Python 官方文档:入门教程 => 点击学习
目录java对字符串进行utf-8编码java按照字节截取字符串-utf-8总结java对字符串进行utf-8编码 我们在调用第三方 api 时,常常会被要求用到路径变量,而路径变量
我们在调用第三方 api 时,常常会被要求用到路径变量,而路径变量一般都是 utf-8 编码的,因此需要对传入的字符串参数进行 utf-8 编码处理。
本文提供一种使用 URLEncoder 库进行编码的方式。
废话少说,上代码。
// 使用 URLEncoder 库对字符串进行 utf-8 编码
import java.net.URLEncoder;
public String encodePathVariable(String pathVariable) {
String ret = "default";
try {
ret = URLEncoder.encode(pathVariable, "utf-8");
System.out.println(pathVariable + " : " + ret);
}catch(Exception e) {
System.out.println(e);
}
return ret;
}如何按照utf-8的字节截取字符串呢?
utf-8,中文一个汉字是三个字节,一个字母或特殊符号是1个字节。
String类没有提供按字节截取字符串的方法,
StringUtil提供了截取的方法,但是默认是8858-1的,而且不能指定编码格式

但是给了我们思路,我们就将这段代码粘贴出来,将后面的编码格式给改成utf-8的

建个测试方法测试下
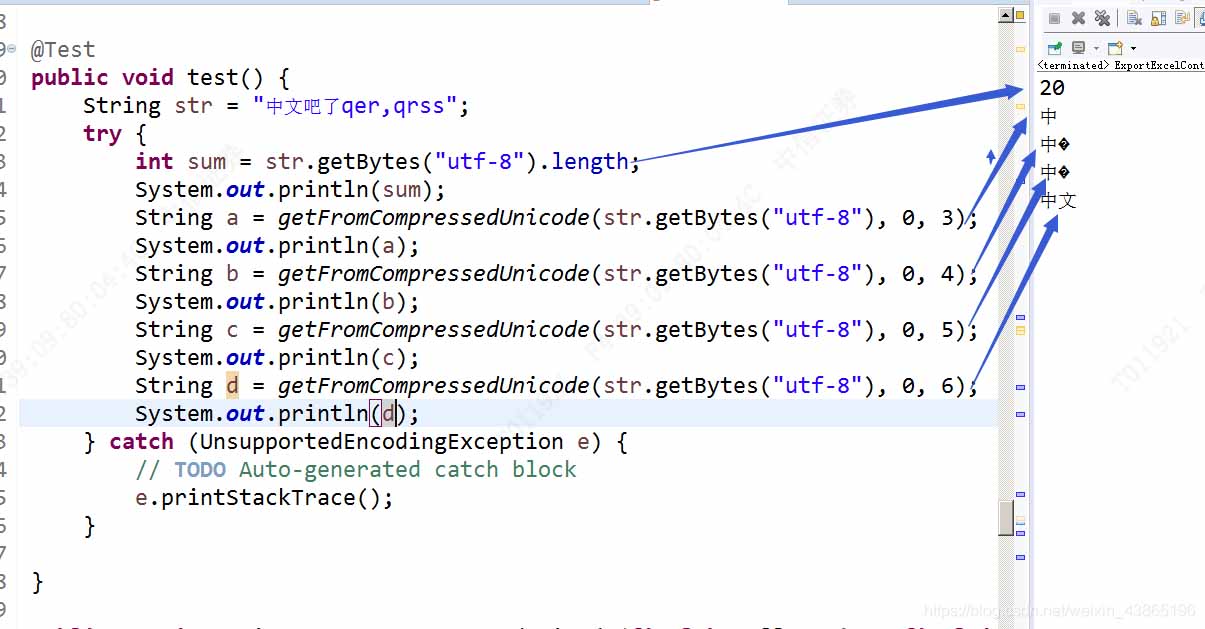
还是有些问题,截取3个字节时,正好把中字截取出来了,4个字节时有乱码,5个字节时,还有乱码,6个字节时,打印了两个字节,正好两个中文汉字。也就是说,本身是三个字节的文字,我们只取了它的1个字节,所以识别不出来出现了乱码!
经过反复测试,乱码就是�这种符号,别的符号没测出来,应该也没啥别的符号,我们就将这种符号截取掉就行了。
最后测试的代码

乱码没有了,而且准确率还高,因为字符串的情况挺复杂的,什么都有,文字,标点,特殊符号,穿插其中,字节也不一样,网上看了很多例子,都是他们自己编写的算法啥的,用了之后,错误率挺高的。
public static String getFromCompressedUnicode(String string,int offset,int len) throws UnsupportedEncodeingException{
byte[] bytes = string.getBytes("utf-8");
int len_to_use = Math.min(len,bytes.length - offset);
return new String(bytes,offset,len_to_use,"utf-8").replaceAll("�","")
}
以上为个人经验,希望能给大家一个参考,也希望大家多多支持编程网。
--结束END--
本文标题: Java中如何对字符串进行utf-8编码
本文链接: https://lsjlt.com/news/209134.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0