本文小编为大家详细介绍“vue3调度器effect的scheduler功能怎么实现”,内容详细,步骤清晰,细节处理妥当,希望这篇“Vue3调度器effect的scheduler功能怎么实现”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入
本文小编为大家详细介绍“vue3调度器effect的scheduler功能怎么实现”,内容详细,步骤清晰,细节处理妥当,希望这篇“Vue3调度器effect的scheduler功能怎么实现”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。
说到scheduler,也就是vue3的调度器,可能大家还不是特别明白调度器的是什么,先大概介绍一下。
可调度性是响应式系统非常重要的特性。首先我们要明确什么是可调度性。所谓可调度性,指的是当trigger 动作触发副作用函数重新执行时,有能力决定副作用函数执行的时机、次数以及方式。
有了调度函数,我们在trigger函数中触发副作用函数重新执行时,就可以直接调用用户传递的调度器函数,从而把控制权交给用户。
举个栗子:
const obj = Reactive({ foo: 1 });effect(() => { console.log(obj.foo);})obj.foo++;obj.foo++;首先在副作用函数中打印obj.foo的值,接着连续对其执行两次自增操作,输出如下:
1
2
3
由输出结果可知,obj.foo的值一定会从1自增到3,2只是它的过渡状态。如果我们只关心最终结果而不关心过程,那么执行三次打印操作是多余的,我们期望的打印结果是:
1
3
那么就考虑传入调度器函数去帮助我们实现此功能,那由此需求,我们先来实现一下scheduler功能。
首先还是藉由单测来梳理一下功能,这是直接从vue3源码中粘贴过来对scheduler的单测,里面很详细的描述了scheduler的功能。
it('scheduler', () => { let dummy; let run: any; const scheduler = jest.fn(() => { run = runner; }); const obj = reactive({ foo: 1 }); const runner = effect( () => { dummy = obj.foo; }, { scheduler }, ); expect(scheduler).not.toHaveBeenCalled(); expect(dummy).toBe(1); // should be called on first trigger obj.foo++; expect(scheduler).toHaveBeenCalledTimes(1); // should not run yet expect(dummy).toBe(1); // manually run run(); // should have run expect(dummy).toBe(2);});大概介绍一下这个单测的流程:
通过 effect 的第二个参数给定的一个对象 { scheduler: () => {} }, 属性是scheduler, 值是一个函数;
effect 第一次执行的时候, 还是会执行 fn;
当响应式对象被 set,也就是数据 update 时, 如果 scheduler 存在, 则不会执行 fn, 而是执行 scheduler;
当再次执行 runner 的时候, 才会再次的执行 fn.
那接下来就直接开始代码实现功能,这里直接贴出完整代码了,// + 会标注出新增加的代码。
class ReactiveEffect { private _fn: any; // + 接收scheduler // + 在构造函数的参数上使用public等同于创建了同名的成员变量 constructor(fn, public scheduler?) { this._fn = fn; } run() { activeEffect = this; return this._fn(); }}// * ============================== ↓ 依赖收集 track ↓ ============================== * //// * targetMap: target -> keyconst targetMap = new WeakMap();// * target -> key -> depexport function track(target, key) { // * depsMap: key -> dep let depsMap = targetMap.get(target); if (!depsMap) { targetMap.set(target, (depsMap = new Map())); } // * dep let dep = depsMap.get(key); if (!dep) { depsMap.set(key, (dep = new Set())); } dep.add(activeEffect);}// * ============================== ↓ 触发依赖 trigger ↓ ============================== * //export function trigger(target, key) { let depsMap = targetMap.get(target); let dep = depsMap.get(key); for (const effect of dep) { // + 判断是否有scheduler, 有则执行,无则执行fn if (effect.scheduler) { effect.scheduler(); } else { effect.run(); } }}let activeEffect;export function effect(fn, options: any = {}) { // + 直接将scheduler挂载到依赖上 const _effect = new ReactiveEffect(fn, options.scheduler); _effect.run(); return _effect.run.bind(_effect);}代码实现完成,那接下来看一下单测结果。
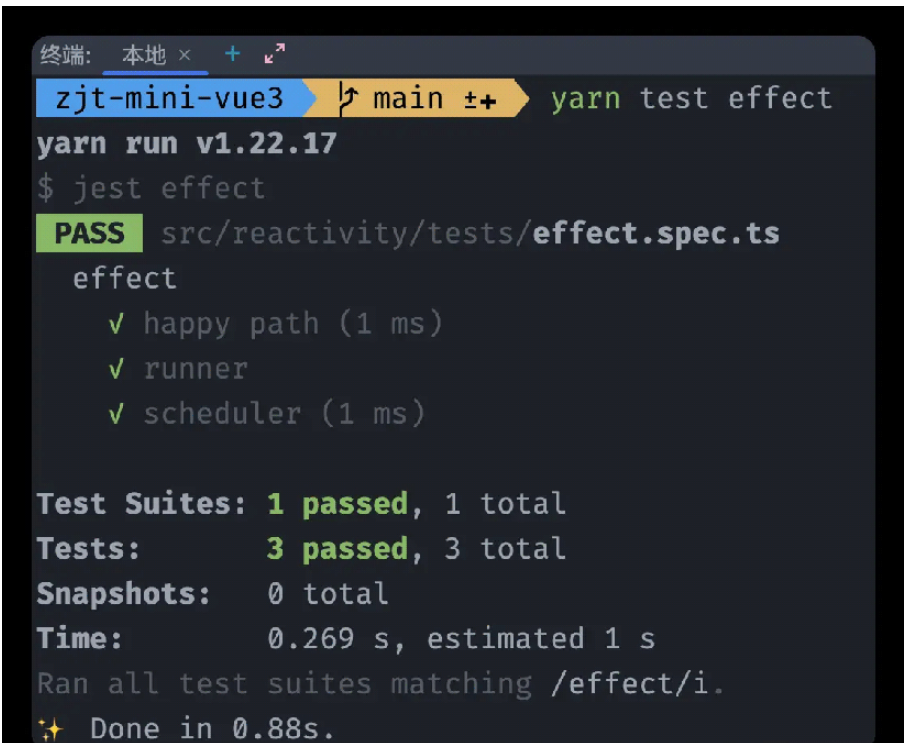
好,现在我们再回到最初的栗子????,在上面scheduler基础上,完成现有需求,继续看一下对此需求的单测。
it('job queue', () => { // 定义一个任务队列 const jobQueue = new Set(); // 使用 Promise.resolve() 创建一个 Promise 实例,我们用它将一个任务添加到微任务队列 const p = Promise.resolve(); // 一个标志代表是否正在刷新队列 let isFlushing = false; function flushJob() { // 如果队列正在刷新,则什么都不做 if (isFlushing) return; // 设置为true,代表正在刷新 isFlushing = true; // 在微任务队列中刷新 jobQueue 队列 p.then(() => { jobQueue.forEach((job: any) => job()); }).finally(() => { // 结束后重置 isFlushing isFlushing = false; // 虽然scheduler执行两次,但是由于是Set,所以只有一项 expect(jobQueue.size).toBe(1); // 期望最终结果拿数组存储后进行断言 expect(logArr).toEqual([1, 3]); }); } const obj = reactive({ foo: 1 }); let logArr: number[] = []; effect( () => { logArr.push(obj.foo); }, { scheduler(fn) { // 每次调度时,将副作用函数添加到 jobQueue 队列中 jobQueue.add(fn); // 调用 flushJob 刷新队列 flushJob(); }, }, ); obj.foo++; obj.foo++; expect(obj.foo).toBe(3);});在分析上段代码之前,为了辅助完成上述功能,我们需要回到trigger中,调整一下遍历执行,为了让我们的scheduler能拿到原始依赖。
for (const effect of dep) { // + 判断是否有scheduler, 有则执行,无则执行fn if (effect.scheduler) { effect.scheduler(effect._fn); } else { effect.run(); }}再观察上面的单测代码,首先,我们定义了一个任务队列jobQueue,它是一个Set数据结构,目的是利用Set数据结构的自动去重功能。
接着我们看调度器scheduler的实现,在每次调度执行时,先将当前副作用函数添加到jobQueue队列中,再调用flushJob函数刷新队列。
然后我们把目光转向flushJob函数,该函数通过isFlushing标志判断是否需要执行,只有当其为false 时才需要执行,而一旦flushJob函数开始执行,isFlushing标志就会设置为true,意思是无论调用多少次flushJob函数,在一个周期内都只会执行一次。
需要注意的是,在flushJob内通过p.then将一个函数添加到微任务队列,在微任务队列内完成对jobQueue的遍历执行。
整段代码的效果是,连续对obj.foo执行两次自增操作,会同步且连续地执行两次scheduler调度函数,这意味着同一个副作用函数会被jobQueue.add(fn)添加两次,但由于Set数据结构的去重能力,最终jobQueue中只会有一项,即当前副作用函数。
类似地,flushJob也会同步且连续执行两次,但由于isFlushing标志的存在,实际上flushJob函数在一个事件循环内只会执行一次,即在微任务队列内执行一次。
当微任务队列开始执行时,就会遍历jobQueue并执行里面存储的副作用函数。由于此时jobQueue队列内只有一个副作用函数,所以只会执行一次,并且当它执行时,字段obj.foo的值已经是3了,这样我们就实现了期望的输出。
再跑一遍完整流程,来看一下单测结果,确保新增代码不影响以往功能。
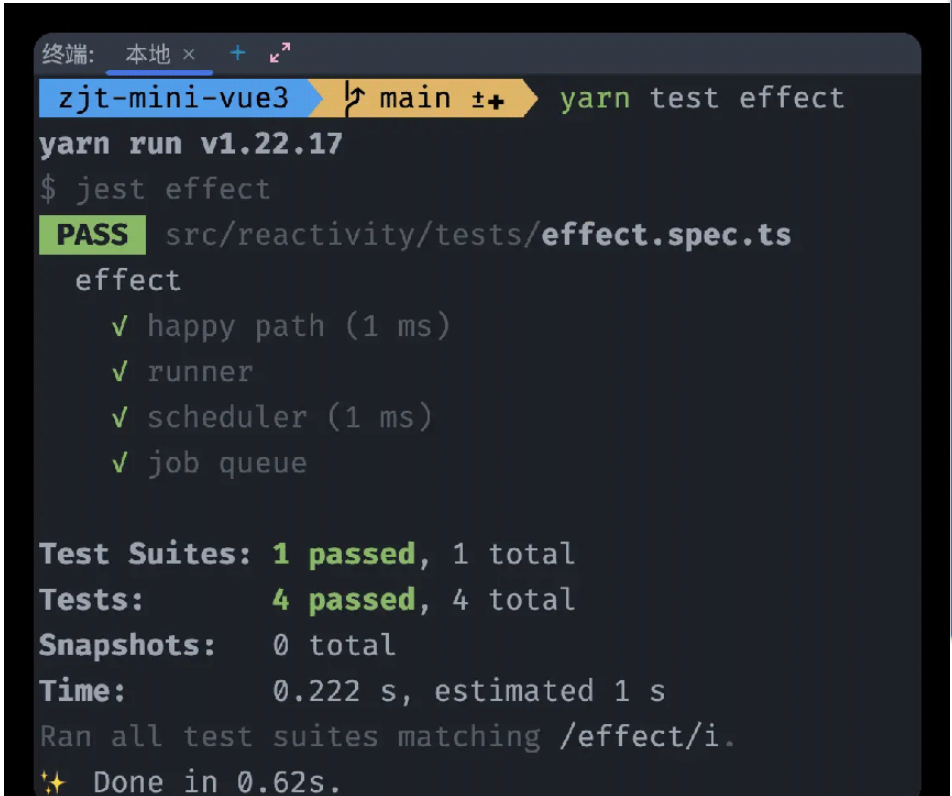
测试结束完以后,由于job queue是一个实际案例单测,所以我们将其抽离到examples下面的testCase里,建立jobQueue.spec.ts。
读到这里,这篇“vue3调度器effect的scheduler功能怎么实现”文章已经介绍完毕,想要掌握这篇文章的知识点还需要大家自己动手实践使用过才能领会,如果想了解更多相关内容的文章,欢迎关注编程网精选频道。
--结束END--
本文标题: vue3调度器effect的scheduler功能怎么实现
本文链接: https://lsjlt.com/news/346717.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0