概述&背景 Mysql一直被人诟病没有实现HashJoin,最新发布的8.0.18已经带上了这个功能,令人欣喜。有时候在想,mysql为什么一直不支持HashJoin呢?我想可能是因为Mysql多用于简单的OLTP场景,并且在互联网应用居多
Mysql一直被人诟病没有实现HashJoin,最新发布的8.0.18已经带上了这个功能,令人欣喜。有时候在想,mysql为什么一直不支持HashJoin呢?我想可能是因为Mysql多用于简单的OLTP场景,并且在互联网应用居多,需求没那么紧急。另一方面可能是因为以前完全靠社区,这种演进速度毕竟有限,oracle收购MySQL后,MySQL的发版演进速度明显加快了很多。
HashJoin本身算法实现并不复杂,要说复杂,可能是优化器配套选择执行计划时,是否选择HashJoin,选择外表,内表可能更复杂一点。不管怎样现在已经有了HashJoin,优化器在选择Join算法时又多了一个选择。MySQL本着实用主义,相信这个功能增强也回应了一些质疑,有些功能不是没有能力做好,而是有它的优先级。
在8.0.18之前,MySQL只支持NestLoopJoin算法,最简单的就是Simple NestLoop Join,MySQL针对这个算法做了若干优化,实现了Block NestLoop Join,Index NestLoop Join和Batched Key Access等,有了这些优化,在一定程度上能缓解对HashJoin的迫切程度。下文会单独拿一个章节讲MySQL的这些Join优化,下面先讲HashJoin。
NestLoopJoin算法简单来说,就是双重循环,遍历外表(驱动表),对于外表的每一行记录,然后遍历内表,然后判断join条件是否符合,进而确定是否将记录吐出给上一个执行节点。从算法角度来说,这是一个M*N的复杂度。HashJoin是针对equal-join场景的优化,基本思想是,将外表数据load到内存,并建立hash表,这样只需要遍历一遍内表,就可以完成join操作,输出匹配的记录。如果数据能全部load到内存当然好,逻辑也简单,一般称这种join为CHJ(Classic Hash Join),之前MariaDB就已经实现了这种HashJoin算法。如果数据不能全部load到内存,就需要分批load进内存,然后分批join,下面具体介绍这几种join算法的实现。
HashJoin一般包括两个过程,创建hash表的build过程和探测hash表的probe过程。
1).build phase
遍历外表,以join条件为key,查询需要的列作为value创建hash表。这里涉及到一个选择外表的依据,主要是评估参与join的两个表(结果集)的大小来判断,谁小就选择谁,这样有限的内存更容易放下hash表。
2).probe phase
hash表build完成后,然后逐行遍历内表,对于内表的每个记录,对join条件计算hash值,并在hash表中查找,如果匹配,则输出,否则跳过。所有内表记录遍历完,则整个过程就结束了。过程参照下图,来源于MySQL官方博客
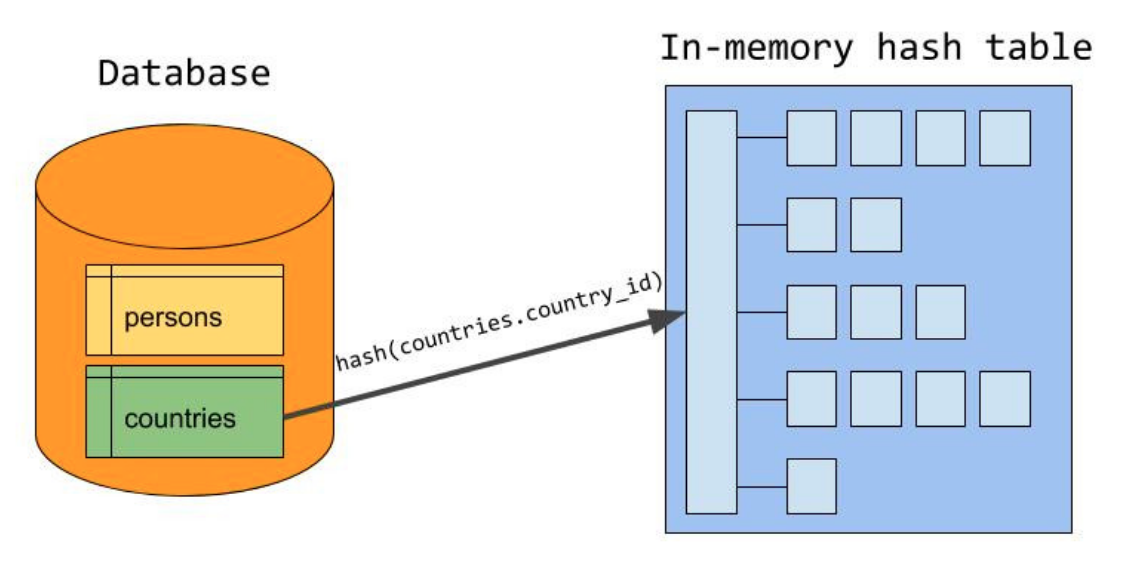

左侧是build过程,右侧是probe过程,country_id是equal_join条件,countries表是外表,persons表是内表。
CHJ的限制条件在于,要求内存能装下整个外表。在MySQL中,Join可以使用的内存通过参数join_buffer_size控制。如果join需要的内存超出了join_buffer_size,那么CHJ将无能为力,只能对外表分成若干段,每个分段逐一进行build过程,然后遍历内表对每个分段再进行一次probe过程。假设外表分成了N片,那么将扫描内表N次。这种方式当然是比较弱的。在MySQL8.0中,如果join需要内存超过了join_buffer_size,build阶段会首先利用hash算将外表进行分区,并产生临时分片写到磁盘上;然后在probe阶段,对于内表使用同样的hash算法进行分区。由于使用分片hash函数相同,那么key相同(join条件相同)必然在同一个分片编号中。接下来,再对外表和内表中相同分片编号的数据进行CHJ的过程,所有分片的CHJ做完,整个join过程就结束了。这种算法的代价是,对外表和内表分别进行了两次读io,一次写IO。相对于之之前需要N次扫描内表IO,现在的处理方式更好。
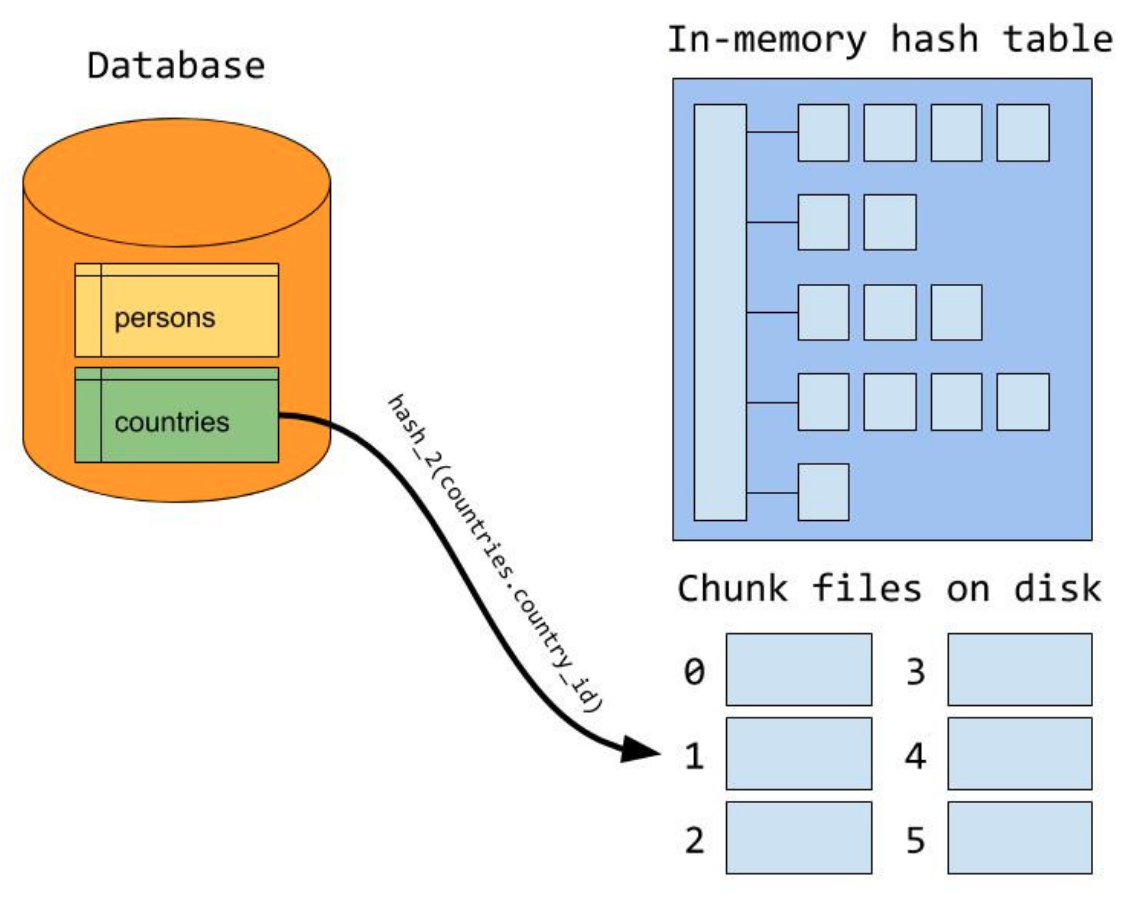

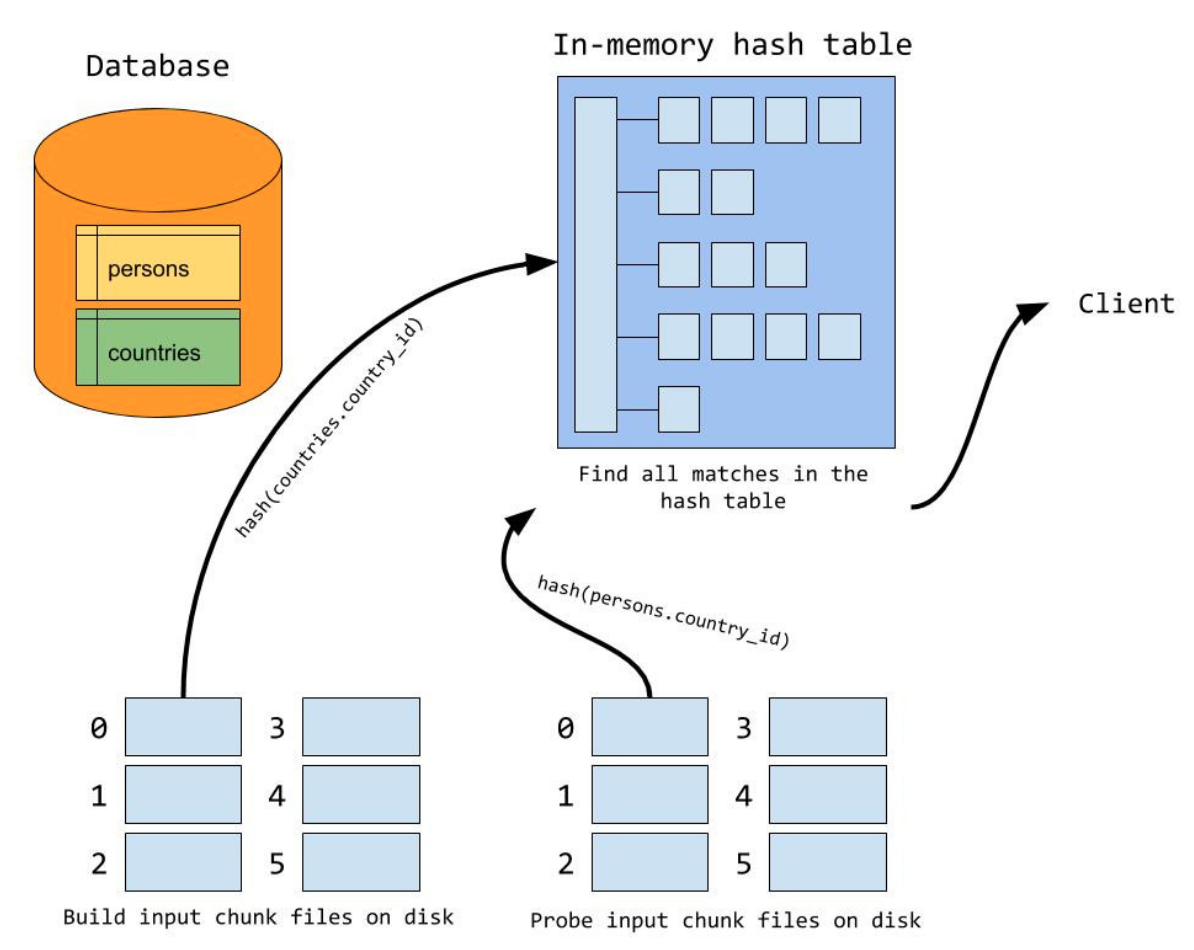
左上侧图是外表的分片过程,右上侧图是内表的分片过程,最下面的图是对分片进行build+probe过程。
主流的数据库Oracle,SQLServer,postgresql早就支持了HashJoin。Join算法都类似,这里介绍下Oracle使用的Grace Hash Join算法。其实整个过程与MySQL的HashJoin类似,主要有一点区别。当出现join_buffer_size不足时,MySQL会对外表进行分片,然后再进行CHJ过程。但是,极端情况下,如果数据分布不均匀,导致大量的数据hash后都分布在一个分桶中,导致分片后,join_buffer_size仍然不够,MySQL的处理方式是一次读分片读若干记录构建hash表,然后probe对应的外表分片。处理完一批后,清理hash表,重复上述过程,直到这个分片的所有数据处理完为止。这个过程与CHJ在join_buffer_size不足时,处理逻辑相同。
GraceHash在遇到这种情况时,会继续分片进行二次Hash,直到内存足够放下一个hash表为止。但是,这里仍然有极端情况,如果输入join条件都相同,那么无论进行多少次Hash,都没法分开,那么这个时候GraceHashJoin也退化成和MySQL的处理方式一样。
与GraceHashJoin的区别在于,如果缓存能缓存足够多的分片数据,会尽量缓存,那么就不必像GraceHash那样,严格地将所有分片都先读进内存,然后写到外存,然后再读进内存去走build过程。这个是在内存相对于分片比较充裕的情况下的一种优化,目的是为了减少磁盘的读写IO。目前Oceanbase的HashJoin采用的是这种join方式。
在MySQL8.0.18之前,也就是在很长一段时间内,MySQL数据库并没有HashJoin,主要的Join算法是NestLoopJoin。SimpleNestLoopJoin显然是很低效的,对内表需要进行N次全表扫描,实际复杂度是N*M,N是外表的记录数目,M是记录数,代表一次扫描内表的代价。为此,MySQL针对SimpleNestLoopJoin做了若干优化,下面贴的图片均来自网络。
MySQL采用了批量技术,即一次利用join_buffer_size缓存足够多的记录,每次遍历内表时,每条内表记录与这一批数据进行条件判断,这样就减少了扫描内表的次数,如果内表比较大,间接就缓解了IO的读压力。

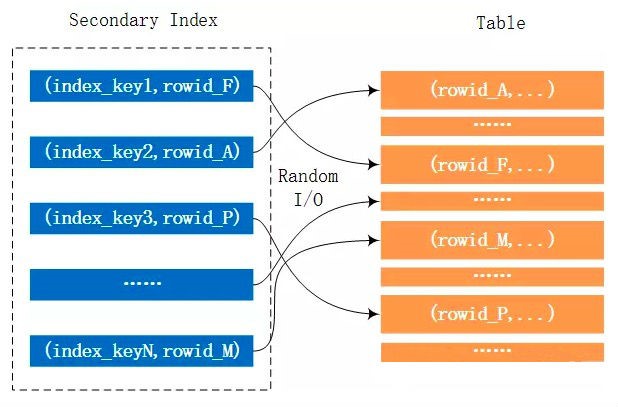
如果我们能对内表的join条件建立索引,那么对于外表的每条记录,无需再进行全表扫描内表,只需要一次Btree-Lookup即可,整体时间复杂度降低为N*O(logM)。对比HashJoin,对于外表每条记录,HashJoin是一次HashTable的search,当然HashTable也有build时间,还需要处理内存不足的情况,不一定比INLJ好。
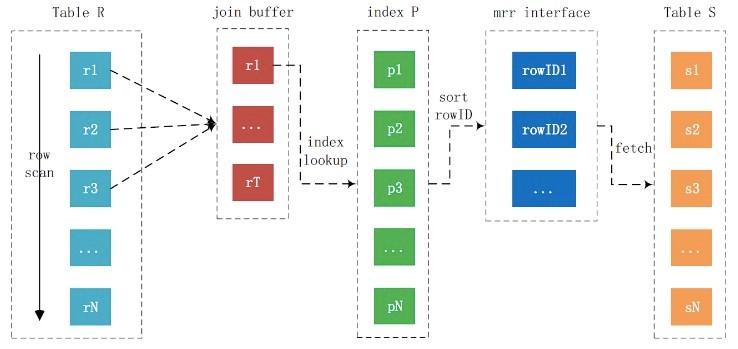
IndexNestLoopJoin利用join条件的索引,通过Btree-Lookup去匹配减少了遍历内表的代价。如果join条件是非主键列,那么意味着大量的回表和随机IO。BKA优化的做法是,将满足条件的一批数据按主键排序,这样回表时,从主键的角度来说就相对有序,缓解随机IO的代价。BKA实际上是利用了MRR特性(MultiRangeRead),访问数据之前,先将主键排序,然后再访问。主键排序的缓存大小通过参数read_rnd_buffer_size控制。
MySQL8.0以后,Server层代码做了大量的重构,虽然优化器相对于Oracle还有很大差距,但一直在进步。HashJoin的支持使得MySQL优化器有更多选择,SQL的执行路径也能做到更优,尤其是对于等值join的场景。虽然MySQL之前对于Join做过若干优化,比如NBLJ,INLJ以及BKA等,但这些代替不了HashJoin的作用。一个好用的数据库就应该具备丰富的基础能力,利用优化器分析出合适场景,然后拿出对应的基础能力以最高效的方式响应请求。
https://en.wikipedia.org/wiki/Hash_join
Https://mysqlserverteam.com/hash-join-in-mysql-8/
https://dev.mysql.com/worklog/task/?id=2241
https://www.cnblogs.com/qixinbo/p/10524142.html
https://zhuanlan.zhihu.com/p/35040231
--结束END--
本文标题: MySQL8.0 新特性 Hash Join
本文链接: https://lsjlt.com/news/2804.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0