Python 官方文档:入门教程 => 点击学习
目录前言发送请求解析数据总结前言 我们知道在这个互联网时代,评论已经在我们的生活到处可见,评论区里面的信息是一个非常有趣和有争议的地方。我们今天,就来获取某技术平台的评论,和大家分享
我们知道在这个互联网时代,评论已经在我们的生活到处可见,评论区里面的信息是一个非常有趣和有争议的地方。我们今天,就来获取某技术平台的评论,和大家分享一下,我获取数据的过程,也是一个尝试的过程。
我们首先,确定我们要获取哪一个文章下面的评论区。我们先使用开发者工具,定位到我们要的数据。

我们通过数据抓取,我们发现,这个平台的评论区数据,放在了一个叫getlist数据包里面了。
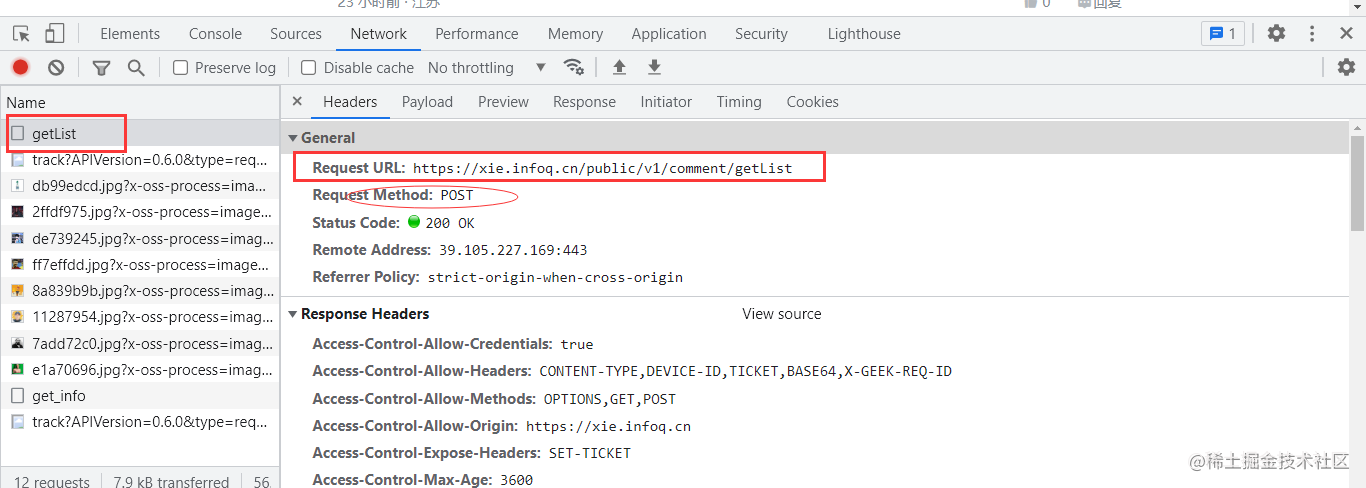
我们就不难明白,我们只要请求这个url,在传一个关于文章的参数,我们就能获取到我们想要的数据。而且,我们发现,这个是post请求。我们先按正常思路写代码。
import requests
url = 'https://xie.infoq.cn/public/v1/comment/getList'
headers = {
'User-Agent': 'Mozilla/5.0 (windows NT 10.0; Win64; x64) AppleWEBKit/537.36 (Khtml, like Gecko) Chrome/111.0.0.0 Safari/537.36',
}
res = requests.post(url,headers=headers)
print(res)我们发现返回了一个<Response [451]>的值,我们可能就是少穿了参数,我们接下来,把参数加上试试。
data = {
'id': "594899140323389440",
'score': '1682043841339',# 1681968121323
'size': '100',
}我们发现还是不行,所以,我们想到了,这个要加一个防盗链。我们把相应的参数传进去,我们再来看看效果。
headers ={
'Host': 'xie.infoq.cn',
'Origin': 'Https://xie.infoq.cn',
'Referer': 'https://xie.infoq.cn/article/a5f16dffb45139cba72691c29',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36',
}
res = requests.post(url,data = data,headers=headers)
我们发现虽然返回了<Response [200]>,但是,我们还是拿不到数据,我们看看服务器给我们返回了什么样子的数值。
{"code":-1,"data":{},"error":{"code":-2005,"msg":"ID不能为空"},"extra":{"cost":0.000170465,"request-id":"7c1dc236c95aceb9e56da271b056be88@2@infoq"}}
它提示我们"msg":"ID不能为空",说明我们data传入传错了。
不难看出,就是我们的文章id没有传进去,可能是我们传递的参数方式错了,我们这里要注意,要用JSON格式传参。正确的请求方式如下:
res = requests.post(url,json = data,headers=headers)我们发现,就可以获取到了数据,在这个过程,我们不断的尝试,最后,也拿到了我们想要的数据,我们会不会有一些成就感。我们看看获取到了什么样子的数据吧。

拿到了,这样的数据,大家就不难拿到我们要的数据,直接字典取值就好了,今天,我们用了大篇幅的段落,来解释我们是如何获取数据的。
我们接下来就可以解析数据了,代码很简单。我这里直接获取评论了,不获取评论者了,原理是一样的,大家感兴趣的可以自己去试试。
datas = res.json()['data']['list']
for contents in datas:
content = contents['content']
print(content)这段代码将从 res.json()['data']['list'] 中获取数据,并将其存储在 datas 变量中。然后,它使用一个 for 循环遍历 datas 中的每个元素,并将每个元素的 content 属性存储在 content 变量中。最后,它打印出每个元素的 content 属性。
我们直接看效果,这个很简单的。
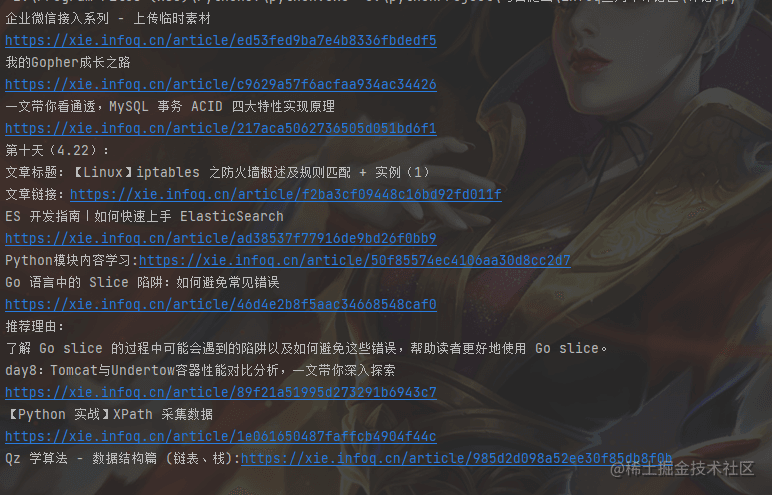
到此这篇关于python采集某评论区内容的实现示例的文章就介绍到这了,更多相关Python采集某评论区内容内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python采集某评论区内容的实现示例
本文链接: https://lsjlt.com/news/211089.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0