Python 官方文档:入门教程 => 点击学习
目录1. FilePathOrBuffer2. sep3. delim_whitespace(不常用)4. header 和 names5. index_col6. usecols7
使用pandas进行数据读取,最常读取的数据格式如下:
| NO | 数据类型 | 说明 | 使用方法 |
| 1 | csv, tsv, txt | 可以读取纯文本文件 | pd.read_csv |
| 2 | excel | 可以读取.xls .xlsx 文件 | pd.read_excel |
| 3 | Mysql | 读取关系型数据库 | pd.read_sql |
本文主要介绍pd.read_csv() 的用法:
pd.read_csv
pandas对纯文本的读取提供了非常强力的支持,参数有四五十个。这些参数中,有的很容易被忽略,但是在实际工作中却用处很大。pd.read_csv() 的格式如下:
read_csv(
reader: FilePathOrBuffer, *,
sep: str = ...,
delimiter: str | None = ...,
header: int | Sequence[int] | str = ...,
names: Sequence[str] | None = ...,
index_col: int | str | Sequence | Literal[False] | None = ...,
usecols: int | str | Sequence | None = ...,
squeeze: bool = ...,
prefix: str | None = ...,
mangle_dupe_cols: bool = ...,
dtype: str | Mapping[str, Any] | None = ...,
engine: str | None = ...,
converters: Mapping[int | str, (*args, **kwargs) -> Any] | None = ...,
true_values: Sequence[Scalar] | None = ...,
false_values: Sequence[Scalar] | None = ...,
skipinitialspace: bool = ...,
skiprows: Sequence | int | (*args, **kwargs) -> Any | None = ...,
skipfooter: int = ..., nrows: int | None = ..., na_values=...,
keep_default_na: bool = ..., na_filter: bool = ...,
verbose: bool = ..., skip_blank_lines: bool = ...,
parse_dates: bool | List[int] | List[str] = ...,
infer_datetime_format: bool = ...,
keep_date_col: bool = ...,
date_parser: (*args, **kwargs) -> Any | None = ...,
dayfirst: bool = ..., cache_dates: bool = ...,
iterator: Literal[True],
chunksize: int | None = ...,
compression: str | None = ...,
thousands: str | None = ...,
decimal: str | None = ...,
lineterminator: str | None = ...,
quotechar: str = ...,
quoting: int = ...,
doublequote: bool = ...,
escapechar: str | None = ...,
comment: str | None = ...,
encoding: str | None = ...,
dialect: str | None = ...,
error_bad_lines: bool = ...,
warn_bad_lines: bool = ...,
delim_whitespace: bool = ...,
low_memory: bool = ...,
memory_map: bool = ...,
float_precision: str | None = ...)
可以是文件路径,可以是网页上的文件,也可以是文件对象,实例如下:
# 文件路径读取
file_path=r"E:\vscode\2_numpy_pandas\pandas\Game_Data.csv"
f_df = pd.read_csv(file_path,sep=",|:|;",engine="python",header=0,encoding='gbk')
print(f_df)
# 网页上的文件读取
f_df = pd.read_csv("Http://localhost/data.csv")
# 文件对象读取
f = open(r"E:\VSCODE\2_numpy_pandas\pandas\Game_Data.csv", encoding="gbk")
f_df = pd.read_csv(f)
读取csv文件时指定的分隔符,默认为逗号。注意:“csv文件的分隔符” 和 “我们读取csv文件时指定的分隔符” 一定要一致。多个分隔符时,应该使用 | 将不同的分隔符隔开;例如:
f_df = pd.read_csv(file_path,sep=":|;",engine="Python",header=0)所有的空白字符,都可以用此来作为间隔,该值默认为False, 若我们将其更改为 True 则所有的空白字符:空格,\t, \n 等都会被当做分隔符;和sep功能相似;
这两个功能相辅相成,header 用来指定列名,例如header =0,则指定第一行为列名;若header =1 则指定第二行为列名;有时,我们的数据里没有列名,只有数据,这时候就需要names=[], 来指定列名;详细说明如下:
csv文件有表头并且是第一行,那么names和header都无需指定;csv文件有表头、但表头不是第一行,可能从下面几行开始才是真正的表头和数据,这个时候指定header即可;csv文件没有表头,全部是纯数据,那么我们可以通过names手动生成表头;csv文件有表头、但是这个表头你不想用,这个时候同时指定names和header。先用header选出表头和数据,然后再用names将表头替换掉,其实就等价于将数据读取进来之后再对列名进行rename;
举例如下:
names 没有被赋值,header 也没赋值:
file_path=r"E:\VSCODE\2_numpy_pandas\pandas\Game_Data.csv"
df=pd.read_csv(file_path,sep=",|:|;",engine="python",header=0,encoding='gbk')
print(df)
# 我们说这种情况下,header为变成0,即选取文件的第一行作为表头
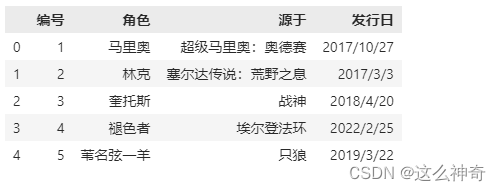
names 没有被赋值,header 被赋值:
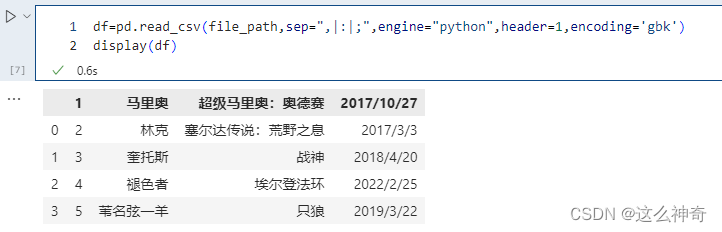
pd.read_csv(file_path,sep=",|:|;",engine="python",header=1,encoding='gbk')
# 不指定names,指定header为1,则选取第二行当做表头,第二行下面的是数据
names 被赋值,header 没有被赋值
pd.read_csv(file_path,sep=",|:|;",engine="python",encoding='gbk',names=["编号", "英雄", "游戏", "发行日期"])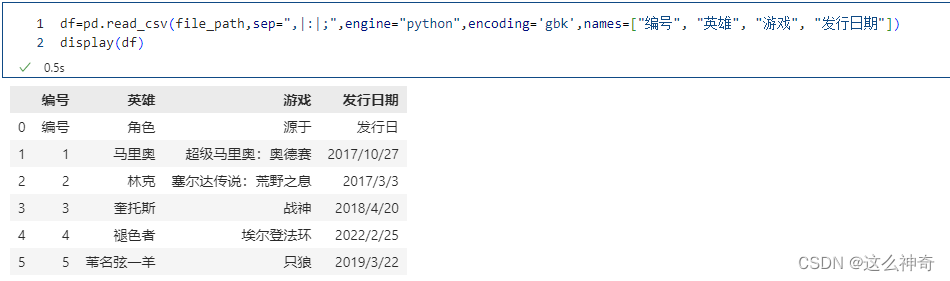
names适用于没有表头的情况,指定names没有指定header,那么header相当于None。一般来说,读取文件会有一个表头的,一般是第一行,但是有的文件只是数据而没有表头,那么这个时候我们就可以通过names手动指定、或者生成表头,而文件里面的数据则全部是内容。所以这里"编号", “角色”, “源于”, “发行日” 也当成是一条记录了,本来它是表头的,但是我们指定了names,所以它就变成数据了,表头是我们在names里面指定的
names和header都被赋值:
pd.read_csv(file_path,sep=",|:|;",engine="python",encoding='gbk',names=["编号", "英雄", "游戏", "发行日期"],header=0)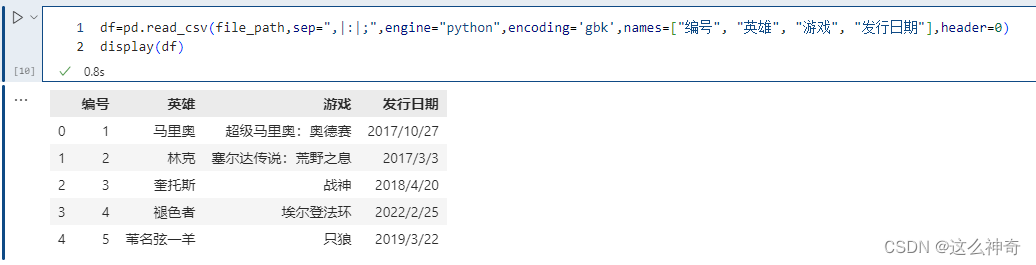
这个相当于先不看names,只看header,我们说header等于0代表什么呢?显然是把第一行当做表头,下面的当成数据,好了,然后再把表头用names给替换掉。
我们在读取文件之后,生成的 DataFrame 的索引默认是0 1 2 3…,我们当然可以 set_index,但是也可以在读取的时候就指定某个列为索引。
pd.read_csv(file_path,engine="python",encoding='gbk',header=0,index_col="角色")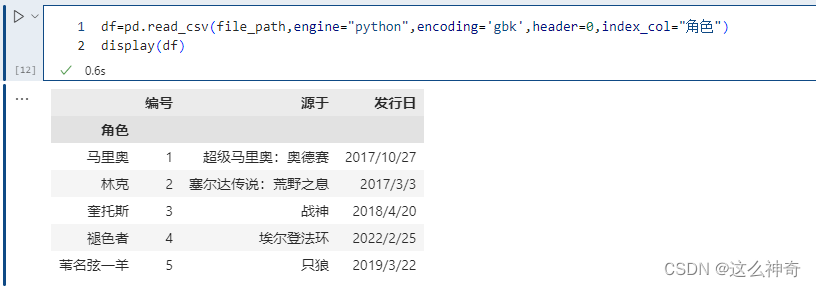
这里指定 “name” 作为索引,另外除了指定单个列,还可以指定多个列,比如 [“id”, “name”]。并且我们除了可以输入列的名字之外,还可以输入对应的索引。比如:“id”、“name”、“address”、“date” 对应的索引就分别是0、1、2、3。
如果列有很多,而我们不想要全部的列、而是只要指定的列就可以使用这个参数。
pd.read_csv(file_path,encoding='gbk',usecols=["角色", "发行日"])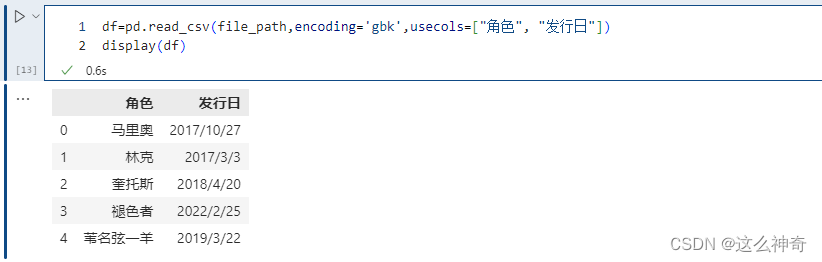
同 index_col 一样,除了指定列名,也可以通过索引来选择想要的列,比如:usecols=[1, 3] 也会选择 “角色” 和 “发行日” 两列,因为 “角色” 这一列对应的索引是 1、“发行日” 对应的索引是 3。
此外 use_cols 还有一个比较好玩的用法,就是接收一个函数,会依次将列名作为参数传递到函数中进行调用,如果返回值为真,则选择该列,不为真,则不选择。
# 选择列名的长度等于 3 的列,显然此时只会选择 发行日 这一列
pd.read_csv(file_path,encoding='gbk',usecols=lambda x:len(x)==3)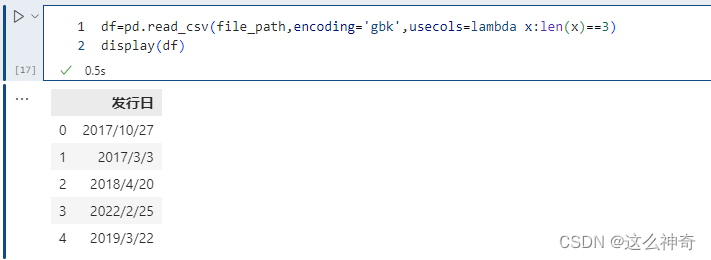
实际生产用的数据会很复杂,有时导入的数据会含有重名的列。参数 mangle_dupe_cols 默认为 True,重名的列导入后面多一个 .1。如果设置为 False,会抛出不支持的异常:
# ValueError: Setting mangle_dupe_cols=False is not supported yetprefix 参数,当导入的数据没有 header 时,设置此参数会自动加一个前缀。比如:
pd.read_csv(file_path,encoding='gbk',header=None,prefix="角色")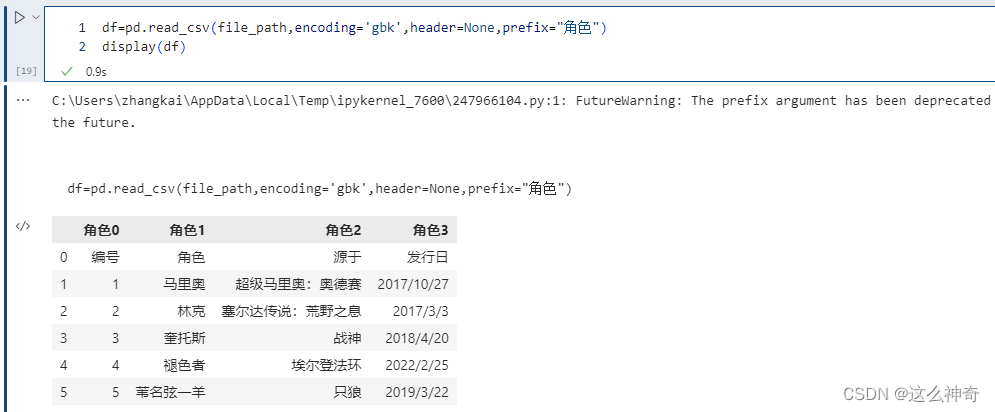
有时候,工作人员的id都是以0开头的,比如0100012521,这是一个字符串。但是在读取的时候解析成整型了,结果把开头的0给丢了。这个时候我们就可以通过dtype来指定某个列的类型,就是告诉pandas:你在解析的时候不要自以为是,直接按照老子指定的类型进行解析就可以了,我不要你觉得,我要我觉得。
df=pd.read_csv(file_path,encoding='gbk',dtype={"编号": str})df["编号"]=df["编号"]*4
pandas解析数据时用的引擎,pandas 目前的解析引擎提供两种:c、python,默认为 c,因为 c 引擎解析速度更快,但是特性没有 python 引擎全。如果使用 c 引擎没有的特性时,会自动退化为 python 引擎。
比如使用分隔符进行解析,如果指定分隔符不是单个字符、或者"\s+“,那么c引擎就无法解析了。我们知道如果分隔符为空白字符的话,那么可以指定delim_whitespace=True,但是也可以指定sep=r”\s+"。
df=pd.read_csv(file_path,encoding='gbk',dtype={"编号": str})
df["编号"]=df["编号"]*4
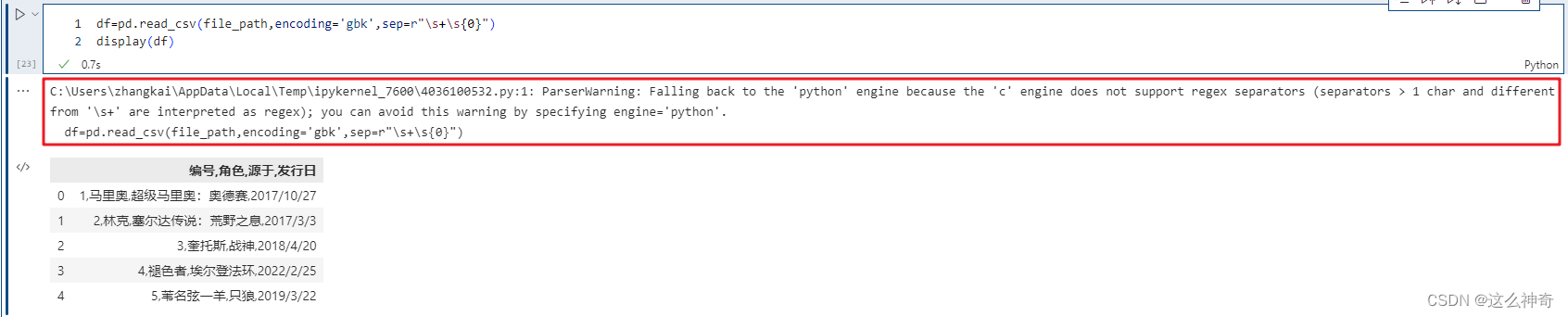
我们看到虽然自动退化,但是弹出了警告,这个时候需要手动的指定engine="python"来避免警告。这里面还用到了encoding参数,这个后面会说,因为引擎一旦退化,在windows上不指定会读出乱码。这里我们看到sep是可以支持正则的,但是说实话sep这个参数都会设置成单个字符,原因是读取的csv文件的分隔符是单个字符。
可以在读取的时候对列数据进行变换:
pd.read_csv(file_path,encoding='gbk', converters={<!--{C}%3C!%2D%2D%20%2D%2D%3E-->"编号": lambda x: int(x) + 10})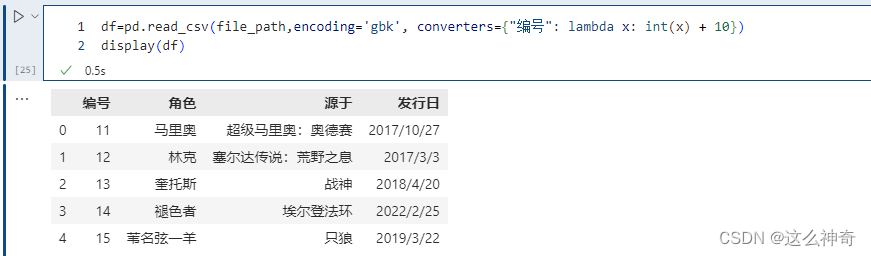
将id增加10,但是注意 int(x),在使用converters参数时,解析器默认所有列的类型为 str,所以需要显式类型转换。
指定哪些值应该被清洗为True,哪些值被清洗为False。
pd.read_csv(file_path,encoding='gbk',true_values=["林克","奎托斯","褪色者","苇名弦一羊"],false_values=["马里奥"])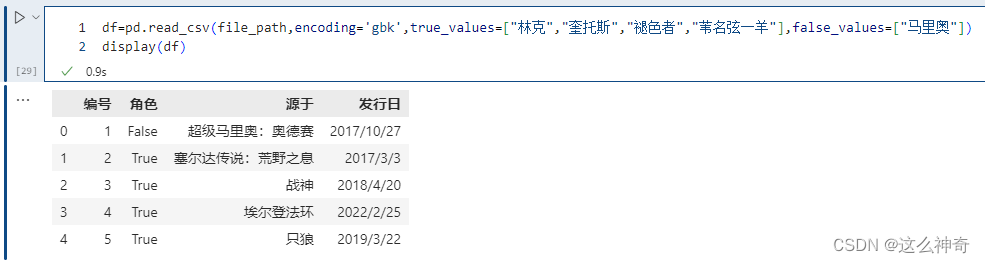
注意这里的替换规则,只有当某一列的数据全部出现在true_values + false_values里面,才会被替换。例如执行以下内容,不会发生变化;
pd.read_csv(file_path,encoding='gbk',true_values=["林克"],false_values=["马里奥"])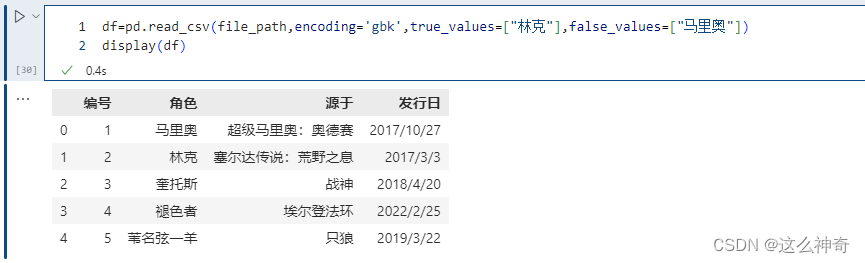
skiprows 表示过滤行,想过滤掉哪些行,就写在一个列表里面传递给skiprows即可。注意的是:这里是先过滤,然后再确定表头,比如:
pd.read_csv(file_path,encoding='gbk',skiprows=[0])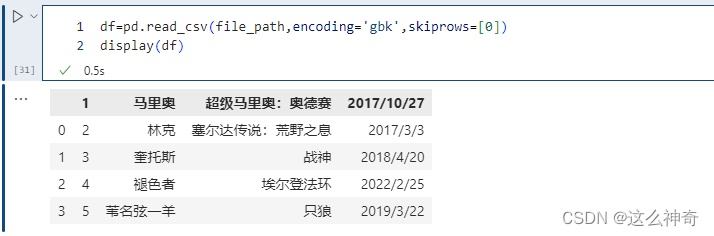
我们把第一行过滤掉了,但是第一行是表头,所以过滤掉之后,第二行就变成表头了。如果过滤掉第二行,那么只相当于少了一行数据,但是表头还是原来的第一行。
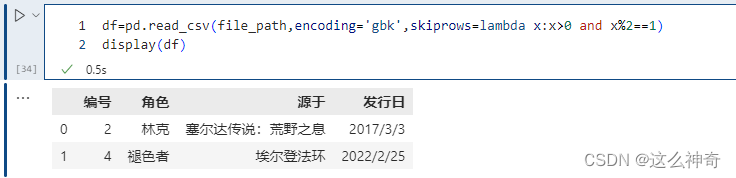
当然里面除了传入具体的数值,来表明要过滤掉哪些行,还可以传入一个函数。
pd.read_csv(file_path,encoding='gbk',skiprows=lambda x:x>0 and x%2==1)由于索引从0开始,凡是索引2等于1的记录都过滤掉。索引大于0,是为了保证表头不被过滤掉。
从文件末尾过滤行,解析引擎退化为 Python。这是因为 C 解析引擎没有这个特性。
pd.read_csv(file_path,encoding='gbk',skipfooter=2)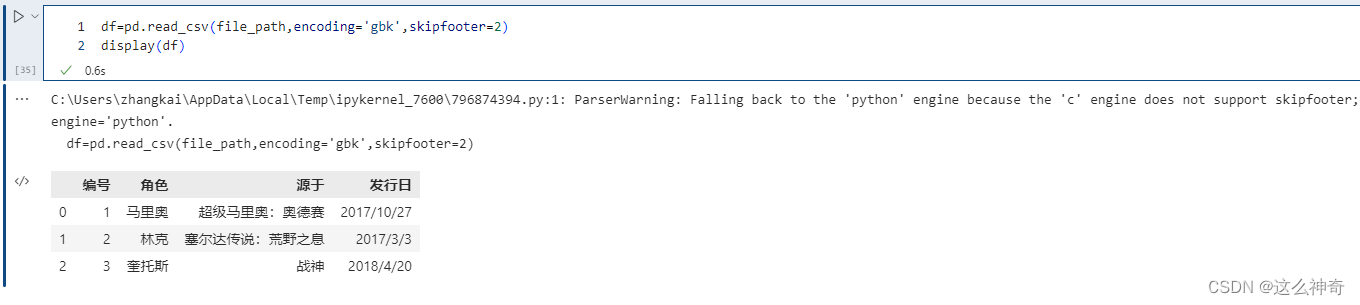
如果不想报以上的Warning, 可以将Engine 指定为Python, 如下:
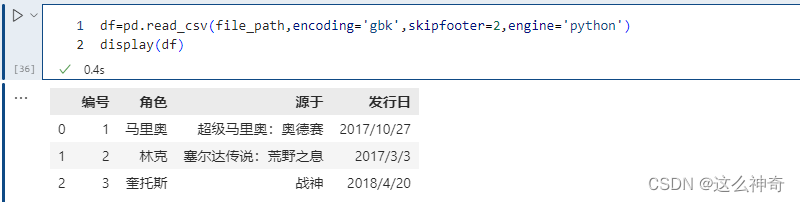
skipfooter接收整型,表示从结尾往上过滤掉指定数量的行,因为引擎退化为python,那么要手动指定engine=“python”,不然会警告。
nrows 参数设置一次性读入的文件行数,它在读入大文件时很有用,比如 16G 内存的PC无法容纳几百 G 的大文件。
pd.read_csv(file_path,encoding='gbk',nrows=4)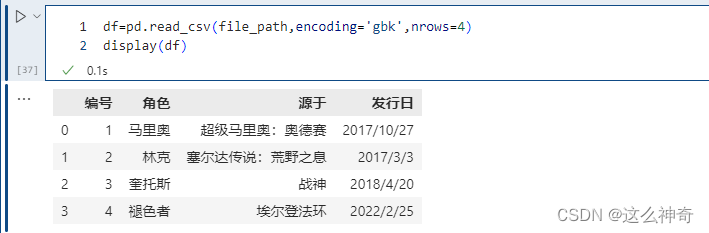
很多时候我们只是想看看大文件内部的字段长什么样子,所以这里通过nrows指定读取的行数。
na_values 参数可以配置哪些值需要处理成 NaN,这个是非常常用的。
pd.read_csv(file_path,encoding='gbk',na_values=['马里奥','战神'])
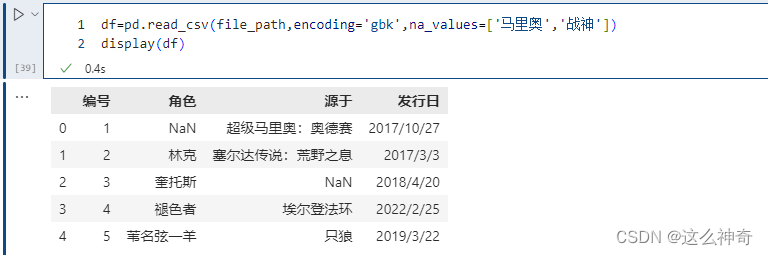
我们看到将 ‘马里奥’ 和 ‘战神’ 设置成了NaN,当然我们这里不同的列,里面包含的值都是不相同的。但如果两个列中包含相同的值,而我们只想将其中一个列的值换成NaN该怎么做呢?通过字典实现只对指定的列进行替换。以下的例子可以看到,战神并没有被替换成NaN, 因为在角色里没有这个值;/
pd.read_csv(file_path,encoding='gbk',na_values={<!--{C}%3C!%2D%2D%20%2D%2D%3E-->"角色":['马里奥','战神'],'编号':[2]})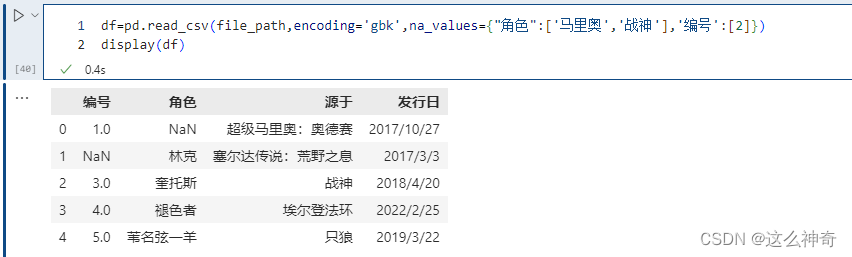
我们知道,通过 na_values 参数可以让 pandas 在读取 CSV 的时候将一些指定的值替换成空值,但除了 na_values 指定的值之外,还有一些默认的值也会在读取的时候被替换成空值,这些值有: “-1.#IND”、“1.#QNAN”、“1.#IND”、“-1.#QNAN”、“#N/A N/A”、“#N/A”、“N/A”、“NA”、“#NA”、“NULL”、“NaN”、“-NaN”、“nan”、“-nan”、“” 。尽管这些值在 CSV 中的表现形式是字符串,但是 pandas 在读取的时候会替换成空值(真正意义上的 NaN)。不过有些时候我们不希望这么做,比如有一个具有业务含义的字符串恰好就叫 “NA”,那么再将它替换成空值就不对了。
这个时候就可以将 keep_default_na 指定为 False,默认为 True,如果指定为 False,那么 pandas 在读取时就不会擅自将那些默认的值转成空值了,它们在 CSV 中长什么样,pandas 读取出来之后就还长什么样,即使单元格中啥也没有,那么得到的也是一个空字符串。但是注意,我们上面介绍的 na_values 参数则不受此影响,也就是说即便 keep_default_na 为 False,na_values 参数指定的值也依旧会被替换成空值。举个栗子,假设某个 CSV 中存在 “NULL”、“NA”、以及空字符串,那么默认情况下,它们都会被替换成空值。但 “NA” 是具有业务含义的,我们希望保留原样,而 “NULL” 和空字符串,我们还是希望 pandas 在读取的时候能够替换成空值,那么此时就可以在指定 keep_default_na 为 False 的同时,再指定 na_values 为 ["NULL", ""]
是否进行空值检测,默认为 True,如果指定为 False,那么 pandas 在读取 CSV 的时候不会进行任何空值的判断和检测,所有的值都会保留原样。因此,如果你能确保一个 CSV 肯定没有空值,则不妨指定 na_filter 为 False,因为避免了空值检测,可以提高大型文件的读取速度。另外,该参数会屏蔽 keep_default_na 和 na_values,也就是说,当 na_filter 为 False 的时候,这两个参数会失效。
从效果上来说,na_filter 为 False 等价于:不指定 na_values、以及将 keep_default_na 设为 False。
skip_blank_lines 默认为 True,表示过滤掉空行,如为 False 则解析为 NaN。
指定某些列为时间类型,这个参数一般搭配下面的date_parser使用。
是用来配合parse_dates参数的,因为有的列虽然是日期,但没办法直接转化,需要我们指定一个解析格式:
from datetime import datetime
pd.read_csv(file_path,encoding='gbk',parse_dates=['发行日'],date_parser=lambda x:datetime.strptime(x,'%Y/%m/%d'))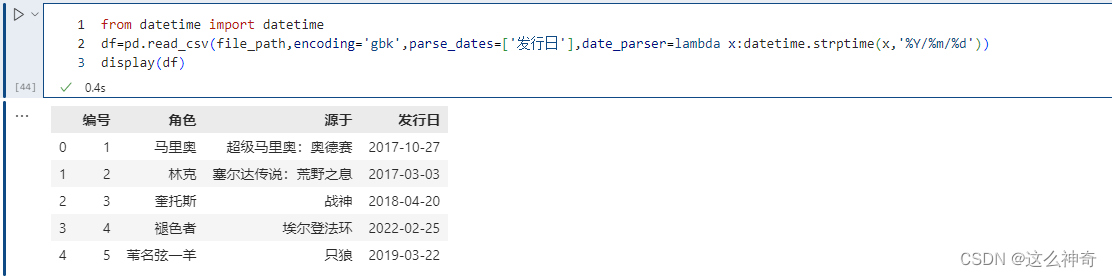
infer_datetime_format 参数默认为 False。如果设定为 True 并且 parse_dates 可用,那么 pandas 将尝试转换为日期类型,如果可以转换,转换方法并解析,在某些情况下会快 5~10 倍。
iterator 为 bool类型,默认为False。如果为True,那么返回一个 TextFileReader 对象,以便逐块处理文件。这个在文件很大、内存无法容纳所有数据文件时,可以分批读入,依次处理。
df=pd.read_csv(file_path,encoding='gbk',iterator=True)
display(df.get_chunk(2))
"""
编号 角色 源于 发行日
0 1 马里奥 超级马里奥:奥德赛 2017/10/27
1 2 林克 塞尔达传说:荒野之息 2017/3/3
"""
print(chunk.get_chunk(1))
"""
编号 角色 源于 发行日
2 3 奎托斯 战神 2018/4/20
"""
# 文件还剩下三行,但是我们指定读取10,那么也不会报错,不够指定的行数,那么有多少返回多少
print(chunk.get_chunk(10))
"""
编号 角色 源于 发行日
3 4 褪色者 埃尔登法环 2022/2/25
4 5 苇名弦一羊 只狼 2019/3/22
"""
try:
# 但是在读取完毕之后,再读的话就会报错了
chunk.get_chunk(5)
except StopIteration as e:
print("读取完毕")
# 读取完毕
chunksize 整型,默认为 None,设置文件块的大小。
chunk = pd.read_csv(file_path, sep="\t", chunksize=2)
# 还是返回一个类似于迭代器的对象
# 调用get_chunk,如果不指定行数,那么就是默认的chunksize
print(chunk.get_chunk())
"""
编号 角色 源于 发行日
0 1 马里奥 超级马里奥:奥德赛 2017/10/27
1 2 林克 塞尔达传说:荒野之息 2017/3/3
"""
# 但也可以指定
print(chunk.get_chunk(100))
"""
编号 角色 源于 发行日
2 3 奎托斯 战神 2018/4/20
3 4 褪色者 埃尔登法环 2022/2/25
4 5 苇名弦一羊 只狼 2019/3/22
"""
try:
chunk.get_chunk(5)
except StopIteration as e:
print("读取完毕")
# 读取完毕
compression 参数取值为 {‘infer’, ‘gzip’, ‘bz2’, ‘zip’, ‘xz’, None},默认 ‘infer’,这个参数直接支持我们使用磁盘上的压缩文件。
# 直接将上面的.csv添加到压缩文件,打包成game_data.zip
pd.read_csv('game_data.zip', compression="zip",encoding='gbk')千分位分割符,如 , 或者 .,默认为None。
encoding 指定字符集类型,通常指定为 ‘utf-8’。根据情况也可能是’ISO-8859-1’,本文中所有的encoding='gbk' ,主要原因为:我的数据是用Excel 保存成.CSV的,默认的编码格式为GBK;
如果一行包含过多的列,假设csv的数据有5列,但是某一行却有6个数据,显然数据有问题。那么默认情况下不会返回DataFrame,而是会报错。
我们在某一行中多加了一个数据,结果显示错误。因为girl.csv里面有5列,但是有一行却有6个数据,所以报错。
在小样本读取时,这个错误很快就能发现。但是如果样本比较大、并且由于数据集不可能那么干净,会很容易出现这种情况,那么该怎么办呢?而且这种情况下,Excel基本上是打不开这么大的文件的。这个时候我们就可以将error_bad_lines设置为False(默认为True),意思是遇到这种情况,直接把这一行给我扔掉。同时会设置 warn_bad_lines 设置为True,打印剔除的这行。
pd.read_csv(file_path,encoding='gbk',error_bad_lines=False, warn_bad_lines=True)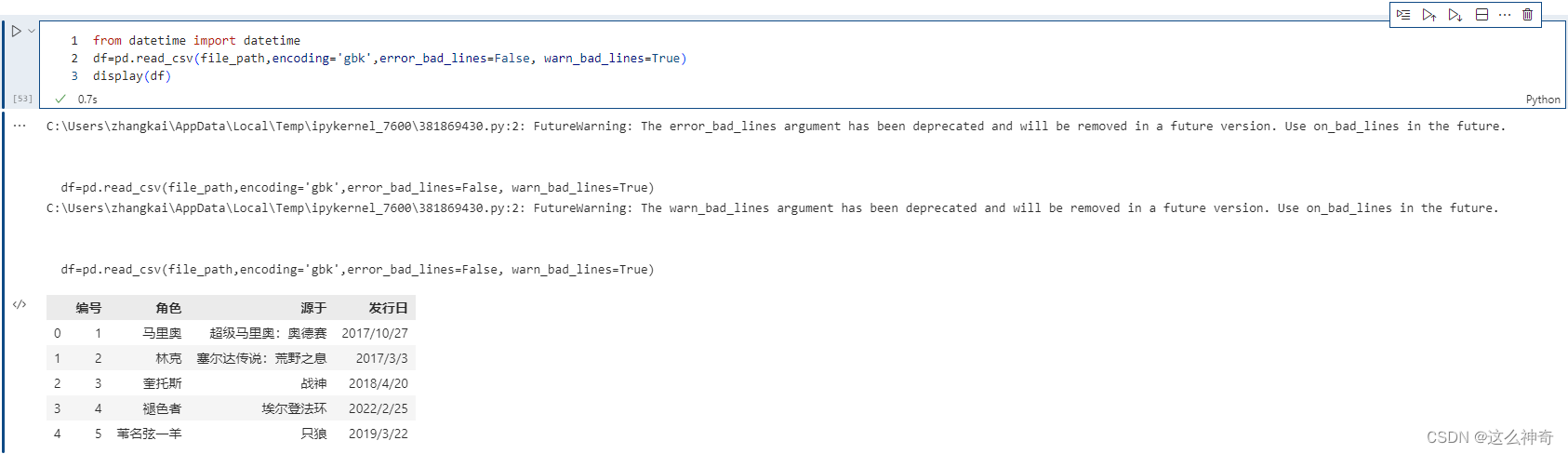
以上两参数只能在C解析引擎下使用。
以上就是针对Pandas的总结以及数据读取_pd.read_csv()的使用详解的详细内容,更多关于pandas总结的资料请关注编程网其它相关文章!
--结束END--
本文标题: 针对Pandas的总结以及数据读取_pd.read_csv()的使用详解
本文链接: https://lsjlt.com/news/200919.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0