本文小编为大家详细介绍“hadoop分布式文件系统hdfs架构分析”,内容详细,步骤清晰,细节处理妥当,希望这篇“Hadoop分布式文件系统HDFS架构分析”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。Hadoo
本文小编为大家详细介绍“hadoop分布式文件系统hdfs架构分析”,内容详细,步骤清晰,细节处理妥当,希望这篇“Hadoop分布式文件系统HDFS架构分析”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。
Hadoop分布式文件系统(HDFS)是一种基于Java的分布式文件系统,它具有容错性、可伸缩性和易扩展性等优点,它可在商用硬件上运行,也可以在低成本的硬件上进行部署。HDFS是一个分布式存储的Hadoop应用程序,它提供了更接近数据的接口。
hdfs架构图如下图所示:
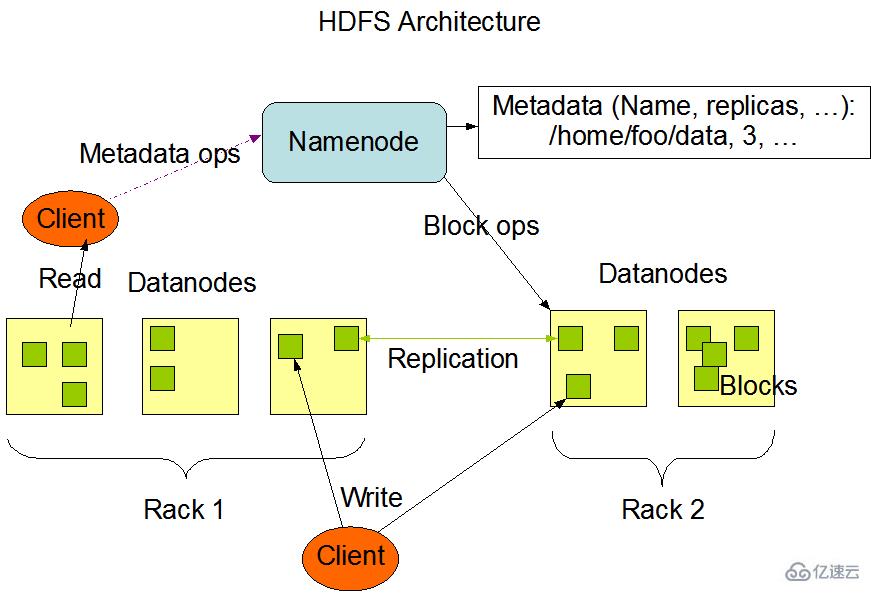
HDFS具有主/从架构。HDFS集群由单个Namenode,和多个datanode构成。
NameNode:管理文件系统命名空间的主服务器和管理客户端对文件的访问组成,如打开,关闭和重命名文件和目录。负责管理文件目录、文件和block的对应关系以及block和datanode的对应关系,维护目录树,接管用户的请求。如下图所示:

将文件的元数据保存在一个文件目录树中2、在磁盘上保存为:fsimage 和 edits3、保存datanode的数据信息的文件,在系统启动的时候读入内存。
DataNode:(数据节点)管理连接到它们运行的节点的存储,负责处理来自文件系统客户端的读写请求。DataNodes还执行块创建,删除
Client:(客户端)代表用户通过与nameNode和datanode交互来访问整个文件系统,HDFS对外开放文件命名空间并允许用户数据以文件形式存储。用户通过客户端(Client)与HDFS进行通讯交互。
**块和复制:**我们都知道linux操作系统中的磁盘的块的大小默认是512,而hadoop2.x版本中的块的大小默认为128M,那为什么hdfs中的存储块要设计这么大呢?其目的是为了减小寻址的开销。只要块足够大,磁盘传输数据的时间必定会明显大于这个块的寻址时间。
那为什么要以块的形式存储文件,而不是整个文件呢?1、因为一个文件可以特别大,可以大于有个磁盘的容量,所以以块的形式存储,可以用来存储无论大小怎样的文件。2、简化存储系统的设计。因为块是固定的大小,计算磁盘的存储能力就容易多了3、以块的形式存储不需要全部存在一个磁盘上,可以分布在各个文件系统的磁盘上,有利于复制和容错,数据本地化计算
块和复本在hdfs架构中分布如下图所示:
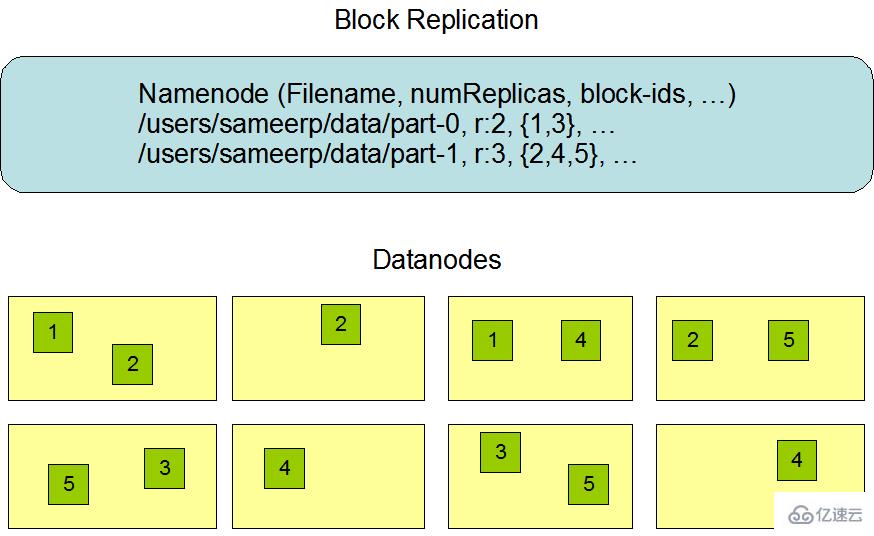
既然namenode管理着文件系统的命名空间,维护着文件系统树以及整颗树内的所有文件和目录,这些信息以文件的形式永远的保存在本地磁盘上,分别问命名空间镜像文件fsimage和编辑日志文件Edits。datanode是文件的工作节点,根据需要存储和检索数据块,并且定期的向namenode发送它们所存储的块的列表。那么就知道namenode是多么的重要,一旦那么namenode挂了,那整个分布式文件系统就不可以使用了,所以对于namenode的容错就显得尤为重要了,hadoop为此提供了两种容错机制:
就是通过对那些组成文件系统的元数据持久化,分别问命名空间镜像文件fsimage(文件系统的目录树)和编辑日志文件Edits(针对文件系统做的修改操作记录)。磁盘上的映像FsImage就是一个Checkpoint,一个里程碑式的基准点、同步点,有了一个Checkpoint之后,NameNode在相当长的时间内只是对内存中的目录映像操作,同时也对磁盘上的Edits操作,直到关机。下次开机的时候,NameNode要从磁盘上装载目录映像FSImage,那其实就是老的Checkpoint,也许就是上次开机后所保存的映像,而自从上次开机后直到关机为止对于文件系统的所有改变都记录在Edits文件中;将记录在Edits中的操作重演于上一次的映像,就得到这一次的新的映像,将其写回磁盘就是新的Checkpoint(也就是fsImage)。但是这样有很大一个缺点,如果Edits很大呢,开机后生成原始映像的过程也会很长,所以对其进行改进:每当 Edits长到一定程度,或者每隔一定的时间,就做一次Checkpoint,但是这样就会给namenode造成很大的负荷,会影响系统的性能。于是就有了SecondaryNameNode的需要,这相当于NameNode的助理,专替NameNode做Checkpoint。当然,SecondaryNameNode的负载相比之下是偏轻的。所以如果为NameNode配上了热备份,就可以让热备份兼职,而无须再有专职的SecondaryNameNode。所以架构图如下图所示:

SecondaryNameNode工作原理图:
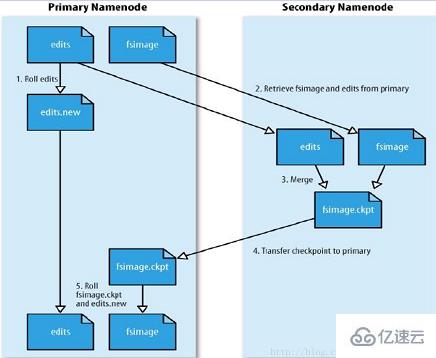
SecondaryNameNode主要负责下载NameNode中的fsImage文件和Edits文件,并合并生成新的fsImage文件,并推送给NameNode,工作原理如下:
secondarynamenode请求主namenode停止使用edits文件,暂时将新的写操作记录到一个新的文件中;2、secondarynamenode从主namenode获取fsimage和edits文件(通过Http get)3、secondarynamenode将fsimage文件载入内存,逐一执行edits文件中的操作,创建新的fsimage文件。4、secondarynamenode将新的fsimage文件发送回主namenode(使用http post).5、namenode用从secondarynamenode接收的fsimage文件替换旧的fsimage文件;用步骤1所产生的edits文件替换旧的edits文件。同时,还更新fstime文件来记录检查点执行时间。6、最终,主namenode拥有最新的fsimage文件和一个更小的edits文件。当namenode处在安全模式时,管理员也可调用hadoop dfsadmin –saveNameSpace命令来创建检查点。
从上面的过程中我们清晰的看到secondarynamenode和主namenode拥有相近内存需求的原因(因为secondarynamenode也把fsimage文件载入内存)。因此,在大型集群中,secondarynamenode需要运行在一台专用机器上。
创建检查点的触发条件受两个配置参数控制。通常情况下,secondarynamenode每隔一小时(有fs.checkpoint.period属性设置)创建检查点;此外,当编辑日志的大小达到64MB(有fs.checkpoint.size属性设置)时,也会创建检查点。系统每隔五分钟检查一次编辑日志的大小。
三、HDFS读数据流程
HDFS读数据流程如下图所示:
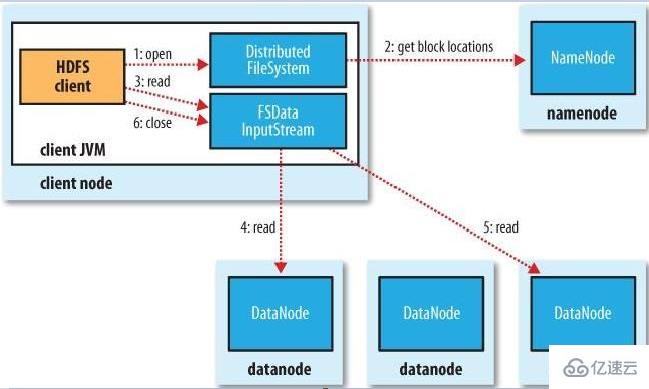
客户端通过FileSystem对象(DistributedFileSystem)的open()方法来打开希望读取的文件。
DistributedFileSystem通过远程调用(rpc)来调用namenode,获取到每个文件的起止位置。对于每一个块,namenode返回该块副本的datanode。这些datanode会根据它们与客户端的距离(集群的网络拓扑结构)排序,如果客户端本身就是其中的一个datanode,那么就会在该datanode上读取数据。DistributedFileSystem远程调用后返回一个FSDatainputStream(支持文件定位的输入流)对象给客户端以便于读取数据,然后FSDataInputStream封装一个DFSInputStream对象。该对象管理datanode和namenode的IO。
客户端对这个输入流调用read()方法,存储着文件起始几个块的datanode地址的DFSInputStream随即连接距离最近的文件中第一个块所在的datanode,通过数据流反复调用read()方法,可以将数据从datanode传送到客户端。当读完这个块时,DFSInputStream关闭与该datanode的连接,然后寻址下一个位置最佳的datanode。
客户端从流中读取数据时,块是按照打开DFSInputStream与datanode新建连接的顺序读取的。它也需要询问namenode来检索下一批所需块的datanode的位置。一旦客户端完成读取,就对FSDataInputStream调用close()方法。
注意:在读取数据的时候,如果DFSInputStream在与datanode通讯时遇到错误,它便会尝试从这个块的另外一个临近datanode读取数据。他也会记住那个故障datanode,以保证以后不会反复读取该节点上后续的块。DFSInputStream也会通过校验和确认从datanode发送来的数据是否完整。如果发现一个损坏的块, DFSInputStream就会在试图从其他datanode读取一个块的复本之前通知namenode。
读到这里,这篇“Hadoop分布式文件系统HDFS架构分析”文章已经介绍完毕,想要掌握这篇文章的知识点还需要大家自己动手实践使用过才能领会,如果想了解更多相关内容的文章,欢迎关注编程网精选频道。
--结束END--
本文标题: Hadoop分布式文件系统HDFS架构分析
本文链接: https://lsjlt.com/news/311229.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0