这篇文章主要介绍“spark的基础知识点整理”,在日常操作中,相信很多人在spark的基础知识点整理问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”spark的基础知识点整理”的疑惑有所帮助!接下来,请跟着小编
这篇文章主要介绍“spark的基础知识点整理”,在日常操作中,相信很多人在spark的基础知识点整理问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”spark的基础知识点整理”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
一 .基础整理
{% asset_img 各种数据库之间的差别比较.png 这是一个新的博客的图片的说明 %}服务器本身不存储数据,数据本身放在HDFS中的,服务器只做功能的进行查,删改等功能
Hbase特性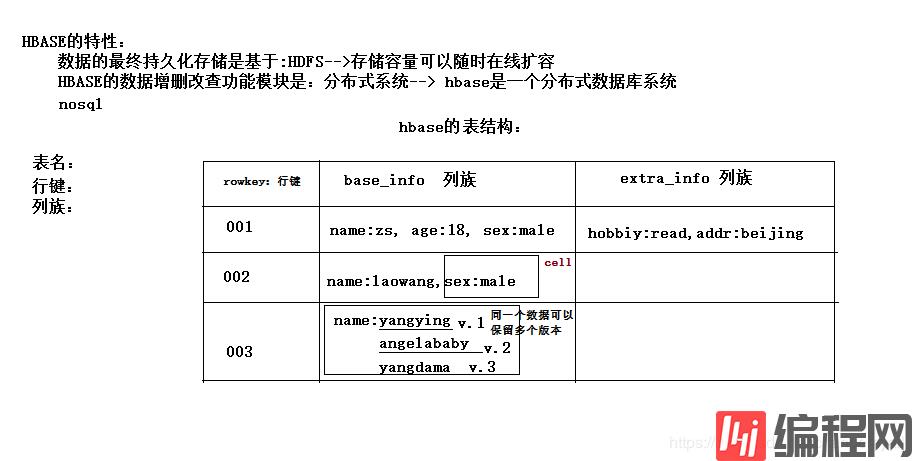
16010 对外访问端口
HBASE是一个数据库——可以提供数据的实时随机读写
Hbase:
hbase存储机制:面向列存储,table是按row排序。
Hbase的表没有固定的字段定义
Hbase的表在物理存储上,是按照列族来分割的,不同列族的数据一定存储在不同的文件中
Hbase的表中的每一行都固定有一个行键,而且每一行的行键在表中不能重复
Hbase中的数据,包含行键,包含key,包含value,都是byte[ ]类型,hbase不负责为用户维护数据类型
HBASE对事务的支持很差
Hbase的表中每行存储的都是一些key-value对
特征:
Hbase的表数据存储在HDFS文件系统中
存储容量可以线性扩展
数据存储的安全性可靠性极高
对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
主要用来存储结构化和半结构化的松散数据
Hbase查询数据功能很简单,不支持join等复杂操作,不支持复杂的事务(行级的事务)
与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
访问hbase table中的行,只有三种方式:
通过单个row key访问
通过row key的range
全表扫描
二 .集群搭建(完全分布式)
主机安装
jdk 安装
hadoop安装
环境变量
验证:hbase version
[hbase/conf/hbase-env.sh]
export JAVA_HOME=/soft/jdkexport HBASE_MANAGES_ZK=false[hbse-site.xml]
<!-- 使用完全分布式 --> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- 指定hbase数据在hdfs上的存放路径 --> <property> <name>hbase.rootdir</name> <value>hdfs://s201:8020/hbase</value> </property> <!-- 配置zk地址 --> <property> <name>hbase.ZooKeeper.quorum</name> <value>s201:2181,s202:2181,s203:2181</value> </property> <!-- zk的本地目录 --> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/Centos/zookeeper</value> </property>[hbase/conf/regionservers]
自己按需求设置
s202
s203
s204
启动hbase集群(s201)
start-hbase.sh
访问
Http://s201:16010
启动另一个master
hbase-daemon.sh start master
三.使用知识点
hbase shell 基本操作
scan ‘hbase:meta’ //查看元数据表
split ‘ns1:t1’ //切割表
help ‘list_namespace’ //查看特定的命令帮助
list_namespace //列出名字空间(数据库)
list_namespace_tables ‘defalut’ //列出名字空间(数据库)
create ‘ns1:t1’,’f1’ //创建表,指定空间下
put ‘ns1:t1’,’row1’,’f1:id’,100 //插入数据
get ‘ns1:t1’,’row1’ //查询指定row
scan ‘ns1:t1’ //扫描表
flush ‘ns1:t1’ //清理内存数据到磁盘。
count ‘ns1:t1’ //统计函数
disable ‘ns1:t1’ //删除表之前需要禁用表
help 帮助
drop ‘ns1:t1’
添加依赖
复制hbase集群的hbase-site.xml文件到模块的src/main/resources目录下
创建conf对象 Configuration conf = HBaseConfiguration.create();
通过连接工厂创建连接对象 Connection conn = ConnectionFactory.createConnection(conf);
通过连接查询tableName对象 TableName tname = TableName.valueOf(“ns1:t1”);
获得table Table table = conn.getTable(tname);
//创建conf对象 Configuration conf = HBaseConfiguration.create(); //通过连接工厂创建连接对象 Connection conn = ConnectionFactory.createConnection(conf); //通过连接查询tableName对象 TableName tname = TableName.valueOf("ns1:t1"); //获得table Table table = conn.getTable(tname); //通过bytes工具类创建字节数组(将字符串) byte[] rowid = Bytes.toBytes("row3"); //创建put对象 Put put = new Put(rowid); byte[] f1 = Bytes.toBytes("f1"); byte[] id = Bytes.toBytes("id") ; byte[] value = Bytes.toBytes(102); put.addColumn(f1,id,value); //执行插入 table.put(put);//创建conf对象 Configuration conf = HBaseConfiguration.create(); //通过连接工厂创建连接对象 Connection conn = ConnectionFactory.createConnection(conf); //通过连接查询tableName对象 TableName tname = TableName.valueOf("ns1:t1"); //获得table Table table = conn.getTable(tname); //通过bytes工具类创建字节数组(将字符串) byte[] rowid = Bytes.toBytes("row3"); Get get = new Get(Bytes.toBytes("row3")); Result r = table.get(get); byte[] idvalue = r.getValue(Bytes.toBytes("f1"),Bytes.toBytes("id")); System.out.println(Bytes.toInt(idvalue));Row Key
与nosql数据库们一样,row key是用来检索记录的主键。访问hbase table中的行,只有三种方式:
A:通过单个row key访问
B:通过row key的range
C:全表扫描
Row key行键 (Row key)可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10-100bytes)
在hbase内部,row key保存为字节数组
Hbase会对表中的数据按照rowkey排序(字典顺序)
存储时,数据按照Row key的字典序(byte order)排序存储。
设计key时,要充分排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)
字典序对int排序 : 注意要位数一样 例如10000 设置规则最好都是一样的如 0001 2000 这样的
表中的每一行有一个“行键rowkey”,而且行键在表中不能重复
表中的每一对kv数据称作一个cell,cell就是存储这些数据的一个类似封装对象,所有数据可以通过查询拿到
cell中的数据是没有类型的,全部是字节码形式存贮。、
由{row key, column( =
hbase可以对数据存储多个历史版本(历史版本数量都是可配置)
整张表由于数据量过大,会被横向切分成若干个region(用rowkey范围标识)不同region的数据也存储在不同文件中
hbase会对插入的数据按顺序存储:首先按行键排序,之后再按同一行里面的kv会按列族排序,再按k排序
hbase中只支持byte[] 此处的byte[] 包括了: rowkey,key,value,列族名,表名
hbase三级定位,行键,列,时间戳,列也可以是列族加列
hbase通过行键区分区域服务器,会切割每部分,每部分都有各自的范围,行键是有序的
插入到hbase中去的数据,hbase会自动排序存储
排序规则: 首先看行键,然后看列族名,然后看列(key)名; 按字典顺序
列族
hbase表中的每个列,都归属与某个列族。列族是表的schema的一部分(而列不是),必须在使用表之前定义。
列名都以列族作为前缀 例如:space:math 都属于 space这个列族
访问控制、磁盘和内存的使用统计都是在列族层面进行的。
列族越多,在取一行数据时所要参与IO、搜寻的文件就越多,所以,如果没有必要,不要设置太多的列族
写前日志
WAL //write ahead log,写前日志。
写前日志 WAL 主要是容错用的
你写数据的时候都会往这个表记录,所以他可能影响插入速度
代码:关闭写前日志可以提高插入速度,因为插入的时候都会往写前日志里记录
DecimalFORMat format2 = new DecimalFormat(); format2.applyPattern("0000"); long start = System.currentTimeMillis() ; Configuration configuration = HBaseConfiguration.create(); configuration.set("hbase.zookeeper.quorum","s202:2181,s203:2181,s204:2181"); Connection connection = ConnectionFactory.createConnection(configuration); TableName tableName =TableName.valueOf("new:t1"); HTable table = (HTable)connection.getTable(tableName); table.setAutoFlush(false); for (int i = 2 ; i <= 10000 ; i ++) { Put put = new Put(Bytes.toBytes("row" + format2.format(i))) ; //关闭写前日志 put.setWriteToWAL(false); put.addColumn(Bytes.toBytes("f1"),Bytes.toBytes("id"),Bytes.toBytes(i)); put.addColumn(Bytes.toBytes("f1"),Bytes.toBytes("name"),Bytes.toBytes("tom" + i)); put.addColumn(Bytes.toBytes("f1"),Bytes.toBytes("age"),Bytes.toBytes(i % 100)); table.put(put); if ( i % 2000 == 0 ) { table.flushCommits(); } } //不提交丢数据,最后不满足2000的会丢,不是自动提交 table.flushCommits(); System.out.println(System.currentTimeMillis() - start );存放位置
- 相同列族的数据存放在一个文件中 - [表数据的存储目录结构构成] - hdfs://s201:8020/hbase/data/${名字空间}/${表名}/${区域名称}/${列族名称}/${文件名} - [WAL目录结构构成] - hdfs://s201:8020/hbase/WALs/${区域服务器名称,主机名,端口号,时间戳}/联系zk,找出meta表所在rs(regionserver) /hbase/meta-region-server
定位row key,找到对应region server
缓存信息在本地。
联系RegionServer
HRegionServer负责open HRegion对象,为每个列族创建Store对象,Store包含多个StoreFile实例,
是对HFile的轻量级封装。每个Store还对应了一个MemStore,用于内存存储数据。
hbase切割文件配置位置:
hbase集群启动时,master负责分配区域到指定区域服务器。主要是把meta放入区域服务器
client端交互过程
Zookeeper 起的作用
保证任何时候,集群中只有一个master
存贮所有Region的寻址入口——root表在哪台服务器上
实时监控Region Server的状态,将Region server的上线和下线信息实时通知给Master
存储Hbase的schema,包括有哪些table,每个table有哪些column family
Master职责
为Region server分配region
负责region server的负载均衡
发现失效的region server并重新分配其上的region
HDFS上的垃圾文件回收
处理schema更新请求
master仅仅维护者table和region的元数据信息,负载很低。
Region Server职责
Region server维护Master分配给它的region,处理对这些region的IO请求
Region server负责切分在运行过程中变得过大的region
client访问hbase上数据的过程并不需要master参与
寻址访问zookeeper和region server
数据读写访问regione server
四.整体架构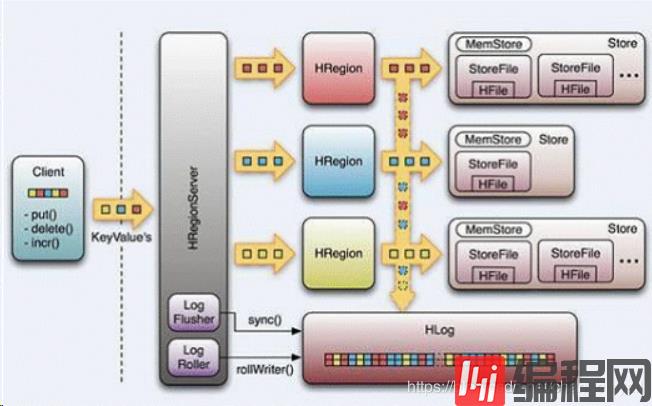
到此,关于“spark的基础知识点整理”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注编程网网站,小编会继续努力为大家带来更多实用的文章!
--结束END--
本文标题: spark的基础知识点整理
本文链接: https://lsjlt.com/news/230183.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0