1. 在主机Macbook上设置HOST 前文书已经把虚拟机的静态IP地址设置好,以后可以通过ip地址登录了。不过为了方便,还是设置一下,首先在Mac下修改hosts文件,这样在ssh时就不用输入ip地址了。 sud
1. 在主机Macbook上设置HOST
前文书已经把虚拟机的静态IP地址设置好,以后可以通过ip地址登录了。不过为了方便,还是设置一下,首先在Mac下修改hosts文件,这样在ssh时就不用输入ip地址了。
sudo vim /etc/hosts
或者
sudo vim /private/etc/hosts
这两个文件其实是一个,是通过link做的链接。注意要加上sudo, 以管理员运行,否则不能存盘。
##
# Host Database
#
# localhost is used to configure the loopback interface
# when the system is booting. Do not change this entry.
##
127.0.0.1 localhost
255.255.255.255 broadcasthost
::1 localhost
50.116.33.29 sublime.wbond.net
127.0.0.1 windows10.microdone.cn
# Added by Docker Desktop
# To allow the same kube context to work on the host and the container:
127.0.0.1 kubernetes.docker.internal
192.168.56.100 hadoop100
192.168.56.101 hadoop101
192.168.56.102 hadoop102
192.168.56.103 hadoop103
192.168.56.104 hadoop104
# End of section2. 复制虚拟机
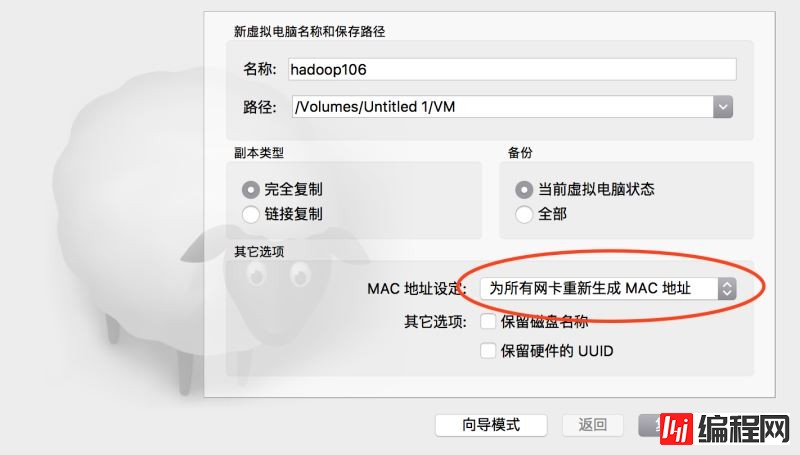
然后我们需要由上次配好的这一台虚拟机,复制出来多台,以便形成一个集群。首先关闭虚拟,在上面点右键,选复制,出现如下对话框,我选择把所有网卡都重新生成Mac地址,以便模拟完全不同的计算器环境。
3. 修改每一台的HOST, IP地址
复制完毕后,记得登录到虚拟机,按照前面提到的方法修改一下静态IP地址,免得IP地址冲突。
vi /etc/sysconfig/network-scripts/ifcfg-enp0s3
vi /etc/sysconfig/network-scripts/ifcfg-enp0s8另外,最好也在每台linux 虚拟机里也设置一下HOSTNAME,以便这些虚拟机之前相互通讯时也可以使用hostname。需要依次把几台机器的hostname都设置好。
[root@hadoop101 ~]# hostnamectl set-hostname hadoop107
[root@hadoop101 ~]# hostname
hadoop1074. xcall让服务器集群同时运行命令
因为我们同时有好几台机器,如果挨个挨个的登录上去操作,难免麻烦,可以写个shell脚本,以后从其中一台发起命令,让所有机器都执行就方便多了。下面是个例子。 我有hadopp100,hadopp101、hadopp102、hadopp103、hadopp104这个五台虚拟机。我希望以hadopp100为堡垒,统一控制所有其他的机器。 在/user/local/bin 下创建一个xcall的文件,内容如下:
touch /user/local/bin/xcall
chmod +x /user/local/bin/xcall
vi/user/local/bin/xcall
#!/bin/bash
pcount=$#
if((pcount==0));then
echo no args;
exit;
fi
echo ---------running at localhost--------
$@
for((host=101;host<=104;host++));do
echo ---------running at hadoop$host-------
ssh hadoop$host $@
done
~比如我用这个xcall脚本在所有机器上调用pwd名称,查看当前目录,会依次提示输入密码后执行。
[root@hadoop100 ~]# xcall pwd
---------running at localhost--------
/root
---------running at hadoop101-------
root@hadoop101's passWord:
/root
---------running at hadoop102-------
root@hadoop102's password:
/root
---------running at hadoop103-------
root@hadoop103's password:
/root
---------running at hadoop104-------
root@hadoop104's password:
/root
[root@hadoop100 ~]#5. scp与rsync
然后我们说一下 scp这个工具。 scp可以在linux间远程拷贝数据。如果要拷贝整个目录,加 -r 就可以了。
[root@hadoop100 ~]# ls
anaconda-ks.cfg
[root@hadoop100 ~]# scp anaconda-ks.cfg hadoop104:/root/
root@hadoop104's password:
anaconda-ks.cfg 100% 1233 61.1KB/s 00:00
[root@hadoop100 ~]#另外还可以用rsync, scp是不管目标机上情况如何,都要拷贝以便。 rsync是先对比一下,有变化的再拷贝。如果要远程拷贝的东西比较大,用rsync更快一些。 不如rsync在Centos上没有默认安装,需要首先安装一下。在之前的文章中,我们的虚拟机已经可以联网了,所以在线安装就可以了。
[root@hadoop100 ~]# xcall sudo yum install -y rsync比如,把hadoop100机器上的java sdk同步到102上去:
[root@hadoop100 /]# rsync -r /opt/modules/jdk1.8.0_121/ hadoop102:/opt/modules/jdk1.8.0_121/好了,到现在基本的工具和集群环境搭建起来了,后面就可以开始hadoop的学习了。
总结
以上所述是小编给大家介绍的使用VirtualBox模拟Linux集群的方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
--结束END--
本文标题: 使用VirtualBox模拟Linux集群的方法
本文链接: https://lsjlt.com/news/20597.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0