Python 官方文档:入门教程 => 点击学习
python中怎么利用多线程实现生产者消费者模式,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。什么是生产者消费者模式在软件开发的过程中,经常碰到这样的场景:某些模块负责生产数据
python中怎么利用多线程实现生产者消费者模式,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
什么是生产者消费者模式
在软件开发的过程中,经常碰到这样的场景:
某些模块负责生产数据,这些数据由其他模块来负责处理(此处的模块可能是:函数、线程、进程等)。产生数据的模块称为生产者,而处理数据的模块称为消费者。在生产者与消费者之间的缓冲区称之为仓库。生产者负责往仓库运输商品,而消费者负责从仓库里取出商品,这就构成了生产者消费者模式。
结构图如下:
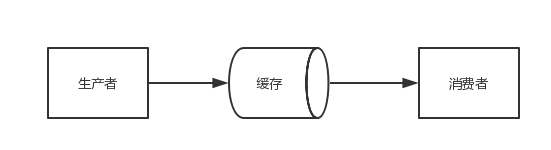
为了大家容易理解,我们举一个寄信的例子。假设你要寄一封信,大致过程如下:
你把信写好——相当于生产者生产数据
你把信放入邮箱——相当于生产者把数据放入缓冲区
邮递员把信从邮箱取出,做相应处理——相当于消费者把数据取出缓冲区,处理数据
生产者消费者模式的优点
解耦
假设生产者和消费者分别是两个线程。如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(也就是耦合)。如果未来消费者的代码发生变化,可能会影响到生产者的代码。而如果两者都依赖于某个缓冲区,两者之间不直接依赖,耦合也就相应降低了。
举个例子,我们去邮局投递信件,如果不使用邮箱(也就是缓冲区),你必须得把信直接交给邮递员。有同学会说,直接给邮递员不是挺简单的嘛?其实不简单,你必须 得认识谁是邮递员,才能把信给他。这就产生了你和邮递员之间的依赖(相当于生产者和消费者的强耦合)。万一哪天邮递员 换人了,你还要重新认识一下(相当于消费者变化导致修改生产者代码)。而邮箱相对来说比较固定,你依赖它的成本就比较低(相当于和缓冲区之间的弱耦合)。
由于生产者与消费者是两个独立的并发体,他们之间是用缓冲区通信的,生产者只需要往缓冲区里丢数据,就可以继续生产下一个数据,而消费者只需要从缓冲区拿数据即可,这样就不会因为彼此的处理速度而发生阻塞。
继续上面的例子,如果我们不使用邮箱,就得在邮局等邮递员,直到他回来,把信件交给他,这期间我们啥事儿都不能干(也就是生产者阻塞)。或者邮递员得挨家挨户问,谁要寄信(相当于消费者轮询)。
支持忙闲不均
当生产者制造数据快的时候,消费者来不及处理,未处理的数据可以暂时存在缓冲区中,慢慢处理掉。而不至于因为消费者的性能造成数据丢失或影响生产者生产。
我们再拿寄信的例子,假设邮递员一次只能带走1000封信,万一碰上情人节(或是圣诞节)送贺卡,需要寄出去的信超过了1000封,这时候邮箱这个缓冲区就派上用场了。邮递员把来不及带走的信暂存在邮箱中,等下次过来时再拿走。
通过上面的介绍大家应该已经明白了生产者消费者模式。
Python中的多线程编程
在实现生产者消费者模式之前,我们先学习下Python中的多线程编程。
线程是操作系统直接支持的执行单元,高级语言通常都内置多线程的支持,Python也不例外,并且Python的线程是真正的Posix Thread,而不是模拟出来的线程。
Python的标准库提供了两个模块:_thread和threading,_thread是低级模块,threading是高级模块,对_thread进行了封装。绝大多数情况下,我们只需要使用threading这个高级模块。
下面我们先看一段在Python中实现多线程的代码。
import time,threading #线程代码 class TaskThread(threading.Thread): def __init__(self,name): threading.Thread.__init__(self,name=name) def run(self): print('thread %s is running...' % self.getName()) for i in range(6): print('thread %s >>> %s' % (self.getName(), i)) time.sleep(1) print('thread %s finished.' % self.getName()) taskthread = TaskThread('TaskThread') taskthread.start() taskthread.join()下面是程序的执行结果:
thread TaskThread is running... thread TaskThread >>> 0 thread TaskThread >>> 1 thread TaskThread >>> 2 thread TaskThread >>> 3 thread TaskThread >>> 4 thread TaskThread >>> 5 thread TaskThread finished.TaskThread类继承自threading模块中的Thread线程类。构造函数的name参数指定线程的名字,通过重载基类run函数实现具体任务。
在简单熟悉了Python的线程后,下面我们实现一个生产者消费者模式。
from Queue import Queue import random,threading,time #生产者类 class Producer(threading.Thread): def __init__(self, name,queue): threading.Thread.__init__(self, name=name) self.data=queue def run(self): for i in range(5): print("%s is producing %d to the queue!" % (self.getName(), i)) self.data.put(i) time.sleep(random.randrange(10)/5) print("%s finished!" % self.getName()) #消费者类 class Consumer(threading.Thread): def __init__(self,name,queue): threading.Thread.__init__(self,name=name) self.data=queue def run(self): for i in range(5): val = self.data.get() print("%s is consuming. %d in the queue is consumed!" % (self.getName(),val)) time.sleep(random.randrange(10)) print("%s finished!" % self.getName()) def main(): queue = Queue() producer = Producer('Producer',queue) consumer = Consumer('Consumer',queue) producer.start() consumer.start() producer.join() consumer.join() print 'All threads finished!' if __name__ == '__main__': main()执行结果可能如下:
Producer is producing 0 to the queue! Consumer is consuming. 0 in the queue is consumed! Producer is producing 1 to the queue! Producer is producing 2 to the queue! Consumer is consuming. 1 in the queue is consumed! Consumer is consuming. 2 in the queue is consumed! Producer is producing 3 to the queue! Producer is producing 4 to the queue! Producer finished! Consumer is consuming. 3 in the queue is consumed! Consumer is consuming. 4 in the queue is consumed! Consumer finished! All threads finished!看完上述内容,你们掌握Python中怎么利用多线程实现生产者消费者模式的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注编程网Python频道,感谢各位的阅读!
--结束END--
本文标题: Python中怎么利用多线程实现生产者消费者模式
本文链接: https://lsjlt.com/news/287056.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0