Python 官方文档:入门教程 => 点击学习
这篇文章主要介绍“python数据分析过程是怎样的”的相关知识,小编通过实际案例向大家展示操作过程,操作方法简单快捷,实用性强,希望这篇“Python数据分析过程是怎样的”文章能帮助大家解决问题。一、需求介绍该需求主要是分析某一种数据的历史
这篇文章主要介绍“python数据分析过程是怎样的”的相关知识,小编通过实际案例向大家展示操作过程,操作方法简单快捷,实用性强,希望这篇“Python数据分析过程是怎样的”文章能帮助大家解决问题。
该需求主要是分析某一种数据的历史数据。
客户的需求是根据该数据的前两期的情况,如果存在某个斜着的两个数字相等,那么就买第三期的同一个位置处的彩票,
对于1、,如果相等的数字是:1-5,那就买6-10,如果相等的数字是:6-10,那就买1-5;
对于2、,如果相等的数字是:1-5,那就买1-5,如果相等的数字是:6-10,,那就买6-10。
然后,根据这个方案,有可能会买中,但是也有可能买不中,于是,客户希望我可以统计出来在100天中,按照这种方法,连续6次以及6次以上的购买彩票才能够命中一次奖的次数以及分别所对应的时间,对于这个案例,我们下面详细分析。
(在这里,我们先利用 Jupyter Notebook 来进行分析,然后,在得到成果以后,利用 PyCharm 来进行完整的程序设计。)
打开如下图所示的界面可以获取到网址以及请求头:
1、网址(历史数据的网址)
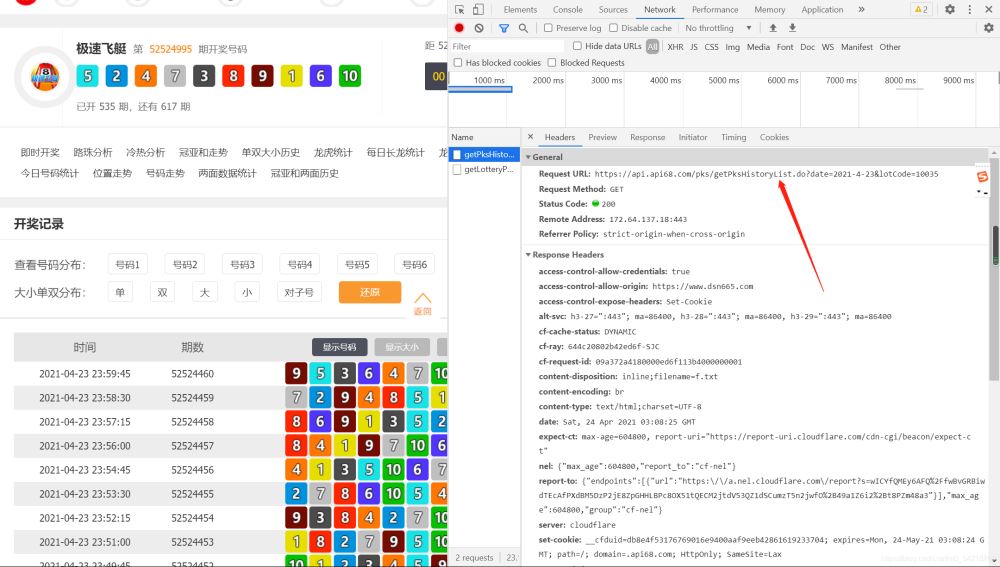
请求头

然后我们在程序中进行代码书写获取数据:


然后进行一定的预处理:
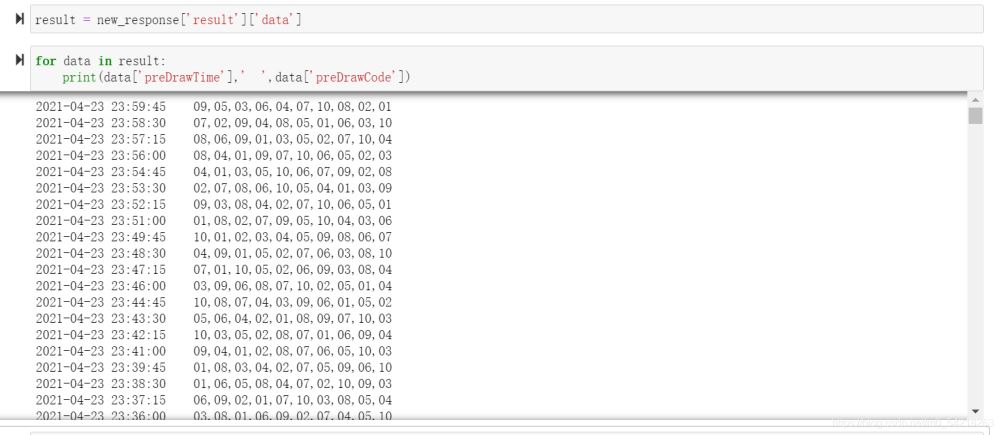
这里我们直接展示代码:
def reverse_list(lst): """ 准换列表的先后顺序 :param lst: 原始列表 :return: 新的列表 """ return [ele for ele in reversed(lst)]low_list = ["01", "02", "03", "04", "05"]# 设置比较小的数字的列表high_list = ["06", "07", "08", "09", "10"]# 设置比较大的数字的列表N = 0# 设置一个数字N来记录一共有多少期可以购买n = 0# 设置一个数字n来记录命中了多少期彩票record_number = 1 # 设置记录数据的一个判断值list_data_number = []# 设置一个空的列表来存储一天之中的连续挂掉的期数dict_time_record = {}# 设置一个空的字典来存储连挂掉的期数满足所列条件的时间节点for k in range(1152): # 循环遍历所有的数据点 if k < 1150: new_result1 = reverse_list(new_response["result"]["data"])[k] # 第一期数据 new_result2 = reverse_list(new_response["result"]["data"])[k + 1] # 第二期数据 new_result3 = reverse_list(new_response["result"]["data"])[k + 2] # 第三期数据 data1 = new_result1['preDrawCode'].split(',') # 第一期数据 data2 = new_result2['preDrawCode'].split(',') # 第二期数据 data3 = new_result3['preDrawCode'].split(',') # 第三期数据 for m in range(10): # 通过循环来判断是否满足购买的条件,并且实现一定的功能 if m == 0: if data2[0] == data1[1]: # 如果相等就要结束循环 N += 1 # 可以购买的期数应该要自加一 if (data2[0] in low_list and data3[0] in low_list) or (data2[0] in high_list and data3[0] in high_list): n += 1 # 命中的期数应该要自加一 # 如果命中了的话,本轮结束,开启下一轮 list_data_number.append(record_number) if f"{record_number}" in dict_time_record.keys(): # 如果已经有了这个键,那么值添加时间点 dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:]) else: # 如果没有这个键,那么添加一个键值对,值为一个列表,而且初始化为当前的时间 dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]] record_number = 1 # 初始化下一轮的开始 else: record_number += 1 # 如果没有命中的话,次数就应该要自加一 break # 如果满足相等的条件就要结束循环 elif m == 9: # 与上面差不多的算法 if data2[9] == data1[8]: # 如果相等 N += 1 if (data2[9] in low_list and data3[9] in low_list) or (data2[9] in high_list and data3[9] in high_list): n += 1 list_data_number.append(record_number) if f"{record_number}" in dict_time_record.keys(): dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:]) else: dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]] record_number = 1 else: record_number += 1 break else: # 与上面差不多的算法 if data2[m] == data1[m + 1] or data2[m] == data1[m - 1]: # 如果相等 N += 1 if (data2[m] in low_list and data3[m] in low_list) or (data2[m] in high_list and data3[m] in high_list): n += 1 list_data_number.append(record_number) if f"{record_number}" in dict_time_record.keys(): dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:]) else: dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]] record_number = 1 else: record_number += 1 breakprint(f"日期:{new_response['result']['data'][0]['preDrawTime'][:10]},总的梯子数为{N}个,一共有{n}次命中,一共有{N - n}次挂了")# 打印时间,以及,可以购买的期数,命中的期数,没有命中的期数list_data_number.sort()# 按照大小顺序来进行排序dict_record = {}# 设置空字典进行记录for i in list_data_number: if f"{i}" in dict_record.keys(): # 判断是否已经有了这个数字? dict_record[f"{i}"] += 1 # 如果有的话,那么就会自加一 else: # 如果没有的话,那么就会创建并且赋值等于 1 dict_record[f"{i}"] = 1 # 创建一个新的字典元素,然后进行赋值为 1for j in dict_record.keys(): if (int(j) >= 6) and (int(j) < 15): # 实际的结果表明,我们需要的是大于等于6期的数据,而没有出现大于15的数据,因此有这样的一个关系式 print(f"买{j}次才中奖的次数为{dict_record[j]}") # 打印相关信息 print(dict_time_record[j]) str0 = "" for letter in dict_time_record[j]: str0 += letter str0 += ", " print(str0) # 打印相关信息运行结果的展示如下图所示:
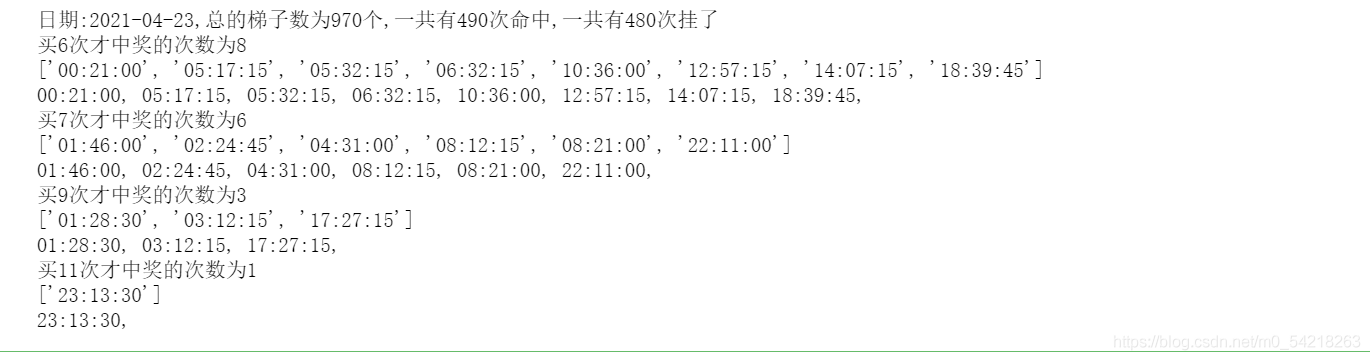
首先设置一个事件列表来记录需要统计哪些天的数据:
代码:
data_list = []for h in range(31): data_list.append(f'1-{h + 1}')for h in range(28): data_list.append(f'2-{h + 1}')for h in range(31): data_list.append(f'3-{h + 1}')for h in range(20): data_list.append(f'4-{h + 1}')通过上述的代码,我们即实现了时间列表的设置,然后我们循环遍历这个列表访问不同日期的彩票数据即就是得到了不同时间的数据,然后再利用上述的分析方法来进行数据分析,即就是可以得到了多天的彩票数据分析的结果了。
这里我们可以采用xlwt 模块来进行excel表格的写入操作啦,具体的写入就不必过多赘述了。
一下是完整的代码:
import requestsimport chardetimport JSONimport xlwt # excel 表格数据处理的对应模块def reverse_list(lst): """ 准换列表的先后顺序 :param lst: 原始列表 :return: 新的列表 """ return [ele for ele in reversed(lst)]data_list = []for h in range(31): data_list.append(f'1-{h + 1}')for h in range(28): data_list.append(f'2-{h + 1}')for h in range(31): data_list.append(f'3-{h + 1}')for h in range(20): data_list.append(f'4-{h + 1}')wb = xlwt.Workbook() # 创建 excel 表格sh = wb.add_sheet('彩票分析数据处理') # 创建一个 表单sh.write(0, 0, "日期")sh.write(0, 1, "梯子数目")sh.write(0, 2, "命中数目")sh.write(0, 3, "挂的数目")sh.write(0, 4, "6次中的数目")sh.write(0, 5, "6次中的时间")sh.write(0, 6, "7次中的数目")sh.write(0, 7, "7次中的时间")sh.write(0, 8, "8次中的数目")sh.write(0, 9, "8次中的时间")sh.write(0, 10, "9次中的数目")sh.write(0, 11, "9次中的时间")sh.write(0, 12, "10次中的数目")sh.write(0, 13, "10次中的时间")sh.write(0, 14, "11次中的数目")sh.write(0, 15, "11次中的时间")sh.write(0, 16, "12次中的数目")sh.write(0, 17, "12次中的时间")sh.write(0, 18, "13次中的数目")sh.write(0, 19, "13次中的时间")sh.write(0, 20, "14次中的数目")sh.write(0, 21, "14次中的时间")# wb.save('test4.xls')sheet_seek_position = 1# 设置表格的初始位置为 1for data in data_list: low_list = ["01", "02", "03", "04", "05"] high_list = ["06", "07", "08", "09", "10"] N = 0 n = 0 url = f'https://api.api68.com/pks/getPksHistoryList.do?date=2021-{data}&lotCode=10037' headers = { 'User-Agent': 'Mozilla/5.0 (windows NT 10.0; Win64; x64) ' 'AppleWEBKit/537.36 (Khtml, like Gecko) ' 'Chrome/90.0.4430.72 Safari/537.36' } response = requests.get(url=url, headers=headers) response.encoding = chardet.detect(response.content)['encoding'] new_response = json.loads(response.text) sh.write(sheet_seek_position, 0, new_response['result']['data'][0]['preDrawTime'][:10]) # 在表格的第一个位置处写入时间,意即:data record_number = 1 # 记录数据的一个判断值,设置为第一次,应该是要放在最外面的啦 list_data_number = [] # 设置一个空列表来存储一天之中的连续挂的期数 dict_time_record = {} for k in range(1152): # record_number = 1,应该要放外面 # 记录数据的一个判断值,设置为第一次 if k < 1150: new_result1 = reverse_list(new_response["result"]["data"])[k] new_result2 = reverse_list(new_response["result"]["data"])[k + 1] new_result3 = reverse_list(new_response["result"]["data"])[k + 2] data1 = new_result1['preDrawCode'].split(',') data2 = new_result2['preDrawCode'].split(',') data3 = new_result3['preDrawCode'].split(',') for m in range(10): if m == 0: if data2[0] == data1[1]: N += 1 if (data2[0] in low_list and data3[0] in high_list) or (data2[0] in high_list and data3[0] in low_list): n += 1 # 如果命中了的话,本轮结束,开启下一轮 list_data_number.append(record_number) if f"{record_number}" in dict_time_record.keys(): dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:]) else: dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]] # print(record_number) record_number = 1 # 初始化 else: record_number += 1 # 没中,次数加一 # 自加一 break elif m == 9: if data2[9] == data1[8]: N += 1 if (data2[9] in low_list and data3[9] in high_list) or (data2[9] in high_list and data3[9] in low_list): n += 1 list_data_number.append(record_number) if f"{record_number}" in dict_time_record.keys(): dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:]) else: dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]] # print(record_number) record_number = 1 else: record_number += 1 break else: if data2[m] == data1[m + 1] or data2[m] == data1[m - 1]: N += 1 if (data2[m] in low_list and data3[m] in high_list) or (data2[m] in high_list and data3[m] in low_list): n += 1 list_data_number.append(record_number) if f"{record_number}" in dict_time_record.keys(): dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:]) else: dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]] # print(record_number) record_number = 1 else: record_number += 1 break print(f"日期:{new_response['result']['data'][0]['preDrawTime'][:10]},总的梯子数为{N}个,一共有{n}次命中,一共有{N - n}次挂了") sh.write(sheet_seek_position, 1, N) sh.write(sheet_seek_position, 2, n) sh.write(sheet_seek_position, 3, N - n) # new_list_data_number = list_data_number.sort() list_data_number.sort() # 进行排序 dict_record = {} # 设置空字典 for i in list_data_number: if f"{i}" in dict_record.keys(): # 判断是否已经有了这个数字? dict_record[f"{i}"] += 1 # 如果有的话,那么就会自加一 else: # 如果没有的话,那么就会创建并且赋值等于 1 dict_record[f"{i}"] = 1 # 创建一个新的字典元素,然后进行赋值为 1 # print(dict_record) # print(f"买彩票第几次才中奖?") # print(f"按照我们的规律买彩票的情况:") for j in dict_record.keys(): if (int(j) >= 6) and (int(j) < 15): print(f"买{j}次才中奖的次数为{dict_record[j]}") print(dict_time_record[j]) str0 = "" for letter in dict_time_record[j]: str0 += letter str0 += ", " print(str0) sh.write(sheet_seek_position, 4 + (int(j) - 6) * 2, dict_record[j]) # 写入几次 sh.write(sheet_seek_position, 4 + (int(j) - 6) * 2 + 1, str0[:-2]) # 注意这里应该要改为 -2 # 写入几次对应的时间 # print(j) sheet_seek_position += 1 # 每次写完了以后,要对位置进行换行,换到下一行,从而方便下一行的写入# 保存wb.save('极速飞艇彩票分析结果.xls')运行结果展示:
展示1、
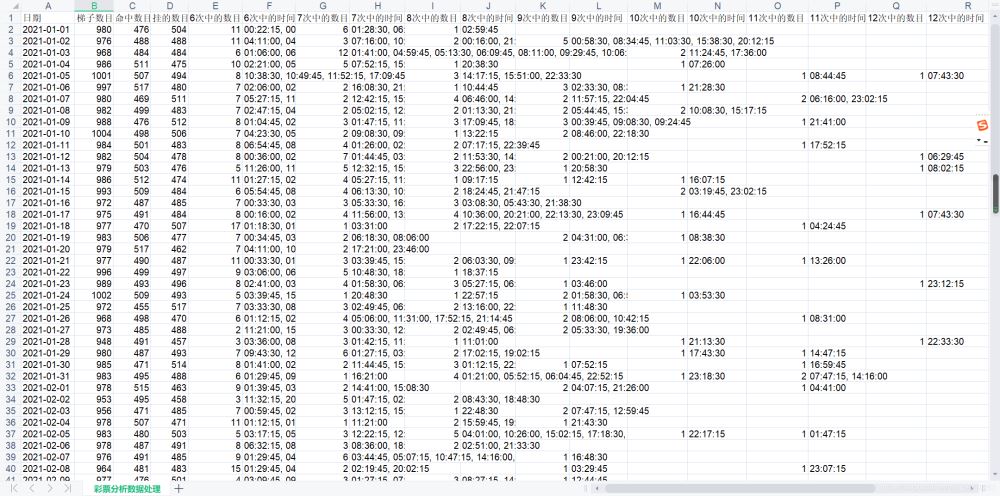
展示2、
从而,我们便解决了极速飞艇的彩票的数据分析
然后,我们只需要稍稍改变一点点算法,其他的部分是完全一样的啦,从而即就是可以实现极速赛车的数据分析了啦。
修改的代码在下面列出来了:
for m in range(10): if m == 0: if data2[0] == data1[1]: N += 1 if (data2[0] in low_list and data3[0] in low_list) or (data2[0] in high_list and data3[0] in high_list): n += 1 # 如果命中了的话,本轮结束,开启下一轮 list_data_number.append(record_number) if f"{record_number}" in dict_time_record.keys(): dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:]) else: dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]] # print(record_number) record_number = 1 # 初始化 else: record_number += 1 # 没中,次数加一 # 自加一 break elif m == 9: if data2[9] == data1[8]: N += 1 if (data2[9] in low_list and data3[9] in low_list) or (data2[9] in high_list and data3[9] in high_list): n += 1 list_data_number.append(record_number) if f"{record_number}" in dict_time_record.keys(): dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:]) else: dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]] # print(record_number) record_number = 1 else: record_number += 1 break else: if data2[m] == data1[m + 1] or data2[m] == data1[m - 1]: N += 1 if (data2[m] in low_list and data3[m] in low_list) or (data2[m] in high_list and data3[m] in high_list): n += 1 list_data_number.append(record_number) if f"{record_number}" in dict_time_record.keys(): dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:]) else: dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]] # print(record_number) record_number = 1 else: record_number += 1 break关于“Python数据分析过程是怎样的”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识,可以关注编程网Python频道,小编每天都会为大家更新不同的知识点。
--结束END--
本文标题: Python数据分析过程是怎样的
本文链接: https://lsjlt.com/news/306785.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0