Hive方便地实现存储过程是怎样的,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。第一种是 HPL/sql。这种方式目前还不完善,比如游标使用限制多,很多功能无法实现,对变量
Hive方便地实现存储过程是怎样的,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
第一种是 HPL/sql。这种方式目前还不完善,比如游标使用限制多,很多功能无法实现,对变量要求严格,经常发生不兼容的错误。只要可调试,代码报错并非障碍,但 HPL/SQL 的问题在于不可调试,对于开发者就很不方便。
更不方便的是,HPL/SQL 缺乏 JDBC 接口,无法方便地嵌入 JAVA 程序,只能在 JAVA 中调用命令行执行 HPL/SQL,再由 HPL/SQL 实施计算并将结果回写 Hive 临时表,最后 JAVA 通过 Hive 的 JDBC 读取临时表。
第二种是用 JAVA 开发的 UDF 间接实现。JAVA 缺乏结构化计算类库,所有的算法都要硬编码,比如最基本的二维表要用 ArrayList+HashMap 组合实现,最简单的分组汇总要写几十行,关联计算更是冗长繁琐。由于硬编码很难统一规则,所以即使相似的业务逻辑,具体算法也是千差万别,这就导致代码可读性差、维护困难。
JAVA 存储过程还存在高耦合性的问题。JAVA 类无法进行热部署,每次修改都要重新编译并重启 Hive 服务,这会对生产环境产生严重影响。如果设计一个巧妙的结构,也许能降低耦合性,但项目成本必然大幅上升。
如果使用集算器,实现 Hive 存储过程就会方便很多。
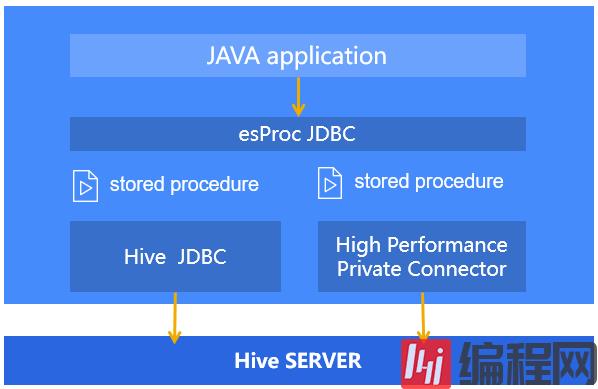
集算器具有丰富的结构化类库,无论查询、排序、聚合还是分组汇总、关联查询,都可以用内置函数直接实现。集算器也提供了针对结构化数据的分支判断、循环语句、动态语法,复杂业务逻辑也可轻松实现。集算器允许设置断点、跟踪调试,以便程序员快速排错。向上接口方面,集算器提供了标准的 JDBC 驱动,供 JAVA 代码调用,实际的存储过程则以脚本文件的形式存在,修改存储过程不影响 JAVA 代码或 Hive 服务。向下接口方面,集算器除了支持标准的 Hive JDBC,还提供了更高性能的私有接口,两者都可执行 HSQL 语句。
例子:Hive 中 sales 表按销售、年、月分组汇总后如下:
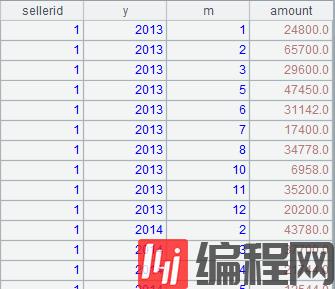
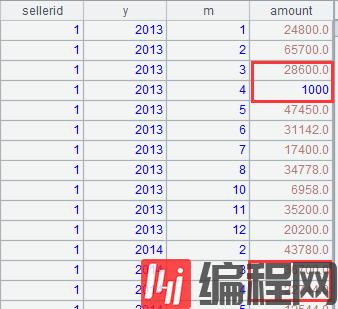
存储过程算法:调整每个销售 Q1Q2 的账务,具体是将 4 月份的 1000 元转移到 3 月份。要求对同一个销售同一年的数据做调整,如果 3 月份缺失,则调整时需在 3 月份追加 -1000 的空记录,以便平衡账务,如果 4 月份缺失,则调整时在 4 月份追加 1000 的空记录,都缺失则不做调整。
计算结果应当如下:
集算器存储过程如下:
| A | B | C | D | |
| 1 | =connect@l("hiveDB") | /connect to hive via jdbc | ||
| 2 | =A1.cursor@x("select sellerid,year(orderdate) y,month(orderdate) m,sum(amount)amount from sales group by sellerid,year(orderdate),month(orderdate) order by sellerid, year(orderdate),month(orderdate)") | /run HSQL | ||
| 3 | =A2.create() | /prepare a blank result | ||
| 4 | for A2;[sellerid,y] | /batch for every year of every seller | ||
| 5 | =A4.select(m==3) | =A4.select(m==4) | /reocrd of Mar. and Apr. | |
| 6 | if B5!=[] && C5!=[] | >B5.amount=B5.amount-1000 | /if both exist then modify batch | |
| 7 | >C5.amount=C5.amount+1000 | |||
| 8 | else if B5==[] &&C5!=[] | >A3.record([A4.sellerid,A4.y,3,-1000]) | /if Mar. not exists then add new reocord to result | |
| 9 | >C5.amount=C5.amount+1000 | /modify batch | ||
| 10 | else if B5!=[] &&C5==[] | >B5.amount=B5.amount-1000 | /if Apr. not exists then add new record to result | |
| 11 | >A3.record([A4.sellerid,A4.y,4,1000]) | /modify batch | ||
| 12 | >A3.paste@i(A4.(sellerid),A4.(y),A4.(m),A4.(amount)) | /uNIOn up this batch to result | ||
| 13 | return A3.sort(sellerid,y,m) | /sort and return result | ||
关于Hive方便地实现存储过程是怎样的问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注编程网精选频道了解更多相关知识。
--结束END--
本文标题: Hive方便地实现存储过程是怎样的
本文链接: https://lsjlt.com/news/235034.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0