Python 官方文档:入门教程 => 点击学习
前言今天把最近的一个应用做好了,测试了一下运行没有问题,剩下的就是检验一下结果如何.从光谱到Lab值通常使用matlab中的roo2lab(),不过经过我最近的测试发现转换的结果并不理想,而且这个转化的代码也不是我写的所以另寻他法,找到了下

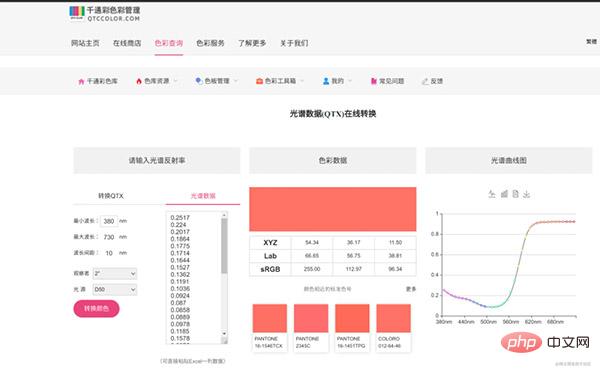
今天把最近的一个应用做好了,测试了一下运行没有问题,剩下的就是检验一下结果如何.从光谱到Lab值通常使用matlab中的roo2lab(),不过经过我最近的测试发现转换的结果并不理想,而且这个转化的代码也不是我写的所以另寻他法,找到了下面这个网页。
动手
有了这个网页,很简单就想到去解析.然后很快找到了这个api,可以看到用post提交表单请求就可以返回结果。
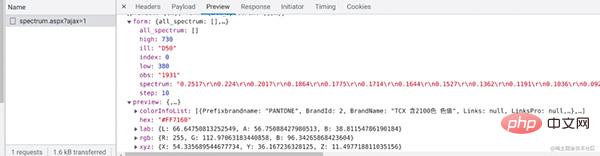
于是一番操作,修改fORM表单,构造传入的spectrum,但是最终请求得到的却是一个页面,并不是想要的JSON.然后许久没写爬虫的我直接恼火,想到自动化工具模拟操作.可是selenium很难用而且还得去找浏览器新版本的驱动,随后直接搜索一番,发现了这个神器—playwright。
首先老规矩去它的首页看看教程
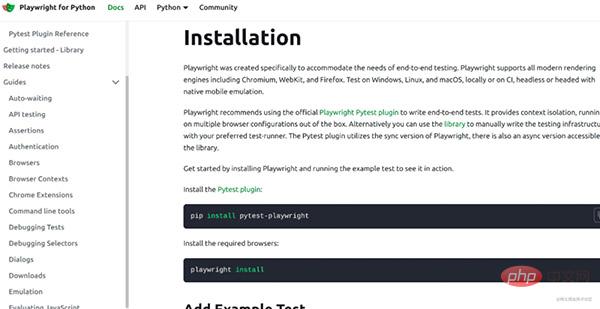
接着安装一下playwright以及浏览器的驱动。
pip install pytest-playwright
playwright install第二步的时候很慢,所以我只等他下载好了chrome和FFmpeg直接就ctrl+c停止了,毕竟我也用不着其他的浏览器驱动。
然后稍微浏览一下这个文档功能非常丰富,不过我用到的功能也不多,接下来的使用才是真正适合我们懒人的。
python -m playwright codegen xxx.com其中xxx.com就是我们的目标网址,运行后会创建一个熟悉的自动化页面,然后我们就进行一些我们想要的操作,比如设置开始的最小波长为400nm,然后观察以及光源改为D65/10.一系列操作后会看到对应的代码已经生成好了。
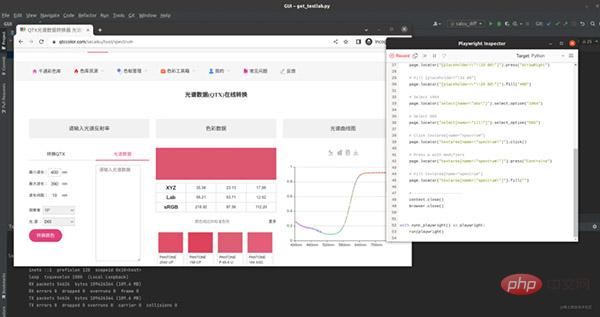
至今为止我还没有写一行代码,不过构造输入的光谱还是得自己来的。
把这一段代码复制下来,然后自己写构造输入的函数(就几行),然后通过选择器(直接左键元素复制xpath)得到lab值,这样目标就搞定了。
整体代码如下:
import time
from playwright.sync_api import Playwright, sync_playwright, expect
import numpy as np
data_test=np.loadtxt('./dist/1_res.csv',delimiter=',')
def get_str(arr):
arr_str=""
for i in arr:
arr_str+=str(format(i,".2f"))+"rn"
return arr_str
labs=[]
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
# Open new page
page = context.new_page()
# Go to https://www.qtccolor.com/secaiku/tool/spectrum
page.goto("https://www.qtccolor.com/secaiku/tool/spectrum")
# Click div[role="tab"]:has-text("光谱数据")
page.locator("div[role="tab"]:has-text("光谱数据")").click(
# Click text=最小波长:nm
page.locator("text=最小波长:nm").click()
# Fill [placeholder="33 80"]
page.locator("[placeholder="\33 80"]").fill("400")
# Select 1964
page.locator("select[name="obs"]").select_option("1964")
# Select D65
page.locator("select[name="ill"]").select_option("D65")
# Fill textarea[name="spectrum"]
for i in range(len(data_test)):
inputs=get_str(data_test[i,:])
# Click textarea[name="spectrum"]
page.locator("textarea[name="spectrum"]").click()
page.locator("textarea[name="spectrum"]").press("Control+a")
page.locator("textarea[name="spectrum"]").fill(inputs)
# Click button:has-text("转换颜色")
page.locator("button:has-text("转换颜色")").click()
time.sleep(1)
# Click text=Lab0.000.000.00 >> td >> nth=1
L=float(page.locator('xpath=//*[@]/div[1]/div/div[2]/table/tbody/tr[2]/td[2]').inner_text())
# Click text=Lab0.000.000.00 >> td >> nth=2
a=float(page.locator('xpath=//*[@]/div[1]/div/div[2]/table/tbody/tr[2]/td[3]').inner_text())
# Click text=Lab0.000.000.00 >> td >> nth=3
b=float(page.locator('xpath=//*[@]/div[1]/div/div[2]/table/tbody/tr[2]/td[4]').inner_text())
print(L,a,b)
labs.append([L,a,b])
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
np.savetxt('./1_lab_res.csv',labs,delimiter=",")可以说从安装到实现就几分钟,而且特别容易上手,我第一次用也一下就能实现效果。
剩下的就是简单的写个函数计算色差啥的就没难度了。
大厂出品果然不同,使用它在不考虑运行效率(有异步但是我懒得看了)的情况下可以轻松实现复杂操作,懒人最爱!
--结束END--
本文标题: 一款懒人必备的Python爬虫神器
本文链接: https://lsjlt.com/news/205355.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0