建视图
CREATE VIEW 子句中嵌入子查询:
create [or replace] [force|noforce] view myview
[(alias[, alias]...)]
as subquery
[with check option [constraint constraint]]
[with read only [constraint constraint]];
子查询可以包含复杂的 SELECT 语法
With check option: 防止插入不可见的行,防止从视图中丢失的更新。
1、创建视图emp80,包含部门为80的员工详细信息:
create view emp80
as select employee_id, last_name, salary
from employees
where department_id = 80;
使用 sql*Plus 的 DESCRIBE 命令描述视图结构
desc emp80
2、在子查询中使用列别名创建视图:
create view salv50
as select employee_id id_number, last_name name,
salary*12 ann_salary
from employees
where department_id = 50;
在选择视图中的列时应使用别名
修改视图
使用CREATE OR REPLACE VIEW 子句修改EMPVU80视图。为每一列都增加别名:
create or replace view emp80
(id_number, name, sal, department_id)
as select employee_id, first_name || ' '
|| last_name, salary, department_id
from employees
where department_id = 80;
在 CREATE OR REPLACE VIEW 子句中列出来的别名要与子查询中各列相对应
创建复杂视图
创建一个包含组函数,从两张表中显示数据的复杂视图:
create or replace view dept_sum_vu
(name, minsal, maxsal, avgsal)
as select d.department_name, min(e.salary),
max(e.salary),avg(e.salary)
from employees e join departments d
on (e.department_id = d.department_id)
group by d.department_name;
视图上执行 DML 操作的规则-- DELETE
可以在简单视图上执行DML操作
当视图定义中包含以下元素之一时不能删除行
– 组函数
– GROUP BY 子句
– DISTINCT 关键字
– ROWNUM 伪列
视图上执行 DML 操作的规则-- UPDATE
当视图定义中包含以下元素之一时不能修改数据:
– 组函数
– GROUP BY 子句
– DISTINCT 关键字
– ROWNUM 伪列
– 表达式定义的列
视图上执行 DML 操作的规则-- INSERT
当视图定义中包含以下元素之一时不能插入数据:
– 组函数
– GROUP BY 子句
– DISTINCT 关键字
– ROWNUM 伪列
– 表达式定义的列
– 表中非空的列在视图定义中未包括
WITH CHECK OPTION 约束
使用 WITH CHECK OPTION 子句确保DML只能在特定的范围内执行:
create or replace view empvu20
as select *
from employees
where department_id = 20
with check option constraint empvu20_ck ;
任何违反WITH CHECK OPTION 约束的请求都会失败
屏蔽 DML 操作
可以使用 WITH READ ONLY 选项屏蔽对视图的DML 操作
任何 DML 操作都会返回一个oracle server 错误
create or replace view empvu10
(employee_number, employee_name, job_title)
as select employee_id, last_name, job_id
from employees
where department_id = 10
with read only;
删除视图
删除视图只是删除视图的定义,并不会删除基表的数据
drop view emp80;
drop view slav;
序列
自动提供唯一的数值
共享对象
主要用于提供主键值
可代替应用程序生成序号
将序列值缓存到内存中,可以提高访问效率
CREATE SEQUENCE 语法
定义一个序列自动生成连续的数字:
create sequence sequence
[increment by n]
[start with n]
[{maxvalue n | nomaxvalue}]
[{minvalue n | nominvalue}]
[{cycle | nocycle}]
[{cache n | nocache}];
创建序列 DEPT_DEPTID_SEQ 为表 DEPARTMENTS 提供主键。
不是用 CYCLE 选项
create sequence dept_deptid_seq
increment by 10
start with 120
maxvalue 9999
nocache
nocycle;
NEXTVAL 和 和 CURRVAL伪列
NEXTVAL 返回下一个可用的序列值。它返回一个唯一的值每次引用它的时候,任何用户都可以引用它
CURRVAL得到当前的序列值
使用 CURRVAL 之前必须发出 NEXTVAL
使用序列
插入一个新的部门为“Support” 位置ID为 2500
insert into departments(department_id,
department_name, location_id)
values (dept_deptid_seq.nextval,
'support', 2500);
序列 DEPT_DEPTID_SEQ 显示当前值
select dept_deptid_seq.currval from dual;
缓存序列值
将序列值缓存到内存中,可提高访问效率
序列在下列情况下出现“断号”:
– 发生回滚
– 系统崩溃
– 序列用于其他的表
可以修改序列的增量、最大值、最小值,循环选项或缓存:
alter sequence dept_deptid_seq
increment by 20
maxvalue 999999
nocache
nocycle;
修改序列的注意事项
必须是序列的拥有者或对序列有 ALTER 权限
只有将来的序列值会被改变
改变序列的初始值只能通过删除序列之后重建序列的方法实现
执行一些验证(例如,新的 MAXVALUE小于当前的序列号)
使用 DROP 语句删除序列:
drop sequence dept_deptid_seq;
索引:
是一个方案对象
通过指针加速 Oracle 服务器的查询速度
通过使用快速路径访问方法来快速定位数据,可以减少磁盘I/O
索引与表相互独立
Oracle 服务器自动使用和维护索引
创建索引:
自动创建:在定义 PRIMARY KEY 或 UNIQUE 约束后系统自动在相应的列上创建唯一性索引。
手动创建:用户可以在其它列上创建非唯一的索引,以加速查询。
在一列或多列上创建索引语法:
create [unique][bitmap]index index
on table (column[, column]...);
2、在表 EMPLOYEES的 LAST_NAME字段上创建索引,提高查询访问速度:
create index emp_last_name_idx on employees(last_name);
创建索引注意事项

删除索引
使用 DROP INDEX 命令,从数据字典中删除索引:
drop index index;
从数据字典中删除索引:emp_last_name_idx
drop index emp_last_name_idx;
删除索引,你必须是索引的拥有者或者拥有 DROP ANY INDEX 权限。
同义词
创建对象的同义词
通过创建同义词简化对象访问(一个对象的另一个名字),使用同义词您可以:
方便访问其它用户的对象
缩短对象名字的长度
创建同义词语法:
create [public] synonym synonym for object;
创建和删除同义词示例
1、为视图 DEPT_SUM_VU 创建一个较短名称的同义词:
create synonym d_sum for dept_sum_vu;
2、删除同义词
drop synonym d_sum;
--结束END--
本文标题: SQL 基础之创建其他方案对象(十五)
本文链接: https://lsjlt.com/news/35412.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0