本篇内容介绍了“linux中awk语法怎么使用”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!awk简介与表达式实例一种名字怪异的语言模式扫描
本篇内容介绍了“linux中awk语法怎么使用”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
一种名字怪异的语言
模式扫描和处理,处理数据和生成报告。
awk不仅仅是linux系统中的一个命令,而且是一种编程语言;它可以用来处理数据和生成报告(excel);处理的数据可以是一个或多个文件;可以是直接来自标准输入,也可以通过管道获取标准输入;awk可以在命令行上直接编辑命令进行操作,也可以编写成awk程序来进行更为复杂的运用。
sed处理stream editor文本流,水流。
本文涉及的awk为gawk,即GNU版本的awk。
[root@creditease awk]# cat /etc/redhat-releaseCentos Linux release 7.5.1804 (Core)[root@creditease awk]# uname -r3.10.0-862.el7.x86_64[root@creditease awk]# ll `which awk`lrwxrwxrwx. 1 root root 4 Nov 7 14:47 /usr/bin/awk -> gawk [root@creditease awk]# awk --versionGNU Awk 4.0.2awk指令是由模式、动作,或者模式和动作的组合组成。
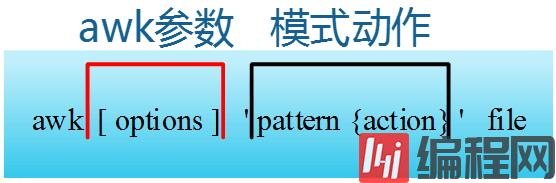
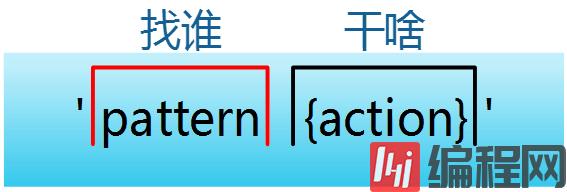
模式即pattern,可以类似理解成sed的模式匹配,可以由表达式组成,也可以是两个正斜杠之间的正则表达式。比如NR==1,这就是模式,可以把它理解为一个条件。
动作即action,是由在大括号里面的一条或多条语句组成,语句之间使用分号隔开。如下awk使用格式。
| 名称 | 含义 |
|---|---|
| record | 记录,行 |
| filed | 域,区域,字段,列 |
1)NF(number of field)表示一行中的区域(列)数量,$NF取最后一个区域。
2)$符号表示取某个列(区域),$1,$2,$NF
3)NR (number of record) 行号,awk对每一行的记录号都有一个内置变量NR来保存,每处理完一条记录NR的值就会自动+1
4)FS(-F)field separator 列分隔符,以什么把行分隔成多列
[root@creditease awk]# awk -F "#" '{print $NF}' awk.txt GKL$123GKL$213GKL$321[root@creditease awk]# awk -F '[#$]' '{print $NF}' awk.txt 123213321[root@creditease awk]# cat awk.txt ABC#DEF#GHI#GKL$123BAC#DEF#GHI#GKL$213CBA#DEF#GHI#GKL$321[root@creditease awk]# awk -F "#" 'NR==1{print $1}' awk.txtABC [root@creditease awk]# awk -F "#" 'NR==1' awk.txtABC#DEF#GHI#GKL$123默认会有动作{print $0}
[root@creditease awk]# awk -F "#" '{print $1}' awk.txtABCBACCAB默认处理所有行
[root@creditease awk]# awk -F "#" 'NR==1{print $NF}NR==3{print $NF}' awk.txt GKL$123GKL$321awk中$0表示整行
[root@creditease awk]# awk '{print $0}' awk_space.txtABC DEF GHI GKL$123BAC DEF GHI GKL$213CBA DEF GHI GKL$321FNR与NR类似,不过多文件记录不递增,每个文件都从1开始(后边处理多文件会讲到)
[root@creditease awk]# awk '{print NR}' awk.txt awk_space.txt 123456[root@creditease awk]# awk '{print FNR}' awk.txt awk_space.txt 123123awk同sed一样也可以通过模式匹配来对输入的文本进行匹配处理。 awk也支持大量的正则表达式模式,大部分与sed支持的元字符类似,而且正则表达式是玩转三剑客的必备工具。
awk支持的正则表达式元字符
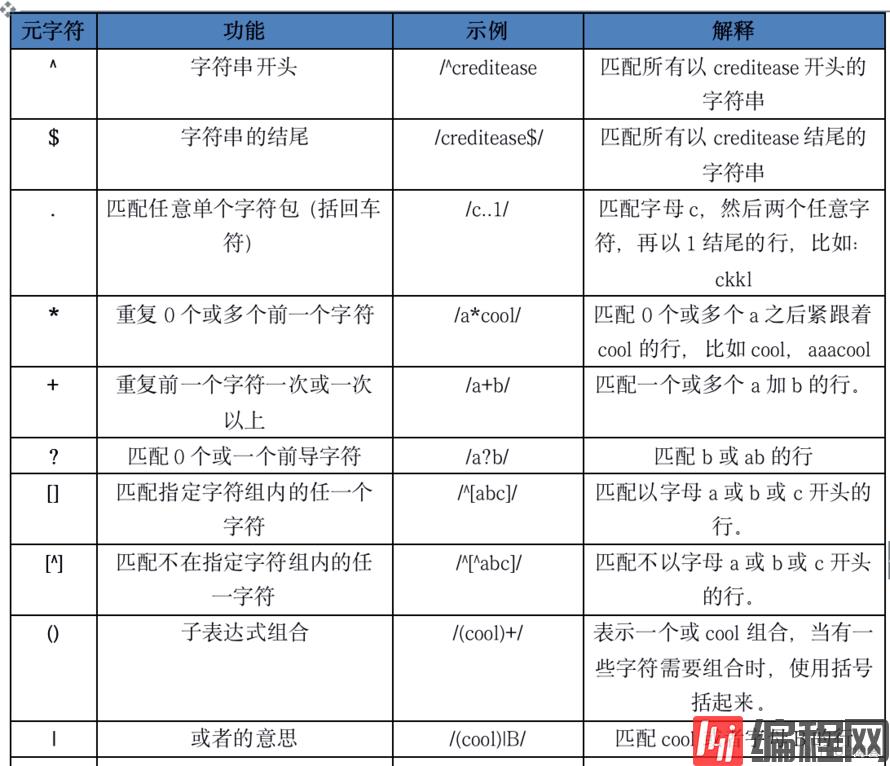
awk默认不支持的元字符,和需要添加参数才能支持的元字符
| 元字符 | 功能 | 示例 | 解释 |
|---|---|---|---|
| x{m} | x重复m次 | /cool{5}/ | 需要注意一点的是,cool加括号或不加括号的区别,x可以使字符串也可以只是一个字符,所以/cool{5}/表示匹配coo再加上5个l,即coolllll。/(cool){2,}/表示匹配coolcool,coolcoolcool等。 |
| x{m,} | x重复至少m次 | /(cool){2,}/ | 同上 |
| x{m,n} | x重复至少m次,但不超过n次,需要指定参数:--posix或者--re-interval。没有该参数不能使用这种模式 | /(cool){5,6}/ | 同上 |
正则表达式的运用,默认是在行内查找匹配的字符串,若有匹配则执行action操作,但是有时候仅需要固定的列表匹配指定的正则表达式。
比如:
我想取/etc/passwd文件中第五列($5)这一列查找匹配mail字符串的行,这样就需要用另外两个匹配操作符。并且awk里面只有这两个操作符来匹配正则表达式的。
| 正则匹配操作符 | |
|---|---|
| ~ | 用于对记录或区域的表达式进行匹配。 |
| !~ | 用于表达与~相反的意思。 |
1)显示awk.txt中GHI列
[root@creditease awk]# cat awk.txt ABC#DEF#GHI#GKL$123BAC#DEF#GHI#GKL$213CBA#DEF#GHI#GKL$321[root@creditease awk]# awk -F "#" '{print $3}' awk.txt GHIGHIGHI[root@creditease awk]# awk -F "#" '{print $(NF-1)}' awk.txt GHIGHIGHI2)显示包含321的行
[root@creditease awk]# awk '/321/{print $0}' awk.txt CBA#DEF#GHI#GKL$3213)以#为分隔符,显示第一列以B开头或最后一列以1结尾的行
[root@creditease awk]# awk -F "#" '$1~/^B/{print $0}$NF~/1$/{print $0}' awk.txt BAC#DEF#GHI#GKL$213CBA#DEF#GHI#GKL$3214)以#为分隔符,显示第一列以B或C开头的行
[root@creditease awk]# awk -F "#" '$1~/^B|^C/{print $0}' awk.txt BAC#DEF#GHI#GKL$213CBA#DEF#GHI#GKL$321[root@creditease awk]# awk -F "#" '$1~/^[BC]/{print $0}' awk.txt BAC#DEF#GHI#GKL$213CBA#DEF#GHI#GKL$321[root@creditease awk]# awk -F "#" '$1~/^(B|C)/{print $0}' awk.txt BAC#DEF#GHI#GKL$213CBA#DEF#GHI#GKL$321[root@creditease awk]# awk -F "#" '$1!~/^A/{print $0}' awk.txt BAC#DEF#GHI#GKL$213CBA#DEF#GHI#GKL$321awk是一种编程语言,能够进行更为复杂的判断,当条件为真时,awk就执行相关的action,主要是在针对某一区域做出相关的判断,比如打印成绩在80分以上的,这样就必须对这一个区域作比较判断.
下表列出了awk可以使用的关系运算符,可以用来比较数字字符串,还有正则表达式,当表达式为真的时候,表达式结果为1,否则为0,只有表达式为真,awk才执行相关的action。
awk支持的关系运算符
| 运算符 | 含义 | 示例 |
|---|---|---|
| < | 小于 | x>y |
| <= | 小于或等于。 | x<=y |
| == | 等于 | x==y |
| != | 不等于 | x!=y |
| >= | 大于或等于 | x>=y |
| > | 大于 | x<y |
显示awk.txt的第2 ,3 行
NR //,//
[root@creditease awk]# awk 'NR==2{print $0}NR==3{print $0}' awk.txt BAC#DEF#GHI#GKL$213CBA#DEF#GHI#GKL$321[root@creditease awk]# awk 'NR>=1{print $0}' awk.txt ABC#DEF#GHI#GKL$123BAC#DEF#GHI#GKL$213CBA#DEF#GHI#GKL$321[root@creditease awk]# awk '/BAC/,/CBA/{print $0}' awk.txt BAC#DEF#GHI#GKL$213CBA#DEF#GHI#GKL$321完整awk结构图如下:

BEGIN模块在awk读取文件之前就执行,BEGIN模式常常被用来修改内置变量ORS,RS,FS,OFS等的值。可以不接任何输入文件
| 变量名 | 属性 |
|---|---|
| $0 | 当前记录,一整行 |
| $1,$2,$3....$a | 当前记录的第n个区域,区域间由FS分隔。 |
| FS | 输入区域分隔符,默认是空格。field separator |
| NF | 当前记录中的区域个数,就是有多少列。number of field |
| NR | 已经读出的记录数,就是行号,从1开始。number of record |
| RS | 输入的记录分隔符默认为换行符。record separator |
| OFS | 输出区域分隔符,默认也是空格。output record separator |
| FNR | 当前文件的读入记录号,每个文件重新计算。 |
| FILENAME | 当前正在处理的文件的文件名 |
特别提示:FS RS支持正则表达式
[root@creditease awk]# awk 'BEGIN{RS="#"}{print $0}' awk.txt ABCDEFGHIGKL$123BACDEFGHIGKL$213CBADEFGHIGKL$321[root@creditease awk]# awk 'BEGIN{print "=======start======"}{print $0}' awk.txt =======start======ABC#DEF#GHI#GKL$123BAC#DEF#GHI#GKL$213CBA#DEF#GHI#GKL$321 [root@creditease files]# awk 'BEGIN{a=8;b=90;print a+b,a-c,a/b,a%b}'98 8 0.0888889 8END在awk读取完所有的文件的时候,再执行END模块,一般用来输出一个结果(累加,数组结果)。也可以是和BEGIN模块类似的结尾标识信息。
[root@creditease awk]# awk 'BEGIN{print "=======start======"}{print $0}END{print "=======end======"}' awk.txt=======start======ABC#DEF#GHI#GKL$123BAC#DEF#GHI#GKL$213CBA#DEF#GHI#GKL$321=======end======1)统计空行(/etc/services文件)
grep sed awk
[root@creditease awk]# grep "^$" /etc/services |wc -l17[root@creditease awk]# sed -n '/^$/p' /etc/services |wc -l17[root@creditease awk]# awk '/^$/' /etc/services |wc -l17[root@creditease awk]# awk '/^$/{i=i+1}END{print i}' /etc/services172)算术题
1+2+3......+100=5050,怎么用awk表示?
[root@creditease awk]# seq 100|awk '{i=i+$0}END{print i}'5050BEGIN和END模块只能有一个,BEGIN{}BEGIN{}或者END{}END{}都是错误的。
找谁干啥模块,可以是多个。
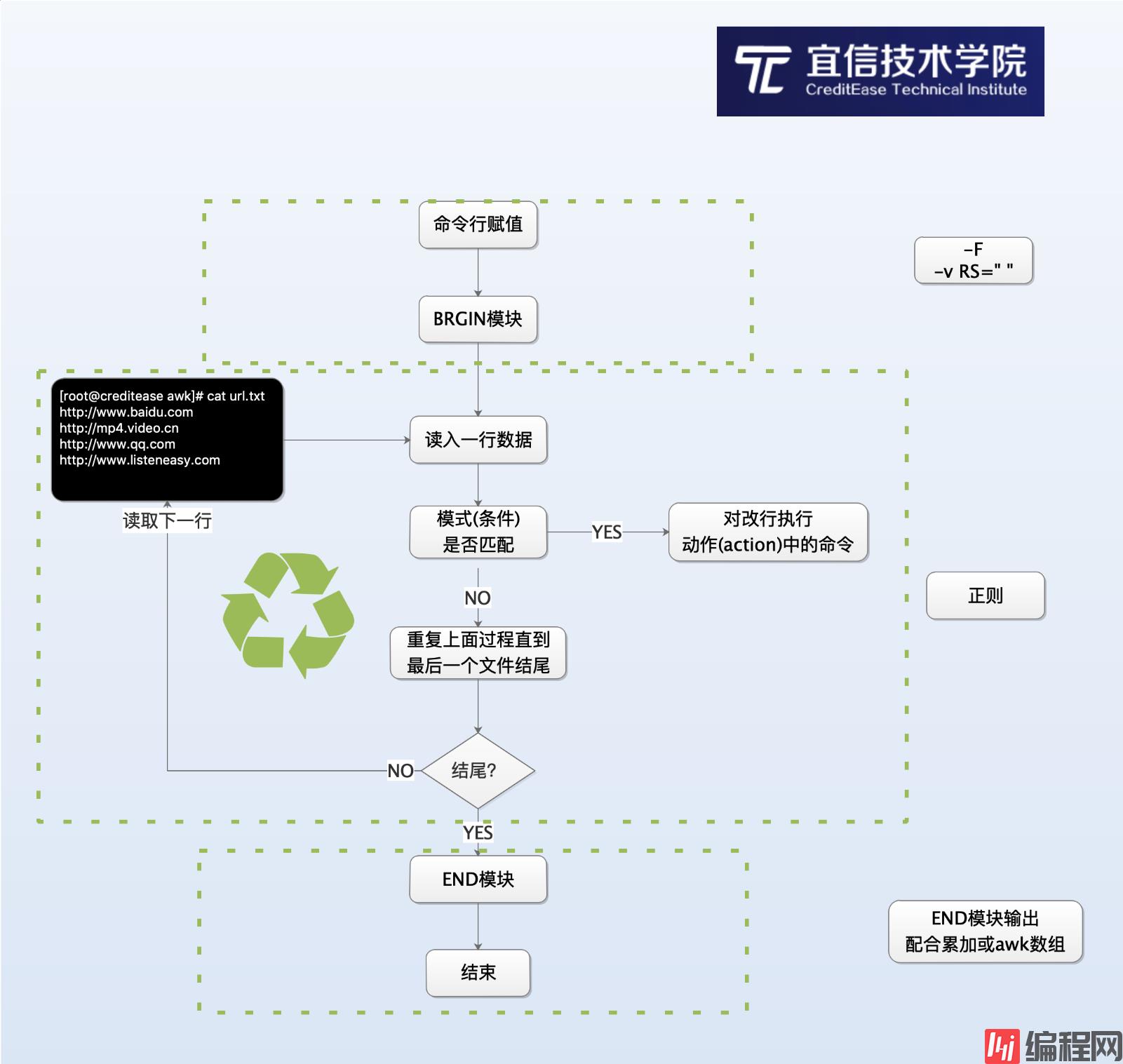
awk执行过程:
命令行的赋值(-F或-V)
执行BEGIN模式里面的内容
开始读取文件
判断条件(模式)是否成立
成立则执行对应动作里面的内容
读取下一行,循环判断
直到读取到最后一个文件的结尾
最后执行END模式里面的内容

people[police]=110
people[doctor]=120
[root@creditease awk]# awk 'BEGIN{Word[0]="credit";word[1]="easy";print word[0],word[1]}'credit easy[root@creditease awk]# awk 'BEGIN{word[0]="credit";word[1]="easy";for(i in word)print word[i]}'crediteasy索 引数组:以数字为下标
关联数组:以字符串为下标
现有如下文本,格式如下:即左边是随机字母,右边是随机数字, 即将相同的字母后面的数字加在一起,按字母的顺序输出
a 1b 3c 2d 7b 5a 3 g 2f 6以$1为下标,创建数组a[$1]=a[$1]+$2(a[$1]+=$2)然后配合END和for循环输出结果:
[root@creditease awk]# awk '{a[$1]=a[$1]+$2}END{for(i in a)print i,a[i]}' jia.txt a 4b 8c 2d 7f 6g 2注意:for(i in a) 循环的顺序不是按照文本内容的顺序来处理的,排序可以在命令后加sort排序以数字为下标的数组 seq生成1-10的数字,要求只显示计数行
[root@creditease awk]# seq 10|awk '{a[NR]=$0}END{for(i=1;i<=NR;i+=2){print a[i]}}'13579seq生成1-10的数字,要求不显示文件的后3行
[root@creditease awk]# seq 10|awk '{a[NR]=$0}END{for(i=1;i<=NR-3;i++){print a[i]}}'1234567解析:改变i的范围即可,多用于不显示文件的后几行a++ 和 ++a
[root@creditease awk]# awk 'BEGIN{print a++}'[root@creditease awk]# awk 'BEGIN{print ++a}'1[root@creditease awk]# awk 'BEGIN{a=1;b=a++;print a,b}'2 1[root@creditease awk]# awk 'BEGIN{a=1;b=++a;print a,b}'2 2注:都是 b = a+1b=a++ 先把 a 的值赋予b,然后 a + 1b=++a 先执行a+1,然后把a的值赋予b对一下文本进行去重处理 针对第二列去重
[root@creditease awk]# cat qc.txt 2018/10/20 xiaoli 133733050252018/10/25 xiaowang 177122159862018/11/01 xiaoliu 18615517895 2018/11/12 xiaoli 133733050252018/11/19 xiaozhao 155120132632018/11/26 xiaoliu 186155178952018/12/01 xiaoma 169655645252018/12/09 xiaowang 177122159862018/11/24 xiaozhao 15512013263解法一:[root@creditease awk]# awk '!a[$2]++' qc.txt 2018/10/20 xiaoli 133733050252018/10/25 xiaowang 177122159862018/11/01 xiaoliu 18615517895 2018/11/19 xiaozhao 155120132632018/12/01 xiaoma 16965564525解析:!a[$3]++是模式(条件),命令也可写成awk '!a[$3]=a[$3]+1{print $0}' qc.txta[$3]++ ,“++”在后,先取值后加一!a[$3]=a[$3]+1:是先取a[$3]的值,比较“!a[$3]”是否符合条件(条件非0),后加1注意:此方法去重后的结果显示的是文本开头开始的所有不重复的行解法二:[root@creditease awk]# awk '++a[$2]==1' qc.txt 2018/10/20 xiaoli 133733050252018/10/25 xiaowang 177122159862018/11/01 xiaoliu 18615517895 2018/11/19 xiaozhao 155120132632018/12/01 xiaoma 16965564525解析:++a[$3]==1是模式(条件),也可写成a[$3]=a[$3]+1==1即只有当条件(a[$3]+1的结果)为1的时候才打印出内容++a[$3] ,“++”在前,先加一后取值++a[$3]==1:是先加1,后取a[$3]的值,比较“++a[$3]”是否符合条件(值为1)注意:此方法去重后的结果显示的是文本开头开始的所有不重复的行解法三:[root@creditease awk]# awk '{a[$2]=$0}END{for(i in a){print a[i]}}' qc.txt2018/11/12 xiaoli 133733050252018/11/26 xiaoliu 186155178952018/12/01 xiaoma 169655645252018/12/09 xiaowang 177122159862018/11/24 xiaozhao 15512013263解析:注意此方法去重后的结果显示的是文本结尾开始的所有不重复的行使用awk取file.txt的第一列和file1.txt的第二列然后重定向到一个新文件new.txt中
[root@creditease awk]# cat file1.txt a bc de fg hi j[root@creditease awk]# cat file2.txt 1 23 45 67 89 10[root@creditease awk]# awk 'NR==FNR{a[FNR]=$1}NR!=FNR{print a[FNR],$2}' file1.txt file2.txt a 2c 4e 6g 8i 10解析:NR==FNR处理的是第一个文件,NR!=FNR处理的是第二个文件.注意:当两个文件NR(行数)不同的时候,需要把行数多的放前边.解决方法:把行数多的文件放前边,行数少的文件放后边.把输出的结果放入一个新文件new.txt中:[root@creditease awk]# awk 'NR==FNR{a[FNR]=$1}NR!=FNR{print a[FNR],$2>"new.txt"}' file1.txt file2.txt [root@creditease awk]# cat new.txt a 2c 4e 6g 8i 10[root@creditease awk]# cat url.txt Http://www.baidu.comhttp://mp4.video.cnhttp://www.qq.comhttp://www.listeneasy.comhttp://mp3.music.comhttp://www.qq.comhttp://www.qq.comhttp://www.listeneasy.comhttp://www.listeneasy.comhttp://mp4.video.cnhttp://mp3.music.comhttp://www.baidu.comhttp://www.baidu.comhttp://www.baidu.comhttp://www.baidu.com[root@creditease awk]# awk -F "[/]+" '{h[$2]++}END{for(i in h) print i,h[i]}' url.txtwww.qq.com 3www.baidu.com 5mp4.video.cn 2mp3.music.com 2www.crediteasy.com 3替换功能
格式:sub(r, s ,目标) gsub(r, s ,目标)
[root@creditease awk]# cat sub.txt ABC DEF AHI GKL$123BAC DEF AHI GKL$213CBA DEF GHI GKL$321[root@creditease awk]# awk '{sub(/A/,"a");print $0}' sub.txt aBC DEF AHI GKL$123BaC DEF AHI GKL$213CBa DEF GHI GKL$321[root@creditease awk]# awk '{gsub(/A/,"a");print $0}' sub.txt aBC DEF aHI GKL$123BaC DEF aHI GKL$213CBa DEF GHI GKL$321注:sub只会替换行内匹配的第一次内容;相当于sed ‘s###’ gsub 会替换行内匹配的所有内容;相当于sed ‘s###g’[root@creditease awk]# awk '{sub(/A/,"a",$1);print $0}' sub.txt aBC DEF AHI GKL$123BaC DEF AHI GKL$213CBa DEF GHI GKL$321练习:
0001|20081223efskjfdj|EREADFASDLKJCV0002|20081208djfksdaa|jdkFJALSDJFsddf0003|20081208efskjfdj|EREADFASDLKJCV0004|20081211djfksdaa1234|JDKFJALSDJFsddf以'|'为分隔, 现要将第二个域字母前的数字去掉,其他地方都不变, 输出为:0001|efskjfdj|EREADFASDLKJCV0002|djfksdaa|JDKFJALSDJFsddf0003|efskjfdj|EREADFASDLKJCV0004|djfksdaa1234|JDKFJALSDJFsddf方法:awk -F '|' 'BEGIN{OFS="|"}{sub(/[0-9]+/,"",$2);print $0}' sub_hm.txtawk -F '|' -v OFS="|" '{sub(/[0-9]+/,"",$2);print $0}' sub_hm.txt内容:
AA
BC
AA
CB
CC
AA
结果:
AA YES
BC NO YES
AA YES
CB NO YES
CC NO YES
AA YES
1) [root@creditease awk]# awk '{if($0~/AA/){print $0" YES"}else{print $0" NO YES"}}' ifelse.txt AA YESBC NO YESAA YESCB NO YESCC NO YESAA YES解析:使用if和else,if $0匹配到AA,则打印$0 "YES",else反之打印$0 " NO YES"。2)[root@creditease awk]# awk '$0~/AA/{print $0" YES"}$0!~/AA/{print $0" NO YES"}' ifelse.txt AA YESBC NO YESAA YESCB NO YESCC NO YESAA YES解析:使用正则匹配,当$0匹配AA时,打印出YES,反之,打印出“NO YES”如上题,用next来实现
next :跳过它后边的所有代码
[root@creditease awk]# awk '$0~/AA/{print $0" YES";next}{print $0" NO YES"}' ifelse.txt AA YESBC NO YESAA YESCB NO YESCC NO YESAA YES解析:{print $0" NO YES"}:此动作是默认执行的,当前边的$0~/AA/匹配,就会执行{print $0" YES";next}因为action中有next,所以会跳过后边的action。如果符合$0~/AA/则打印YES ,遇到next后,后边的动作不执行;如果不符合$0~/AA/,会执行next后边的动作;next前边的(模式匹配),后边的就不执行,前边的不执行(模式不匹配),后边的就执行。printf :打印后不换行
如下文本,如果 Description:之后为空,将其后一行内容并入此行。
Packages: Hello-1Owner: me me me meOther: who care?Description:Hello world!Other2: don't care想要结果:Packages: Hello-1Owner: me me me meOther: who care?Description: Hello world!Origial-Owner: me me me meOther2: don't care1)[root@creditease awk]# awk '/^Desc.*:$/{printf $0}!/Desc.*:$/{print $0}' printf.txt Packages: Hello-1Owner: me me me meOther: who care?Description:Hello world!Other2: don't care解析:使用正则匹配,匹配到'/^Desc.*:$/,就使用printf打印(不换行),不匹配的打印出整行。2)使用if和else实现[root@creditease awk]# awk '{if(/Des.*:$/){printf $0}else{print $0}}' printf.txt Packages: Hello-1Owner: me me me meOther: who care?Description:Hello world!Other2: don't care3)使用next实现[root@creditease awk]# awk '/Desc.*:$/{printf $0;next}{print $0}' printf.txt Packages: Hello-1Owner: me me me meOther: who care?Description:Hello world!Other2: don't care注:可简写成awk '/Desc.*:$/{printf $0;next}1'printf.txt ## 1是pattern(模式),默认action(动作)是{print $0}文本如下,要求计算出每项重复的个数,然后把重复次数大于2的放入gt2.txt文件中,把重复次数小于等于2的放入le2.txt文件中
[root@creditease files]# cat qcjs.txt aaabbbcccaaaDDDbbbrrrtttccceeedddrrrbbbrrrbbb[root@creditease awk]# awk '{a[$1]++}END{for(i in a){if(a[i]>2){print i,a[i]>"gt2.txt"}else{print i,a[i]>"le2.txt"}}}' qcjs.txt [root@creditease awk]# cat gt2.txt rrr 3bbb 4[root@creditease awk]# cat le2.txt aaa 2ccc 2eee 1ttt 1ddd 2解析:{print },或括号中打印后可直接重定向到一个新文件,文件名用双引号引起来。如: {print $1 >"xin.txt"}a)NR==FNR ##不能写成NR=FNR(=在awk中是赋值的意思)
b)NR!=FNR ##NR不等于FNR
c){a=1;a[NR]} 这样会报错:同一条命令中变量和数组名不能重复 d)printf 输出的时候不换行
e){print },或括号中打印后可直接重定向到一个新文件,文件名用双引号引起来。如: {print $1 >"xin.txt"}
f)当模式(条件)是0的时候,后边的动作不执行,!0的时候后边动作才执行。
“Linux中awk语法怎么使用”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注编程网网站,小编将为大家输出更多高质量的实用文章!
--结束END--
本文标题: Linux中awk语法怎么使用
本文链接: https://lsjlt.com/news/240452.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0