本篇内容介绍了“并发编程LongAdder的原理是什么”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!目录一、前言二、LongAdder类的使
本篇内容介绍了“并发编程LongAdder的原理是什么”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
一、前言
二、LongAdder类的使用
三、LongAdder原理的直观理解
四、源码分析
五、与AtomicInteger的比较
六、思想的抽象
ConcurrentHashMap的源码采用了一种比较独特的方式对map中的元素数量进行统计,自然是要好好研究一下其原理思想,同时也能更好地理解ConcurrentHashMap本身。
本文主要思路分为以下5个部分:
计数的使用效果
原理的直观图解
源码的细节分析
与AtomicInteger的比较
思想的抽象
学习的入口自然是map的put方法
public V put(K key, V value) { return putVal(key, value, false);}查看putVal方法
这里并不对ConcurrentHashMap本身的原理作过多讨论,因此我们直接跳到计数部分
final V putVal(K key, V value, boolean onlyIfAbsent) { ... addCount(1L, binCount); return null;}每当成功添加一个元素之后,都会调用addCount方法进行数量的累加1的操作,这就是我们研究的目标
因为ConcurrentHashMap的设计初衷就是为了解决多线程并发场景下的map操作,因此在作数值累加的时候自然也要考虑线程安全
当然,多线程数值累加一般是学习并发编程的第一课,本身并非很复杂,可以采用AtomicInteger或者锁等等方式来解决该问题
然而如果我们查看该方法,就会发现,一个想来应该比较简单的累加方法,其逻辑看上去却相当复杂
这里我只贴出了累加算法的核心部分
private final void addCount(long x, int check) { CounterCell[] as; long b, s; if ((as = counterCells) != null || !U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) { CounterCell a; long v; int m; boolean uncontended = true; if (as == null || (m = as.length - 1) < 0 || (a = as[ThreadLocalRandom.getProbe() & m]) == null || !(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) { fullAddCount(x, uncontended); return; } if (check <= 1) return; s = sumCount(); } ...}我们就来研究一下该逻辑的实现思路。而这个思路其实是照搬了LongAdder类的逻辑,因此我们直接查看该算法的原始类
我们先看下LongAdder的使用效果
LongAdder adder = new LongAdder();int num = 0;@Testpublic void test5() throws InterruptedException { Thread[] threads = new Thread[10]; for (int i = 0; i < 10; i++) { threads[i] = new Thread(() -> { for (int j = 0; j < 10000; j++) { adder.add(1); num += 1; } }); threads[i].start(); } for (int i = 0; i < 10; i++) { threads[i].join(); } System.out.println("adder:" + adder); System.out.println("num:" + num);}输出结果
adder:100000
num:40982
可以看到adder在使用效果上是可以保证累加的线程安全的
为了更好地对源码进行分析,我们需要先从直觉上理解它的原理,否则直接看代码的话会一脸懵逼
LongAdder的计数主要分为2个对象
一个long类型的字段:base
一个Cell对象数组,Cell对象中就维护了一个long类型的字段value,用来计数
transient volatile Cell[] cells;transient volatile long base;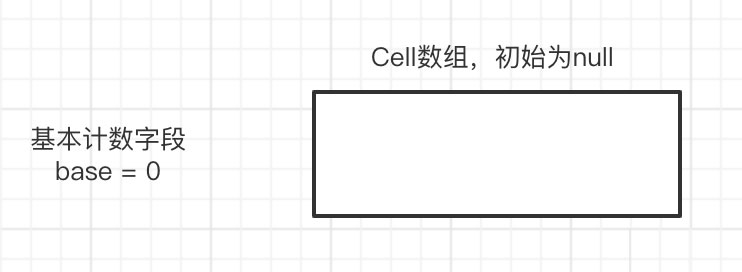
当没有发生线程竞争的时候,累加都会发生在base字段上,这就相当于是一个单线程累加2次,只不过base的累加是一个cas操作
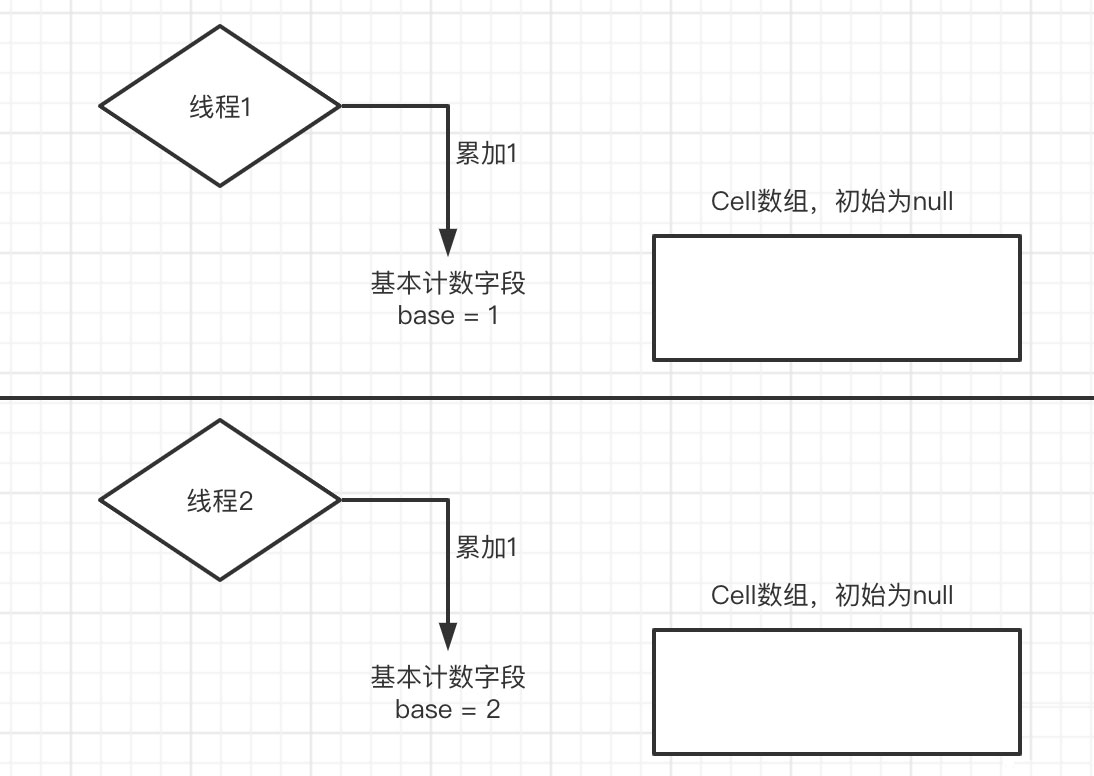
当发生线程竞争的时候,必然有一个线程对base的cas累加操作失败,于是它先去判断Cell是否已经被初始化了,如果没有则初始化一个长度为2的数组,并根据线程的hash值找到对应的数组索引,并对该索引的Cell对象中的value值进行累加(这个累加也是cas的操作)
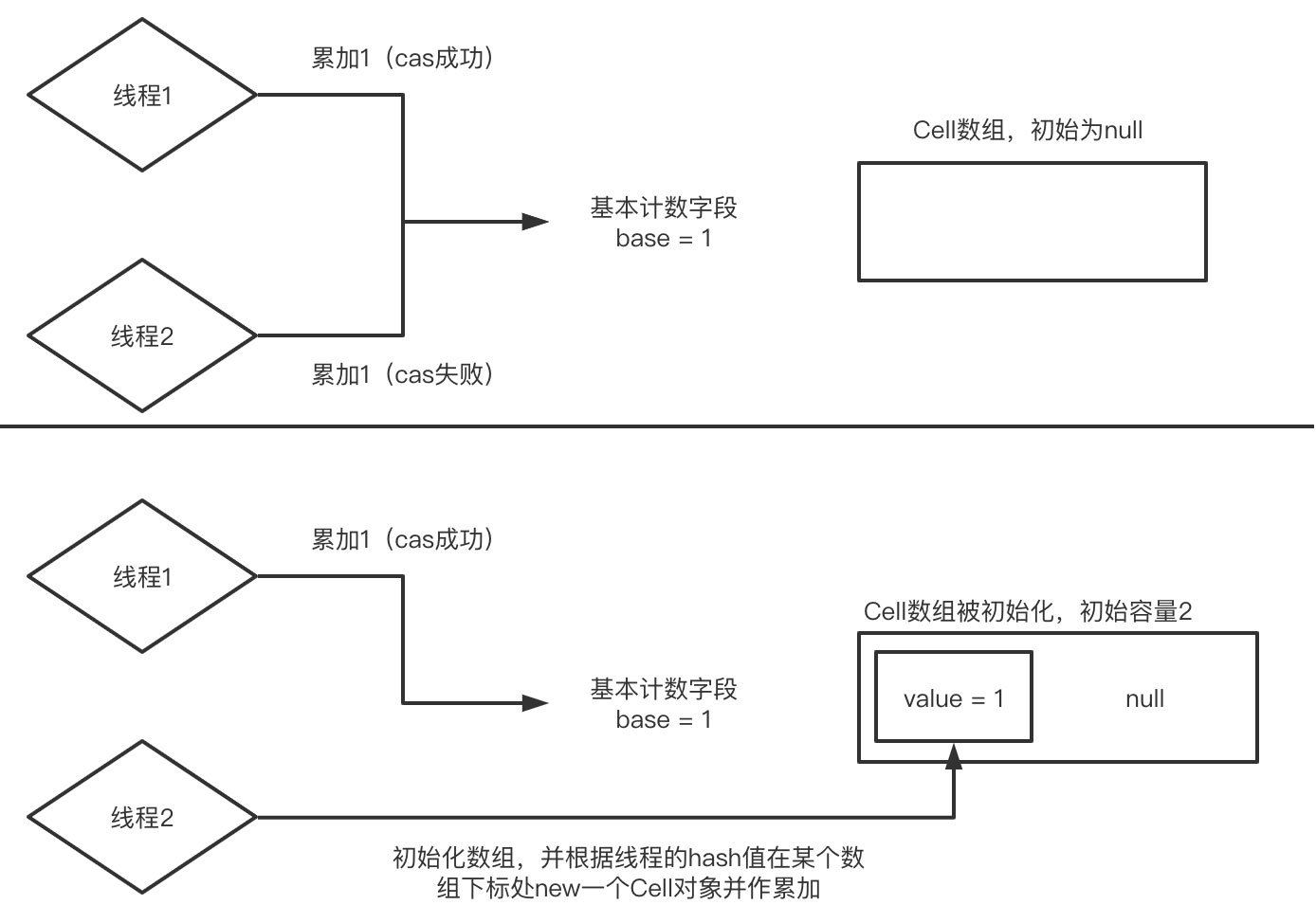
如果一共有3个线程发生了竞争,那么其中第一个线程对base的cas累加成功,剩下2个线程都需要去对Cell数组中的元素进行累加。因为对Cell中value值的累加也是一个cas操作,如果第二个线程和第三个线程的hash值对应的数组下标是同一个,那么同样会发生竞争,如果第二个线程成功了,第三个线程就会去rehash自己的hash值,如果得到的新的hash值对应的是另一个元素为null的数组下标,那么就new一个Cell对象并对value值进行累加
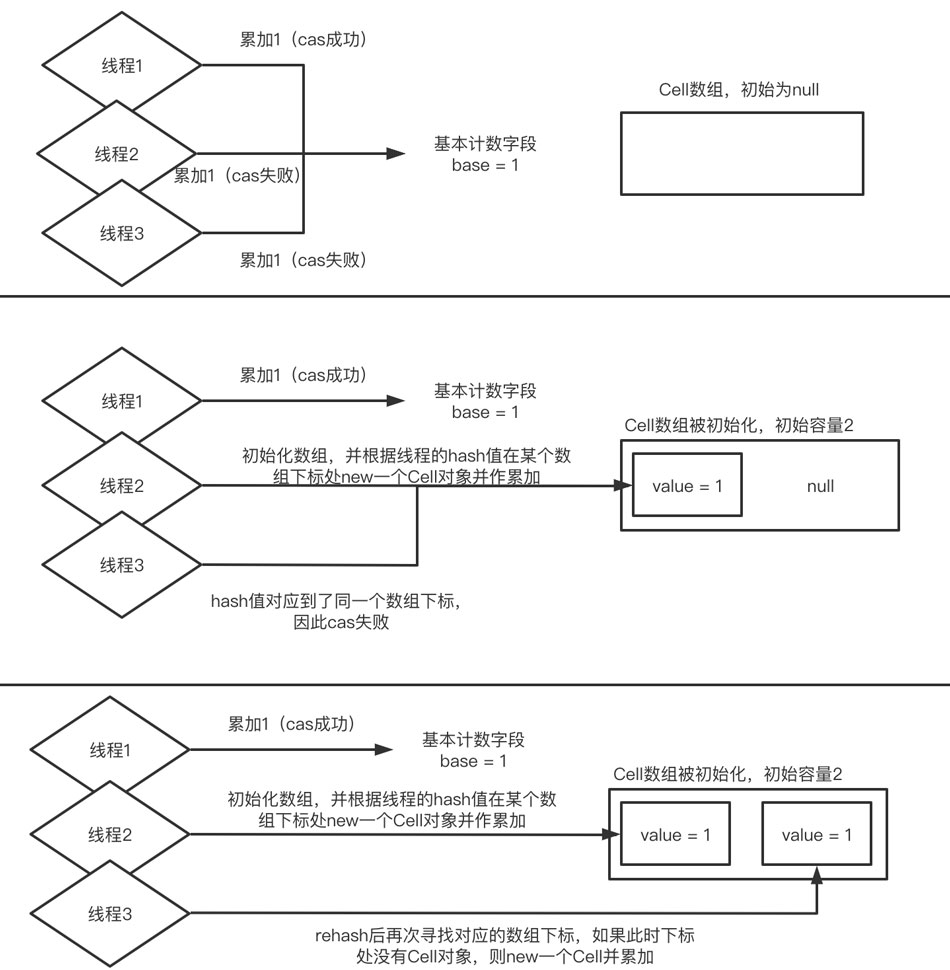
如果此时有线程4同时参与竞争,那么对于线程4来说,即使rehash后还是可能在和线程3的竞争过程中cas失败,此时如果当前数组的容量小于系统可用的cpu的数量,那么它就会对数组进行扩容,之后再次rehash,重复尝试对Cell数组中某个下标对象的累加
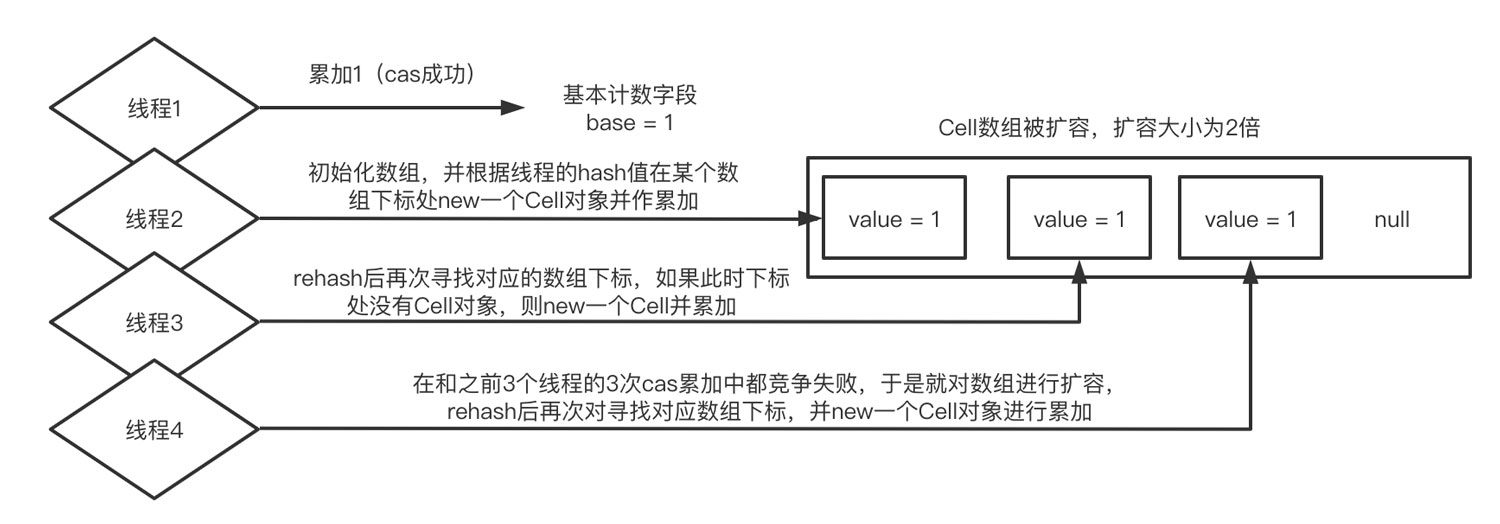
以上就是整体直觉上的理解,然而代码中还有很多细节的设计非常值得学习,所以我们就开始进入源码分析的环节
入口方法是add
public void add(long x) { Cell[] as; long b, v; int m; Cell a; if ((as = cells) != null || !casBase(b = base, b + x)) { boolean uncontended = true; if (as == null || (m = as.length - 1) < 0 || (a = as[getProbe() & m]) == null || !(uncontended = a.cas(v = a.value, v + x))) longAccumulate(x, null, uncontended); }}当不发生线程竞争的时候,那累加操作就会由第一个if中的casBase负责,对应之前图解的情况一
当发生线程竞争之后,累加操作就会由cell数组负责,对应之前图解的情况二(数组的初始化在longAccumulate方法中)
接着我们查看主逻辑方法,因为方法比较长,所以我会一段一段拿出来解析
longAccumulate方法
签名中的参数
x表示需要累加的值
fn表示需要如何累加,一般传null就行,不重要
wasUncontended表示是否在外层方法遇到了竞争失败的情况,因为外层的判断逻辑是多个“或”(as == null || (m = as.length - 1) < 0 || (a = as[getProbe() & m]) == null),所以如果数组为空或者相应的下标元素还未初始化,这个字段就会保持false
final void longAccumulate(long x, LongBinaryOperator fn, boolean wasUncontended) { ...}首先判断线程的hash值是否为0,如果为0则需要做一个初始化,即rehash
之后会将wasUncontended置为true,因为即使之前是冲突过的,经过rehash后就会先假设它能找到一个元素不冲突的数组下标
int h;//线程的hash值,在后面的逻辑中会用到if ((h = getProbe()) == 0) { ThreadLocalRandom.current(); // force initialization h = getProbe(); wasUncontended = true;}之后是一个死循环,死循环中有3个大的if分支,这3个分支的逻辑作用于数组未初始化的时候,一旦数组初始化完成,那么就都会进入主逻辑了,因此我这里把主逻辑抽取出来放到后面单独说,也可以避免外层分支对思路的影响
boolean collide = false;for (; ; ) { Cell[] as; Cell a; int n;//cell数组长度 long v;//需要被累积的值 if ((as = cells) != null && (n = as.length) > 0) { ... } else if (cellsBusy == 0 && cells == as && casCellsBusy()) { boolean init = false; try { if (cells == as) { Cell[] rs = new Cell[2]; rs[h & 1] = new Cell(x); cells = rs; init = true; } } finally { cellsBusy = 0; } if (init) break; } else if (casBase(v = base, ((fn == null) ? v + x : fn.applyAsLong(v, x)))) break; // Fall back on using base}接着就看对cell数组元素进行累加的主逻辑
if ((as = cells) != null && (n = as.length) > 0) { if ((a = as[(n - 1) & h]) == null) { if (cellsBusy == 0) { Cell r = new Cell(x); if (cellsBusy == 0 && casCellsBusy()) { boolean created = false; try { Cell[] rs; int m, j; if ((rs = cells) != null && (m = rs.length) > 0 && rs[j = (m - 1) & h] == null) { rs[j] = r; created = true; } } finally { cellsBusy = 0; } if (created) break; continue; } } collide = false; } else if (!wasUncontended) wasUncontended = true; else if (a.cas(v = a.value, ((fn == null) ? v + x : fn.applyAsLong(v, x)))) break; else if (n >= NCPU || cells != as) collide = false; else if (!collide) collide = true; else if (cellsBusy == 0 && casCellsBusy()) { try { if (cells == as) { Cell[] rs = new Cell[n << 1]; for (int i = 0; i < n; ++i) rs[i] = as[i]; cells = rs; } } finally { cellsBusy = 0; } collide = false; continue; } h = advanceProbe(h);}到这里LongAdder的源码其实就分析结束了,其实代码并不多,但是他的思想非常值得我们去学习。
光分析源码其实还差一些感觉,我们还没有搞懂为何作者要在已经有AtomicInteger的情况下,再设计这么一个看上去非常复杂的类。
那么首先我们先分析下AtomicInteger保证线程安全的原理
查看最基本的getAndIncrement方法
public final int getAndIncrement() { return unsafe.getAndAddInt(this, valueOffset, 1);}调用了Unsafe类的getAndAddInt方法,继续往下看
public final int getAndAddInt(Object var1, long var2, int var4) { int var5; do { var5 = this.getIntVolatile(var1, var2); } while(!this.compareAndSwapint(var1, var2, var5, var5 + var4)); return var5;}这里我们不再深究getIntVolatile和compareAndSwapInt方法具体实现,因为其已经是native的方法了
可以看到,AtomicInteger底层是使用了cas+自旋的方式解决原子性问题的,即如果一次赋值不成功,那么就自旋,直到赋值成功为止
那么由此可以推断,当出现大量线程并发,竞争非常激烈的时候,AtomicInteger就有可能导致有些线程不断地竞争失败,不断自旋从而影响任务的吞吐量
为了解决高并发下的自旋问题,LongAdder的作者在设计的时候就通过增加一个数组的方式,使得竞争的对象从一个值变成多个值,从而使得发生竞争的频率降低,从而缓解了自旋的问题,当然付出的代价就是额外的存储空间。
最后我简单做了个测试,比较2种计数方法的耗时
通过原理可知,只有当线程竞争非常激烈的时候,LongAdder的优势才会比较明显,因此这里我用了100个线程,每一个线程对同一个数累加1000000次,得到结果如下,差距非常巨大,达到15倍!
LongAdder耗时:104292242nanos
AtomicInteger耗时:1583294474nanos
当然这只是一个简单测试,包含了很多随机性,有兴趣的同学可以尝试不同的竞争程度多次测试
最后我们需要将作者的具体代码和实现逻辑抽象一下,理清思考的过程
1)AtomicInteger遇到的问题:单个资源的竞争导致自旋的发生
2)解决的思路:将单个对象的竞争扩展为多个对象的竞争(有那么一些分治的思想)
3)扩展的可控性:多个竞争对象需要付出额外的存储空间,因此不能无脑地扩展(极端情况是一个线程一个计数的对象,这明显不合理)
4)问题的分层:因为使用类的时候的场景是不可控的,因此需要根据并发的激烈程度动态地扩展额外的存储空间(类似于synchronized的膨胀)
5)3个分层策略:当不发生竞争时,那么用一个值累加即可;当发生一定程度的竞争时,创建一个容量为2的数组,使得竞争的资源扩展为3个;当竞争更加激烈时,则继续扩展数组(对应图解中的1个线程到4个线程的过程)
6)策略细节:在自旋的时候增加rehash,此时虽然付出了一定的运算时间计算hash、比较数组对象等,但是这会使得并发的线程尽快地找到专属于自己的对象,在之后就不会再发生任何竞争(磨刀不误砍柴工,特别注意wasUncontended字段的相关注解)
“并发编程LongAdder的原理是什么”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注编程网网站,小编将为大家输出更多高质量的实用文章!
--结束END--
本文标题: 并发编程LongAdder的原理是什么
本文链接: https://lsjlt.com/news/296527.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0