Python 官方文档:入门教程 => 点击学习
目录1、多表关联的嵌套查询2、注解3、动态sql1.if where2.trim3.choose when otherwise4.set5.foreach4、特殊符号处理5
将一个多表关联查询拆分为多次查询,先查询主表数据,然后查询关联表数据.
<association property="dept" javaType="Dept" select="findDeptByID" column="dept_id"></association>(1). select:指定关联查询对象的 Mapper Statement ID 为 findDeptByID
(2). column="dept_id":关联查询时将 dept_id 列的值传入 findDeptByID,
并将 findDeptByID 查询的结果映射到 Emp 的 dept 属性中
(3).collection 和 association 都需要配置 select 和 column 属性,两者配置方法
相同
一般写在Dao中接口的抽象方法的上面,可以代替简单的sql操作,比如一个简单的增加操作,这个时候在对应的mappers映射文件xml中就不需要在写<insert >标签了。

注:我们使用注解一般是简单的且只涉及一张表的操作,而涉及多张表的复杂操作我们还是在xml文件中设置
注:我们一般在定义类中的属性时,一般不定义基本类型,如int,我们需要定义成integer类型,即引用类型,因为引用类型的默认值都为null,这样在判断时就都为null了,就不需要每一种基本类型都使用不同的默认值
MyBatis 的一个强大的特性之一通常是它的动态 SQL 能力。 如果你有使用JDBC 或其他 相似框架的经验,你就明白条件地串联 SQL 字符串在一起是多么 的痛苦,确保不能忘了空格或在列表的最后省略逗号。动态 SQL 可以彻底处理 这种痛苦。
Mybatis实现动态sql的关键字有:
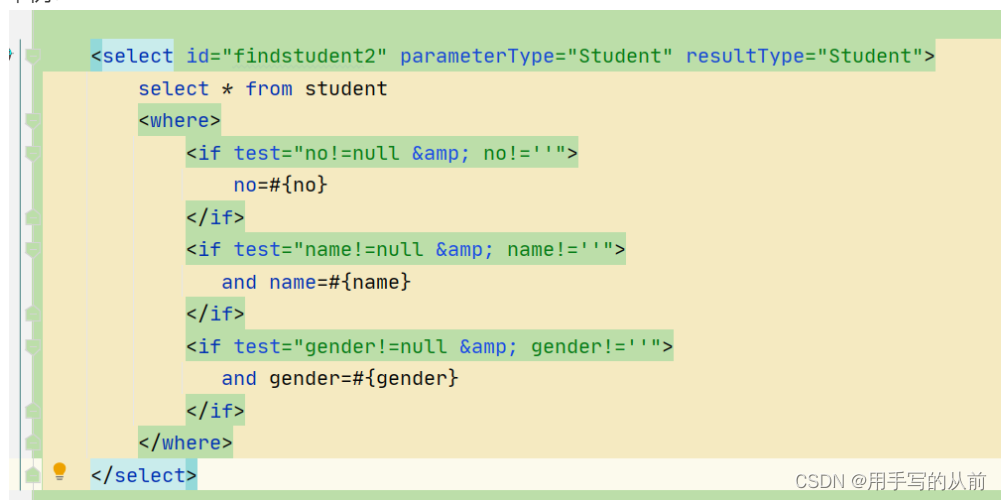
<if>标签会对传入的条件进行判断 ,如果满足条件,就将if标签中的sql语句与前面的sql语句进行拼接,不满足则跳过。
<where>标签会进行判断,如果它包含的子标签(一般是if)又返回值,就会在其前面插入一个‘where’,于此同时,他还会根据情况将子标签前面的and和or进行剔除
举例:
<trim> 标签的功能是可以实现代替其他标签的功能,但同时又比其他标签更加灵活
比如通过设置它的属性就可以实现where标签的功能
他有四个标签,分别是:prefix,prefixOverrides,suffix,suffixOverrides
若有<trim>子句</trim>:
prefix,suffix 是将其属性值分别放在子句之前和之后。
prefixOverrides,suffixOverrides是删除子句首和子句尾的指定内容。
例如where标签用trim来实现如下:
<trim prefix="WHERE" prefixOverrides="AND |OR "> ...</trim>choose标签实现多路选择,当choose下的when标签条件满足时,就将when中的sql拼进外面的sql,反之若不满足,则将下面的otherwise标签中的sql拼进总sql。
例如:

<set>标签是在我们进行update操作时使用。<set>子句</set>
它可以为我们删除子句尾的',',当子句中有内容时,会自生成set在子句首。
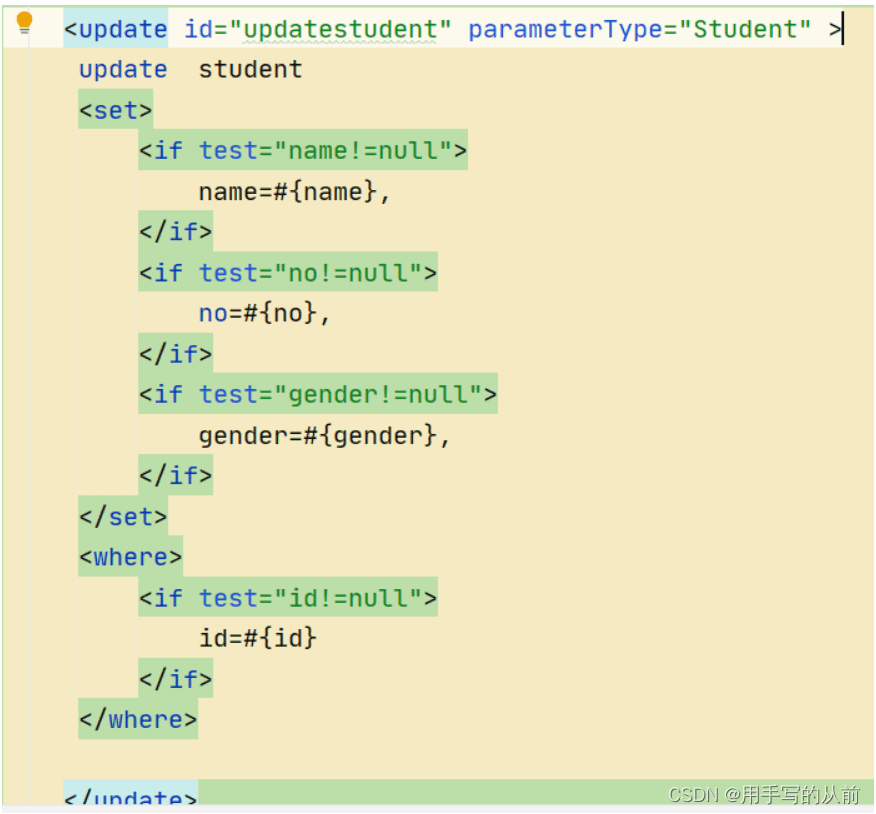
同样的,set标签也可以使用trim标签来代替,
<trim prefix="SET" suffixOverrides=","> 子句</trim>意思就是当子句中有内容时,会在子句首生成set,反之不生成;然后就是在删除字句尾的','
foreach标签的使用场景是对集合进行遍历,并可以自定义的设置
foreach 元素的功能非常强大,它允许你指定一个集合,声明可以在元素体内使用的集合项(item)和索引(index)变量。它也允许你指定开头与结尾的字符串以及各个元素之间的分隔符。这个元素也不会错误地添加多余的分隔符,看它多智能!
例如:
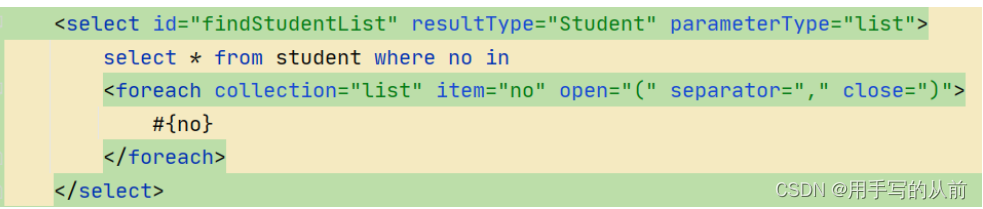
最终效果是:select * from student where no in (100,101)
在 mybatis 中的 xml 文件中,存在一些特殊的符号,比如:<、>、"、&、<> 等,正常书写 mybatis 会报错,需要对这些符号进行转义。具体转义如下所示:

除了可以使用上述转义字符外,还可以使用<![CDATA[]]>来包裹特殊字符。如
下所示:
<if test="id != null">
AND <![CDATA[ id <> #{id} ]]>
</if><![CDATA[ ]]>是 XML 语法。在 CDATA 内部的所有内容都会被解析器忽略。但是有个问题那就是 <if> </if> <where> </where>
<choose> </choose> <trim> </trim> 等这些标签都不会被解析,所以 我们只把有特殊字符的语句放在 <![CDATA[ ]]> 尽量缩小<![CDATA[ ]]> 的范围。
Mybatis缓存的作用是为了减轻数据库的压力,提高查询性能。缓存实现的原理是从数据库中查出来的对象不删除,而是将其存储在缓存中,当我们再次查询查询同样的对象时,就直接调用缓存中的对象,不再向数据库执行select,减少了数据库的使用频率,从而提高了数据库的性能。
Mybatis中有一级缓存和二级缓存
一级缓存的作用域是一个sqlsession对象,第一次查询数据时会保存到sqlsession对象中,第二次如果查询相同的数据,则直接从sqlsession获取,直接获取的前提是这期间这个对象中的数据没有改变,即增删改操作;反之,若有改变,则会自动清除sqlsession缓存,重新进行查询,这并不代表我们关闭了sqlsession。
消除sqlsession缓存的方式(清除缓存并不代表着关闭sqlsession):
1.存储期间数据发生改变,自动清除缓存;
2.手动清除:sqlsession.clearCache();
sqlsession关闭时会清除缓存。
二级缓存是多个sqlsession共享的,是sqlsession factory 级别的,根据 mapper 的 namespace 划分区域 的,相同 namespace 的 mapper 查询的数据缓存在同一个区域,如果使用 mapper 代理方法每个 mapper 的 namespace 都不同,此时可以理解为二级缓 存区域是根据 mapper 划分。
每次查询会先从缓存区域查找,如果找不到则从数据库查询,并将查询到数据写 入缓存。Mybatis 内部存储缓存使用一个 HashMap,key 为 hashCode+sqlId+Sql 语句。value 为从查询出来映射生成的 java 对象。
sqlSession 执行 insert、update、delete 等操作 commit 提交后会清空缓存区域,防止脏读数据。
1.在全局配置文件中的<settings>目录下启用二级缓存,
如下代码所示,当 cacheEnabled 设置为 true 时启用二级缓存,设置为 false 时禁用二级缓存。
<setting name="cacheEnabled" value="true"/>
2、让我们的model包中的各个类(admin,student,grade)都实现序列化接口 Java.io. Serializable。
3、配置映射文件,在 Mappers 各个映射文件中添加<cache />,表示此 mapper 开启二级缓存。 当 SqlSeesion 关闭时,会将数据存入到二级缓存.
注:cache会有一些属性,例如:
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>这个更高级的配置创建了一个 FIFO 缓存,每隔 60 秒刷新,最多可以存储结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此对它们进行修改可能会在不同线程中的调用者产生冲突。
eviction中属性可用清除策略有:
LRU – 最近最少使用:移除最长时间不被使用的对象。FIFO – 先进先出:按对象进入缓存的顺序来移除它们。SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象。WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。默认的清除策略是 LRU。
到此这篇关于Mybatis动态sql的文章就介绍到这了,更多相关Mybatis动态sql内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Mybatis动态sql超详细讲解
本文链接: https://lsjlt.com/news/211357.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0