Python 官方文档:入门教程 => 点击学习
这篇文章给大家介绍python+selenium+Pytesseract怎么实现图片验证码识别,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。一、selenium截取验证码import JSONfrom&nbs
这篇文章给大家介绍python+selenium+Pytesseract怎么实现图片验证码识别,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
import JSONfrom io import BytesIOimport timefrom test.testBefore.testDriver import driverfrom test.util.test_pytesseract import recognizefrom PIL import Imageimport allureimport unittest ''' /处理验证码 ''' # 要截图的元素 element = driver.find_element_by_xpath('//*[@id="imgVerifyCode"]') # 坐标 x, y = element.location.values() # 宽高 h, w = element.size.values() # 把截图以二进制形式的数据返回 image_data = driver.get_screenshot_as_png() # 以新图片打开返回的数据 screenshot = Image.open(BytesIO(image_data)) # 对截图进行裁剪 result = screenshot.crop((x, y, x + w, y + h)) # 显示图片 # result.show() # 保存验证码图片 result.save('VerifyCode.png') # 调用recognize方法识别验证码 code = recognize('VerifyCode.png') # 输入验证码 driver.find_element_by_xpath('//*[@id="txtcode"]').send_keys(code) ''' 处理验证码/ '''注意:driver是引用我自己写的文件,可以自己随便写一个。识别图片的代码单独放在util文件夹下面的,参考标题三的代码,需要时引用。以上代码定位元素都需要根据自己的项目定位元素修改。
如果没有输出,又不确定你的pytesseract环境是否安装好,可以用一张没有干扰的图片识别看看能不能有输出结果,以下样例在我的环境中可以直接输出识别结果8fnp
直接使用pytesseract识别图片
001.png
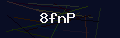
text = pytesseract.image_to_string('./001.png')print(text)直接截图的验证码图片存在噪点或者干扰线等,直接使用pytesseract识别可能会没有输出结果,如果环境正常,但没有输出结果,那多半是因为图片没有处理好,识别不出来,可以多尝试一些处理图片的方式,以下代码处理我截图这种类似的图片效果比较好。
对图片处理的过程:
图片处理过程中可以多用im.show()看看每一步处理后的图片是不是符合预期,如果效果不好调一下参数。另外在学习过程中发现有童鞋说识别不出来把图片使用cv2.resize()这个方法放大就能识别,可以参考Python中图像的缩放 resize()函数的应用
实际截取的图片

处理后的图片

test_pytesseract.py
import pytesseractfrom fnmatch import fnmatchimport cv2import osdef clear_border(img, img_name): ''' 去除边框 ''' h, w = img.shape[:2] for y in range(0, w): for x in range(0, h): # if y ==0 or y == w -1 or y == w - 2: if y < 2 or y > w - 2: img[x, y] = 255 # if x == 0 or x == h - 1 or x == h - 2: if x < 1 or x > h - 1: img[x, y] = 255 return imgdef interference_line(img, img_name): ''' 干扰线降噪 ''' h, w = img.shape[:2] # !!!OpenCV矩阵点是反的 # img[1,2] 1:图片的高度,2:图片的宽度 for r in range(0, 2): for y in range(1, w - 1): for x in range(1, h - 1): count = 0 if img[x, y - 1] > 245: count = count + 1 if img[x, y + 1] > 245: count = count + 1 if img[x - 1, y] > 245: count = count + 1 if img[x + 1, y] > 245: count = count + 1 if count > 2: img[x, y] = 255 return imgdef interference_point(img, img_name, x=0, y=0): """点降噪 9邻域框,以当前点为中心的田字框,黑点个数 :param x: :param y: :return: """ # todo 判断图片的长宽度下限 cur_pixel = img[x, y] # 当前像素点的值 height, width = img.shape[:2] for y in range(0, width - 1): for x in range(0, height - 1): if y == 0: # 第一行 if x == 0: # 左上顶点,4邻域 # 中心点旁边3个点 sum = int(cur_pixel) \ + int(img[x, y + 1]) \ + int(img[x + 1, y]) \ + int(img[x + 1, y + 1]) if sum <= 2 * 245: img[x, y] = 0 elif x == height - 1: # 右上顶点 sum = int(cur_pixel) \ + int(img[x, y + 1]) \ + int(img[x - 1, y]) \ + int(img[x - 1, y + 1]) if sum <= 2 * 245: img[x, y] = 0 else: # 最上非顶点,6邻域 sum = int(img[x - 1, y]) \ + int(img[x - 1, y + 1]) \ + int(cur_pixel) \ + int(img[x, y + 1]) \ + int(img[x + 1, y]) \ + int(img[x + 1, y + 1]) if sum <= 3 * 245: img[x, y] = 0 elif y == width - 1: # 最下面一行 if x == 0: # 左下顶点 # 中心点旁边3个点 sum = int(cur_pixel) \ + int(img[x + 1, y]) \ + int(img[x + 1, y - 1]) \ + int(img[x, y - 1]) if sum <= 2 * 245: img[x, y] = 0 elif x == height - 1: # 右下顶点 sum = int(cur_pixel) \ + int(img[x, y - 1]) \ + int(img[x - 1, y]) \ + int(img[x - 1, y - 1]) if sum <= 2 * 245: img[x, y] = 0 else: # 最下非顶点,6邻域 sum = int(cur_pixel) \ + int(img[x - 1, y]) \ + int(img[x + 1, y]) \ + int(img[x, y - 1]) \ + int(img[x - 1, y - 1]) \ + int(img[x + 1, y - 1]) if sum <= 3 * 245: img[x, y] = 0 else: # y不在边界 if x == 0: # 左边非顶点 sum = int(img[x, y - 1]) \ + int(cur_pixel) \ + int(img[x, y + 1]) \ + int(img[x + 1, y - 1]) \ + int(img[x + 1, y]) \ + int(img[x + 1, y + 1]) if sum <= 3 * 245: img[x, y] = 0 elif x == height - 1: # 右边非顶点 sum = int(img[x, y - 1]) \ + int(cur_pixel) \ + int(img[x, y + 1]) \ + int(img[x - 1, y - 1]) \ + int(img[x - 1, y]) \ + int(img[x - 1, y + 1]) if sum <= 3 * 245: img[x, y] = 0 else: # 具备9领域条件的 sum = int(img[x - 1, y - 1]) \ + int(img[x - 1, y]) \ + int(img[x - 1, y + 1]) \ + int(img[x, y - 1]) \ + int(cur_pixel) \ + int(img[x, y + 1]) \ + int(img[x + 1, y - 1]) \ + int(img[x + 1, y]) \ + int(img[x + 1, y + 1]) if sum <= 4 * 245: img[x, y] = 0 return imgdef _get_dynamic_binary_image(filedir, img_name): ''' 自适应阀值二值化 ''' filename = './' + img_name.split('.')[0] + '-binary.png' img_name = filedir + '/' + filename im = cv2.imread(img_name) im = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY) th2 = cv2.adaptiveThreshold(im, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 21, 1) return th2def recognize(image): filedir = './' # 验证码路径 for file in os.listdir(filedir): if fnmatch(file, image): img_name = file # 自适应阈值二值化 im = _get_dynamic_binary_image(filedir, img_name) # # 去除边框 im = clear_border(im, img_name) # 对图片进行干扰线降噪 im = interference_line(im, img_name) # 对图片进行点降噪 im = interference_point(im, img_name) filename = './' + img_name.split('.')[0] + '-interferencePoint.png' # easy_code为保存路径 cv2.imwrite(filename, im) # 保存图片 text = pytesseract.image_to_string(im, lang="eng", config='--psm 6 digits') # config=digits只识别数字 return text ''' --psm 参数含义 0:定向脚本监测(OSD) 1: 使用OSD自动分页 2 :自动分页,但是不使用OSD或OCR(Optical Character Recognition,光学字符识别) 3 :全自动分页,但是没有使用OSD(默认) 4 :假设可变大小的一个文本列。 5 :假设垂直对齐文本的单个统一块。 6 :假设一个统一的文本块。 7 :将图像视为单个文本行。 8 :将图像视为单个词。 9 :将图像视为圆中的单个词。 10 :将图像视为单个字符。 '''关于Python+Selenium+Pytesseract怎么实现图片验证码识别就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
--结束END--
本文标题: Python+Selenium+Pytesseract怎么实现图片验证码识别
本文链接: https://lsjlt.com/news/306683.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0