Python 官方文档:入门教程 => 点击学习
python调用百度api怎么实现语音识别,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。最近在学习Python,做一些python练习题GitHub上几年前的练习题有一题是这样
python调用百度api怎么实现语音识别,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
GitHub上几年前的练习题
有一题是这样的:
使用 Python 实现:对着电脑吼一声,自动打开浏览器中的默认网站。
例如,对着笔记本电脑吼一声“百度”,浏览器自动打开百度首页。
然后开始search相应的功能需要的模块(windows10),理一下思路:
本地录音
上传录音,获得返回结果
组一个map,根据结果打开相应的网页
所需模块:
PyAudio:录音接口
wave:打开录音文件并设置音频参数
requests:GET/POST
为什么要用百度语音识别api呢?因为免费试用。。
不多说,登录百度云,创建应用
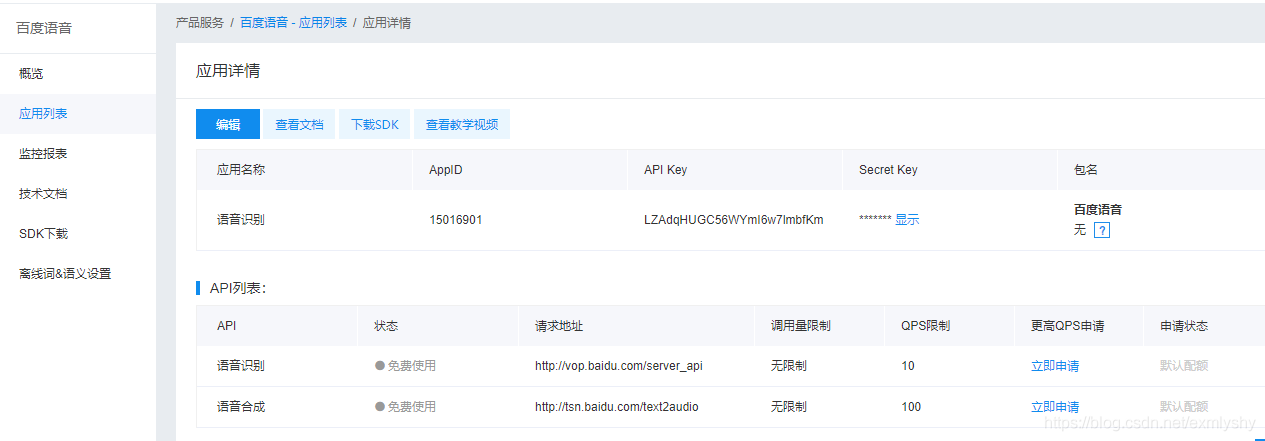
简单概括就是
可以下载使用SDK

不需要下载使用SDK
选择2.
语音格式
格式支持:pcm(不压缩)、wav(不压缩,pcm编码)、amr(压缩格式)。推荐pcm 采样率 :16000 固定值。 编码:16bit 位深的单声道。
百度服务端会将非pcm格式,转为pcm格式,因此使用wav、amr会有额外的转换耗时。
保存为pcm格式可以识别,只是windows自带播放器识别不了pcm格式的,所以改用wav格式,毕竟用的模块是wave?
首先是本地录音
import wavefrom pyaudio import PyAudio, paint16framerate = 16000 # 采样率num_samples = 2000 # 采样点channels = 1 # 声道sampwidth = 2 # 采样宽度2bytesFILEPATH = 'speech.wav'def save_wave_file(filepath, data): wf = wave.open(filepath, 'wb') wf.setnchannels(channels) wf.setsampwidth(sampwidth) wf.setframerate(framerate) wf.writeframes(b''.join(data)) wf.close()#录音def my_record(): pa = PyAudio() #打开一个新的音频stream stream = pa.open(fORMat=paInt16, channels=channels, rate=framerate, input=True, frames_per_buffer=num_samples) my_buf = [] #存放录音数据 t = time.time() print('正在录音...') while time.time() < t + 4: # 设置录音时间(秒) #循环read,每次read 2000frames string_audio_data = stream.read(num_samples) my_buf.append(string_audio_data) print('录音结束.') save_wave_file(FILEPATH, my_buf) stream.close()然后是获取token
import requestsimport base64 #百度语音要求对本地语音二进制数据进行base64编码#组装url获取token,详见文档base_url = "https://openapi.baidu.com/oauth/2.0/token?grant_type=client_credentials&client_id=%s&client_secret=%s"APIKey = "LZAdqHUGC********mbfKm"SecreTKEy = "WYPPwgHu********BU6GM*****"HOST = base_url % (APIKey, SecretKey)def getToken(host): res = requests.post(host) return res.json()['access_token']#传入语音二进制数据,token#dev_pid为百度语音识别提供的几种语言选择def speech3text(speech_data, token, dev_pid=1537): FORMAT = 'wav' RATE = '16000' CHANNEL = 1 CUID = '********' SPEECH = base64.b64encode(speech_data).decode('utf-8') data = { 'format': FORMAT, 'rate': RATE, 'channel': CHANNEL, 'cuid': CUID, 'len': len(speech_data), 'speech': SPEECH, 'token': token, 'dev_pid':dev_pid } url = 'Https://vop.baidu.com/server_api' headers = {'Content-Type': 'application/json'} # r=requests.post(url,data=json.dumps(data),headers=headers) print('正在识别...') r = requests.post(url, json=data, headers=headers) Result = r.json() if 'result' in Result: return Result['result'][0] else: return Result最后就是对返回的结果进行匹配,这里使用WEBbrowser这个模块
webbrower.open(url)完整demo
#!/usr/bin/env python# -*- coding: utf-8 -*-# Date : 2018-12-02 19:04:55import waveimport requestsimport timeimport base64from pyaudio import PyAudio, paInt16import webbrowserframerate = 16000 # 采样率num_samples = 2000 # 采样点channels = 1 # 声道sampwidth = 2 # 采样宽度2bytesFILEPATH = 'speech.wav'base_url = "https://openapi.baidu.com/oauth/2.0/token?grant_type=client_credentials&client_id=%s&client_secret=%s"APIKey = "********"SecretKey = "************"HOST = base_url % (APIKey, SecretKey)def getToken(host): res = requests.post(host) return res.json()['access_token']def save_wave_file(filepath, data): wf = wave.open(filepath, 'wb') wf.setnchannels(channels) wf.setsampwidth(sampwidth) wf.setframerate(framerate) wf.writeframes(b''.join(data)) wf.close()def my_record(): pa = PyAudio() stream = pa.open(format=paInt16, channels=channels, rate=framerate, input=True, frames_per_buffer=num_samples) my_buf = [] # count = 0 t = time.time() print('正在录音...') while time.time() < t + 4: # 秒 string_audio_data = stream.read(num_samples) my_buf.append(string_audio_data) print('录音结束.') save_wave_file(FILEPATH, my_buf) stream.close()def get_audio(file): with open(file, 'rb') as f: data = f.read() return datadef speech3text(speech_data, token, dev_pid=1537): FORMAT = 'wav' RATE = '16000' CHANNEL = 1 CUID = '*******' SPEECH = base64.b64encode(speech_data).decode('utf-8') data = { 'format': FORMAT, 'rate': RATE, 'channel': CHANNEL, 'cuid': CUID, 'len': len(speech_data), 'speech': SPEECH, 'token': token, 'dev_pid':dev_pid } url = 'https://vop.baidu.com/server_api' headers = {'Content-Type': 'application/json'} # r=requests.post(url,data=json.dumps(data),headers=headers) print('正在识别...') r = requests.post(url, json=data, headers=headers) Result = r.json() if 'result' in Result: return Result['result'][0] else: return Resultdef openbrowser(text): maps = { '百度': ['百度', 'baidu'], '腾讯': ['腾讯', 'tengxun'], '网易': ['网易', 'wangyi'] } if text in maps['百度']: webbrowser.open_new_tab('https://www.baidu.com') elif text in maps['腾讯']: webbrowser.open_new_tab('https://www.qq.com') elif text in maps['网易']: webbrowser.open_new_tab('https://www.163.com/') else: webbrowser.open_new_tab('https://www.baidu.com/s?wd=%s' % text)if __name__ == '__main__': flag = 'y' while flag.lower() == 'y': print('请输入数字选择语言:') devpid = input('1536:普通话(简单英文),1537:普通话(有标点),1737:英语,1637:粤语,1837:四川话\n') my_record() TOKEN = getToken(HOST) speech = get_audio(FILEPATH) result = speech3text(speech, TOKEN, int(devpid)) print(result) if type(result) == str: openbrowser(result.strip(',')) flag = input('Continue?(y/n):')经测试,大吼效果更佳 。
看完上述内容,你们掌握Python调用百度api怎么实现语音识别的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注编程网Python频道,感谢各位的阅读!
--结束END--
本文标题: Python调用百度api怎么实现语音识别
本文链接: https://lsjlt.com/news/301382.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0