这篇文章主要介绍了MySQL索引结构采用B+树的问题怎么理解的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇Mysql索引结构采用B+树的问题怎么理解文章都会有所收获,下面我们一起来看看吧。1、B树和B+树一般来
这篇文章主要介绍了MySQL索引结构采用B+树的问题怎么理解的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇Mysql索引结构采用B+树的问题怎么理解文章都会有所收获,下面我们一起来看看吧。
一般来说,数据库的存储引擎都是采用B树或者B+树来实现索引的存储。首先来看B树,如图所示。
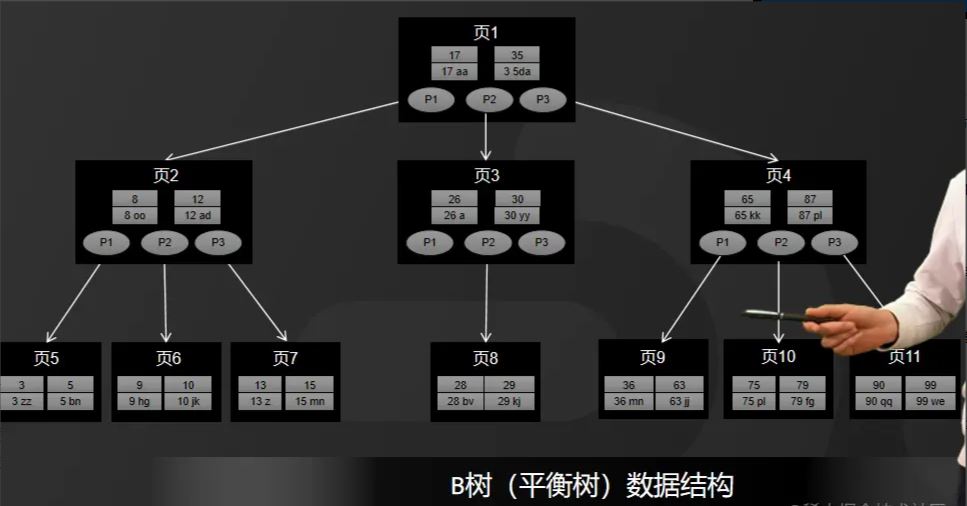
B树是一种多路平衡树,用这种存储结构来存储大量数据,它的整个高度会相比二叉树来说,会矮很多。
而对于数据库而言,所有的数据都将会保存到磁盘上,而磁盘I/O的效率又比较低,特别是在随机磁盘I/O的情况下效率更低。
所以 高度决定了磁盘I/O的次数,磁盘I/O次数越少,对于性能的提升就越大,这也是为什么采用B树作为索引存储结构的原因,如图所示。
而mysql的InnoDB存储引擎,它用了一种增强的B树结构,也就是B+树来作为索引和数据的存储结构。
相比较于B树结构来说,B+树做了两个方面的优化,如图所示。
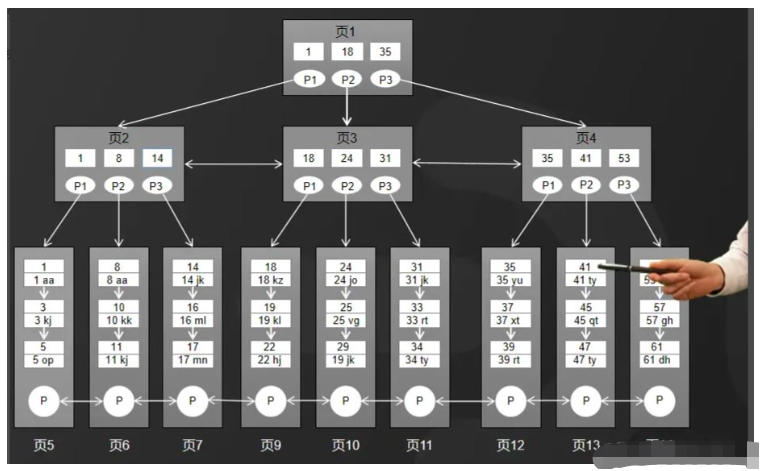
B+树的所有数据都存储在叶子节点,非叶子节点只存储索引。
叶子节点中的数据使用双向链表的方式进行关联。
我认为,Mysql索引结构采用B+树,有以下4个原因:

从磁盘I/O效率方面来看:B+树的非叶子节点不存储数据,所以树的每一层就能够存储更多的索引数量,也就是说,B+树在层高相同的情况下,比B树的存储数据量更多,间接会减少磁盘I/O的次数。
从范围查询效率方面来看:在MySQL中,范围查询是一个比较常用的操作,而B+树的所有存储在叶子节点的数据使用了双向链表来关联,所以B+树在查询的时候只需查两个节点进行遍历就行,而B树需要获取所有节点,因此,B+树在范围查询上效率更高。
从全表扫描方面来看:因为,B+树的叶子节点存储所有数据,所以B+树的全局扫描能力更强一些,因为它只需要扫描叶子节点。而B树需要遍历整个树。
从自增ID方面来看:基于B+树的这样一种数据结构,如果采用自增的整型数据作为主键,还能更好的避免增加数据的时候,带来叶子节点分裂导致的大量运算的问题。
关于“MySQL索引结构采用B+树的问题怎么理解”这篇文章的内容就介绍到这里,感谢各位的阅读!相信大家对“MySQL索引结构采用B+树的问题怎么理解”知识都有一定的了解,大家如果还想学习更多知识,欢迎关注编程网数据库频道。
--结束END--
本文标题: MySQL索引结构采用B+树的问题怎么理解
本文链接: https://lsjlt.com/news/341590.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0