Python 官方文档:入门教程 => 点击学习
本篇文章给大家分享的是有关python爬虫的工作原理是什么呢,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。随着计算机、互联网、物联网、云计算等网络技术的飞速发展,网络信息呈爆炸
本篇文章给大家分享的是有关python爬虫的工作原理是什么呢,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
随着计算机、互联网、物联网、云计算等网络技术的飞速发展,网络信息呈爆炸式增长。互联网的信息几乎囊括了社会、文化、政治、经济、娱乐等所有话题。人们生活水平的提高,生活质量要求也越来越高,智能手机随时随地人手一部,不管是手机界面呈现还是运行速度,体验感便捷度要求也越来越高。python的崛起,Python爬虫的崛起,更加高效的能将用户所关注的数据内容直接返回给用户,使用户在海量的数据内容中快速找到自己需要的内容。
很多伙伴也在学Python爬虫,但爬虫的工作原理你是否真的搞懂了呢?
Python爬虫的工作原理
网络爬虫通过统一资源定位符URL 来查找目标网页,将用户所关注的数据内容直接返回给用户,并不需要用户以浏览网页的形式去获取信息,为用户节省了时间和精力,并提高了数据采集的精准度,使用户在海量数据中很快找到自己需要的内容。网络爬虫的最终目的就是从网页中获取自己所需的信息。虽然利用urllib、urllib2、re等一些爬虫基本库可以开发一个爬虫程序,获取到所需的内容,但是所有的爬虫程序都以这种方式进行编写,工作量未免太大了些,所有才有了爬虫框架。使用爬虫框架可以大大提高效率,缩短开发时间。
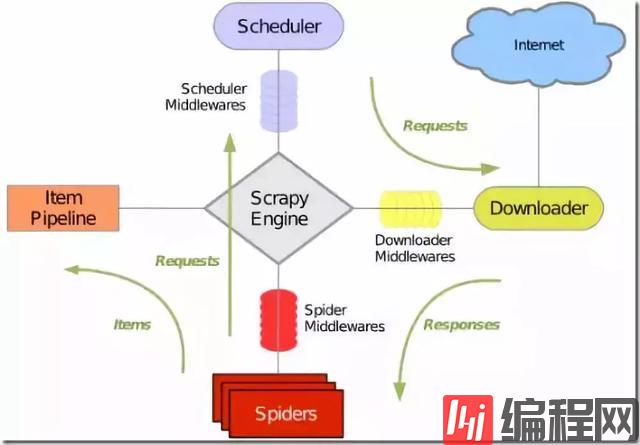
网络爬虫(WEB crawler)又称为网络蜘蛛(web spider)或网络机器人(web robot),另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或蠕虫,同时它也是“物联网”概念的核心之一。网络爬虫本质上是一段计算机程序或脚本,其按照一定的逻辑和算法规则自动地抓取和下载万维网的网页,是搜索引擎的一个重要组成部分。

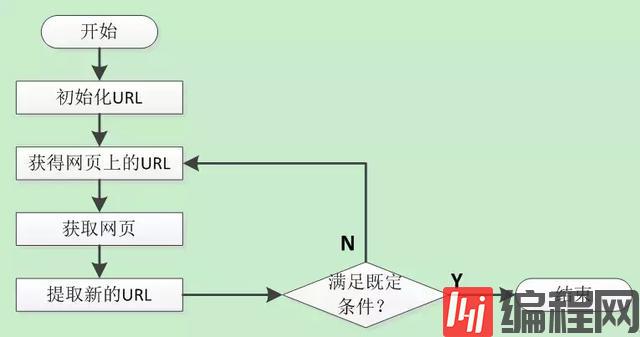
网络爬虫一般是根据预先设定的一个或若干个初始网页的URL开始,然后按照一定的规则爬取网页,获取初始网页上的URL列表,之后每当抓取一个网页时,爬虫会提取该网页新的URL并放入到未爬取的队列中去,然后循环的从未爬取的队列中取出一个URL再次进行新一轮的爬取,不断的重复上述过程,直到队列中的URL抓取完毕或者达到其他的既定条件,爬虫才会结束。具体流程如下图所示。
随着互联网信息的与日俱增,利用网络爬虫工具来获取所需信息必有用武之地。使用网络爬虫来采集信息,不仅可以实现对web上信息的高效、准确、自动的获取,还利于公司或者研究人员等对采集到的数据进行后续的挖掘分析。
以上就是Python爬虫的工作原理是什么呢,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注编程网Python频道。
--结束END--
本文标题: Python爬虫的工作原理是什么呢
本文链接: https://lsjlt.com/news/229242.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0